决战西二旗|你真的懂快速排序?
Posted 后端技术指南针
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决战西二旗|你真的懂快速排序?相关的知识,希望对你有一定的参考价值。
学习不实战 就等于白看 学而后忘 忘而再学
这是个怪圈 思索良久 在一个充满雾霾的下午
本号决定推出【决战西二旗】系列文章
这个专题名有点土 不文雅 不响亮 不深沉所以要持续推送干货 之所谓 题名丑 内容凑
2019要过去了 作为Coder的你或遇人不淑迷茫徘徊 或如鱼得水扶摇直上
往者不可谏 来者犹可追 美好永远在前方
代码不一定可以改变世界格局但可以改变我们的生活质量
Let's Code A Better Life.
或许你会问 为啥不是决战五道口
决战中关村 决战望京 决战亦庄呢
那我只能告诉你 西二旗有坊间流传的中国互联网十字路口……
"中国互联网十字路口"街景图
"中国互联网十字路口"坐标图
看到这里 优秀的你和你的小伙伴们 是不是跃跃欲试 想去这个十字路口耍耍

然而现实是这样的:
有差距不要紧,聪明的脑袋好好学习 ,说不定明年就肉身翻到湾区了。树立了信心,那么废话少叙,开始主题,聊聊快速排序!
看似青铜实则王者
很多人提起快排和二分都觉得很容易的样子,但是让现场Code很多就翻车了,就算可以写出个递归版本的代码,但是对其中的复杂度分析、边界条件的考虑、非递归改造、代码优化等就无从下手,填鸭背诵基本上分分钟就被面试官摆平了。

那年初识快速排序
快速排序Quicksort又称划分交换排序partition-exchange sort,简称快排,一种排序算法。最早由东尼·霍尔(C. A. R. Hoare)教授在1960年左右提出,在平均状况下,排序n个项目要O(nlogn)次比较。
在最坏状况下则需要O(n^2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他算法更快,因为它的内部循环可以在大部分的架构上很有效率地达成。
快速排序的核心思想
在计算机科学中,分治法(Divide&Conquer)是建基于多项分支递归的一种很重要的算法范式,快速排序是分治思想在排序问题上的典型应用。
所谓分治思想D&C就是把一个较大规模的问题拆分为若干小规模且相似的问题。再对小规模问题进行求解,最终合并所有小问题的解,从而形成原来大规模问题的解。
字面上的解释是"分而治之",这个技巧是很多高效算法的基础,如排序算法(归并排序、快速排序)、傅立叶变换(快速傅立叶变换)。
分治法中最重要的部分是循环递归的过程,每一层递归有三个具体步骤:
分解:将原问题分解为若干个规模较小,相对独立,与原问题形式相同的子问题。
解决:若子问题规模较小且易于解决时,则直接解。否则,递归地解决各子问题。
合并:将各子问题的解合并为原问题的解。
快速排序的发明者
查尔斯·安东尼·理查德·霍尔爵士(Sir Charles Antony Richard Hoare缩写为C. A. R. Hoare,1934年1月11日-),昵称为东尼·霍尔(Tony Hoare),生于大英帝国锡兰可伦坡(今斯里兰卡),英国计算机科学家,图灵奖得主。
他设计了快速排序算法、霍尔逻辑、交谈循序程式。在操作系统中,他提出哲学家就餐问题,并发明用来作为同步程序的监视器(Monitors)以解决这个问题。他同时证明了监视器与信号标(Semaphore)在逻辑上是等价的。
1980年获颁图灵奖、1982年成为英国皇家学会院士、2000年因为他在计算机科学与教育方面的杰出贡献,获得英国王室颁赠爵士头衔、2011年获颁约翰·冯诺依曼奖,现为牛津大学荣誉教授,并在剑桥微软研究院担任研究员。

快速排序的基本过程
快速排序使用分治法来把一个序列分为小于基准值和大于基准值的两个子序列。
递归地排序两个子序列,直至最小的子序列长度为0或者1,整个递归过程结束,详细步骤为:
挑选基准值: 从数列中挑出一个元素称为基准pivot,选取基准值有数种具体方法,此选取方法对排序的时间性能有决定性影响。
基准值分割: 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面,与基准值相等的数可以到任何一边,在这个分割结束之后,对基准值的排序就已经完成。
递归子序列: 递归地将小于基准值元素的子序列和大于基准值元素的子序列排序,步骤同上两步骤,递归终止条件是序列大小是0或1,因为此时该数列显然已经有序。
快速排序的递归实现
版本一 C实现
1#include<stdio.h>
2
3int a[9]={5,1,9,6,7,11,3,8,4};
4
5void exchange(int *p,int *q){
6 int temp=*p;
7 *p=*q;
8 *q=temp;
9}
10
11int quicksort(int left,int right){
12 if(left>=right){
13 return 0;
14 }
15
16 int i,j,temp;
17 temp=a[left];
18 i=left;
19 j=right;
20
21 while(i!=j){
22 while(i<j&&a[j]>=temp){
23 j--;
24 }
25 exchange(&a[i],&a[j]);
26 while(i<j&&a[i]<=temp){
27 i++;
28 }
29 exchange(&a[i],&a[j]);
30 }
31 quicksort(i+1,right);
32 quicksort(left,i-1);
33
34}
35
36int main(){
37 quicksort(0,8);
38 for(int i=0;i<=8;i++){
39 printf("%d ",a[i]);
40 }
41}
版本二 C++实现
1#include<iostream>
2using namespace std;
3
4template <typename T>
5void quick_sort_recursive(T arr[], int start, int end) {
6 if (start >= end)
7 return;
8 T mid = arr[end];
9 int left = start, right = end - 1;
10 //整个范围内搜寻比枢纽值小或大的元素,然后左侧元素与右侧元素交换
11 while (left < right) {
12 //试图在左侧找到一个比枢纽元更大的元素
13 while (arr[left] < mid && left < right)
14 left++;
15 //试图在右侧找到一个比枢纽元更小的元素
16 while (arr[right] >= mid && left < right)
17 right--;
18 //交换元素
19 std::swap(arr[left], arr[right]);
20 }
21 //这一步很关键
22 if (arr[left] >= arr[end])
23 std::swap(arr[left], arr[end]);
24 else
25 left++;
26 quick_sort_recursive(arr, start, left - 1);
27 quick_sort_recursive(arr, left + 1, end);
28}
29
30//模板化
31template <typename T>
32void quick_sort(T arr[], int len) {
33 quick_sort_recursive(arr, 0, len - 1);
34}
35
36int main()
37{
38 int a[9]={5,1,9,6,7,11,3,8,4};
39 int len = sizeof(a)/sizeof(int);
40 quick_sort(a,len-1);
41 for(int i=0;i<len-1;i++)
42 cout<<a[i]<<endl;
43}两个版本均可正确运行,但代码有一点差异:
版本一 使用双指针交替从左(右)两边分别开始寻找大于基准值(小于基准值),然后与基准值交换,直到最后左右指针相遇。
版本二 使用双指针向中间集合,左指针遇到大于基准值时则停止,等待右指针,右指针遇到小于基准值时则停止,与左指针指向的元素交换,最后基准值放到合适位置。
过程说起来比较抽象,稳住别慌!灵魂画手大白会画图来演示这两个过程。

快速排序的递归演示
版本一递归代码的排序过程示意图:
以第一次递归循环为例:
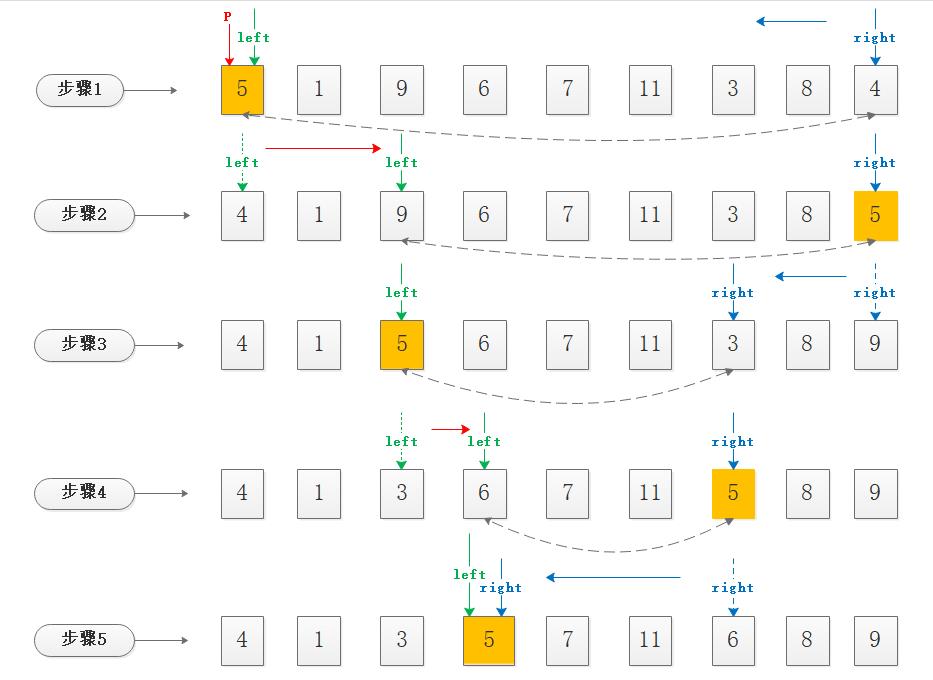
步骤1: 选择第一个元素为基准值pivot=a[left]=5,right指针指向尾部元素,此时先由right自右向左扫描直至遇到<5的元素,恰好right起步元素4<5,因此需要将4与5互换位置;
步骤2: 4与5互换位置之后,轮到left指针从左向右扫描,注意一下left的起步指针指向了由步骤1交换而来的4,新元素4不满足停止条件,因此left由绿色虚箭头4位置游走到元素9的位置,此时left找到9>5,因此将此时left和right指向的元素互换,也就是元素5和元素9互换位置;
步骤3: 互换之后right指针继续向左扫描,从蓝色虚箭头9位置游走到3的位置,此时right发现3<5,因此将此时left和right指向的元素互换,也就是元素3和元素5互换位置;
步骤4: 互换之后left指针继续向右扫描,从绿色虚箭头3位置游走到6的位置,此时left发现6>5,因此将此时left和right指向的元素互换,也就是元素6和元素5互换位置;
步骤5: 互换之后right指针继续向左扫描,从蓝色虚箭头6位置一直游走到与left指针相遇,此时二者均停留在了pivot=5的新位置上,且左右两边分成了两个相对于pivot值的子序列;
循环结束:至此出现了以5为基准值的左右子序列,接下来就是对两个子序列实施同样的递归步骤。
以第二次和第三次左子序列递归循环为例:
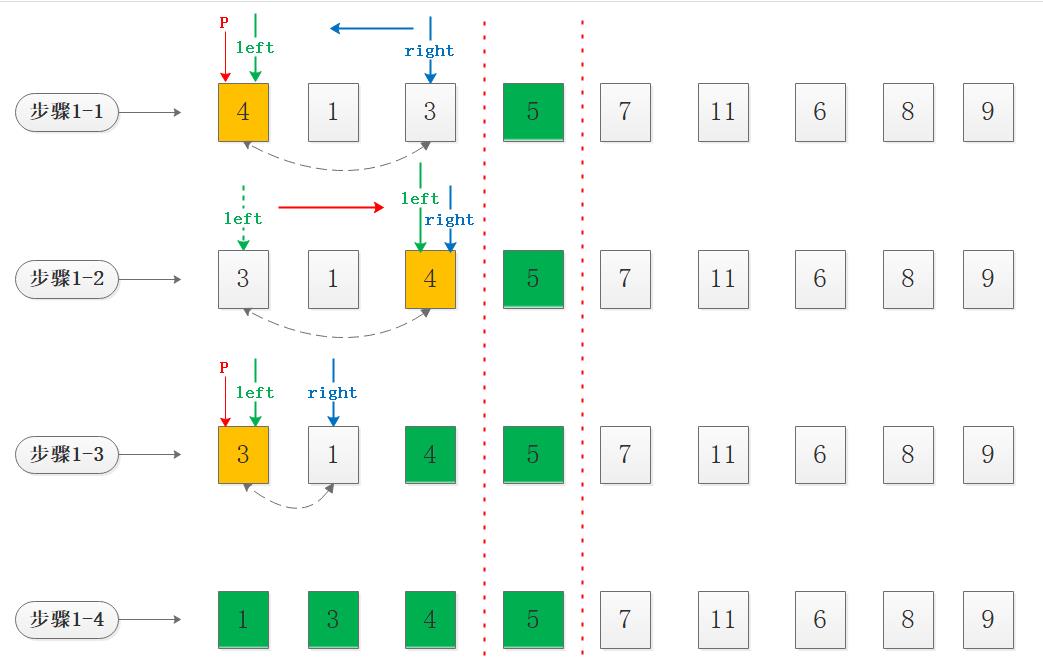
步骤1-1:选择第一个元素为基准值pivot=a[left]=4,right指针指向尾部元素,此时先由right指针向左扫描,恰好起步元素3<4,因此将3和4互换;
步骤1-2:互换之后left指针从元素3开始向右扫描,一直游走到与right指针相遇,此时本次循环停止,特别注意这种情况下可以看到基准值4只有左子序列,无右子序列,这种情况是一种退化,就像冒泡排序每次循环都将基准值放置到最后,因此效率将退化为冒泡的O(n^2);
步骤1-3:选择第一个元素为基准值pivot=a[left]=3,right指针指向尾部元素,此时先由right指针向左扫描,恰好起步元素1<3,因此将1和3互换;
步骤1-4:互换之后left指针从1开始向右扫描直到与right指针相遇,此时注意到pivot=3无右子序列且左子序列len=1,达到了递归循环的终止条件,此时可以认为由第一次循环产生的左子序列已经全部有序。
循环结束:至此左子序列已经排序完成,接下来对右子序列实施同样的递归步骤,就不再演示了,聪明的你一定get到了。
特别注意:
以上过程中left和right指针在某个元素相遇,这种情况在代码中是不会出现的,因为外层限制了i!=j,图中之所以放到一起是为了直观表达终止条件。
版本二C++版本动画演示:
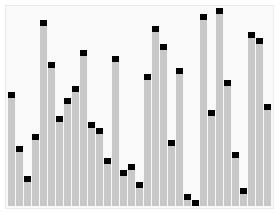
分析一下:
个人觉得这个版本虽然同样使用D&C思想但是更加简洁,从动画可以看到选择pivot=a[end],然后左右指针分别从index=0和index=end-1向中间靠拢。
过程中扫描目标值并左右交换,再继续向中间靠拢,直到相遇,此时再根据a[left]和a[right]以及pivot的值来进行合理置换,最终实现基于pivot的左右子序列形式。
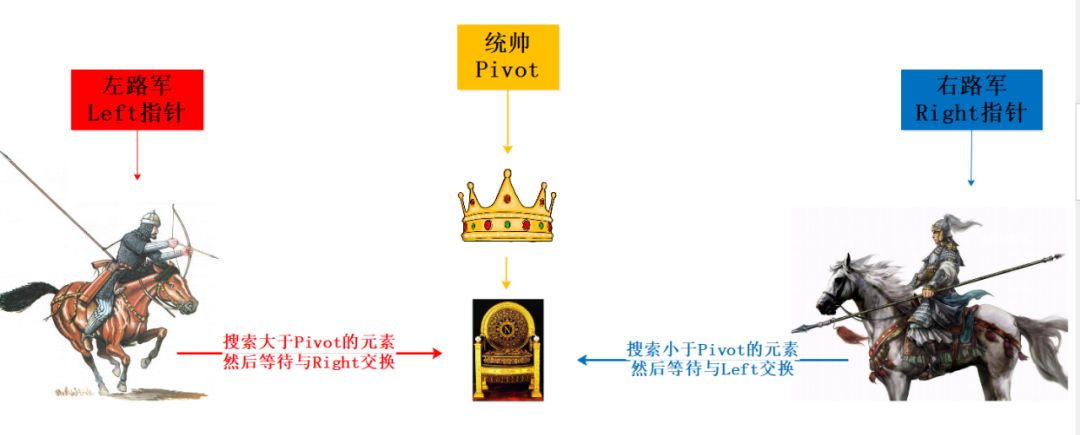
脑补场景:
上述过程让我觉得很像统帅命令左右两路军队从两翼会和,并且在会和过程中消灭敌人有生力量(认为是交换元素),直到两路大军会师。
此时再将统帅王座摆到正确的位置,此过程中没有统帅王座的反复变换,只有最终会师的位置,以王座位中心形成了左翼子序列和右翼子序列。
再重复相同的过程,直至完成大一统。
脑补不过瘾 于是凑图一张:
快速排序的多种版本
吃瓜时间:
印象中2017年初换工作的时候去CBD一家公司面试手写快排,我就使用C++模板化的版本二实现的,但是面试官质疑说这不是快排,争辩之下让我们彼此都觉得对方很Low,于是很快就把我送出门SayGoodBye了^_^。
我想表达的意思是,虽然快排的递归版本是基于D&C实现的,但是由于pivot值的选择不同、交换方式不同等诸多因素,造成了多种版本的递归代码。
并且内层while循环里面判断>=还是>(即是否等于的问题),外层循环判断本序列循环终止条件等写法都会不同,因此在写快排时切忌死记硬背,要不然边界条件判断不清楚很容易就死循环了。
看下上述我贴的两个版本的代码核心部分:
1//版本一写法
2while(i!=j){
3 while(i<j&&a[j]>=temp){
4 j--;
5 }
6 exchange(&a[i],&a[j]);
7 while(i<j&&a[i]<=temp){
8 i++;
9 }
10 exchange(&a[i],&a[j]);
11}
1//版本二写法
2while (left < right) {
3 while (arr[left] < mid && left < right)
4 left++;
5 while (arr[right] >= mid && left < right)
6 right--;
7 std::swap(arr[left], arr[right]);
8}
另外在网上很多大神的博客里面还进行了多种模式的快排:单轴模式、双向切分、三项切分、多基准值等新花样,感兴趣可以参考快速排序算法的多种实现。
其实无论哪种写法都需要明确知道自己是交换、还是覆盖、基准值选取位置、>=和<=的等号问题、循环终止条件等,这样才能写出BugFree的快速排序算法。
网上很多代码的核心部分是这样写的:
1int pivot = A[L];
2int i = L, j = R;
3while(i < j){
4 while(i < j && A[j] > pivot){
5 j--;
6 }
7 //是覆盖 不是交换
8 A[i] = A[j];
9 while(i < j && A[i] <= pivot){
10 i++;
11 }
12 //是覆盖 不是交换
13 A[j] = A[i];
14}
15//最后把基准值放到坑位
16A[i] = pivot;
覆盖or交换:
代码中首先将pivot的值引入局部变量保存下来,这样就认为A[L]这个位置是个坑,可以被其他元素覆盖,最终再将pivot的值填到最后的坑里。
这种做法也没有问题,因为你只要画图就可以看到,每次坑的位置是有相同元素的位置,也就是被备份了的元素。
个人感觉 与其叫坑不如叫备份,但是如果你代码使用的是基于指针或者引用的swap,那么就没有坑的概念了。
这就是覆盖和交换的区别,本文的例子都是swap实现的,因此没有坑位被最后覆盖一次的过程。
快速排序的迭代实现
所谓迭代实现就是非递归实现一般使用循环来实现,我们都知道递归的实现主要是借助系统内的栈来实现的。
如果调用层级过深需要保存的临时结果和关系会非常多,进而造成StackOverflow栈溢出。
Stack一般是系统分配空间有限内存连续速度很快,每个系统架构默认的栈大小不一样,笔者在x86-CentOS7.x版本使用ulimit -s查看是8192Byte。
避免栈溢出的一种办法是使用循环,以下为笔者验证的使用STL的stack来实现的循环版本,代码如下:
1#include <stack>
2#include <iostream>
3using namespace std;
4
5template<typename T>
6void qsort(T lst[], int length) {
7 std::stack<std::pair<int, int> > mystack;
8 //将数组的首尾下标存储 相当于第一轮循环
9 mystack.push(make_pair(0, length - 1));
10
11 while (!mystack.empty()) {
12 //使用栈顶元素而后弹出
13 std::pair<int,int> top = mystack.top();
14 mystack.pop();
15
16 //获取当前需要处理的子序列的左右下标
17 int i = top.first;
18 int j = top.second;
19
20 //选取基准值
21 T pivot = lst[i];
22
23 //使用覆盖填坑法 而不是交换哦
24 while (i < j) {
25 while (i < j and lst[j] >= pivot) j--;
26 lst[i] = lst[j];
27 while (i < j and lst[i] <= pivot) i++;
28 lst[j] = lst[i];
29 }
30
31 //注意这个基准值回填过程
32 lst[i] = pivot;
33
34 //向下一个子序列进发
35 if (i > top.first) mystack.push(make_pair(top.first, i - 1));
36 if (j < top.second) mystack.push(make_pair(j + 1, top.second));
37 }
38}
39
40int main()
41{
42 int a[9]={5,1,9,6,7,11,3,8,4};
43 int len = sizeof(a)/sizeof(int);
44 qsort(a,len);
45 for(int i=0;i<len-1;i++)
46 cout<<a[i]<<endl;
47}下期精彩
由于篇幅原因,目前文章已经近6000字,因此笔者决定将快排算法的优化放到另外一篇文章中,不过可以提前预告一下会有哪些内容:
基准值选择对性能的影响
基准值选择的多种策略
尾递归的概念原理和优势
基于尾递归实现快速排序
STL中sort函数的底层实现
glibc中快速排序的实现
参考资料
https://zhuanlan.zhihu.com/p/63202860
https://gist.github.com/Jack-Kingdom/eb69b889f3e20dbc754463d0ca183210
https://zh.wikipedia.org/wiki/%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F#C.2B.2B
https://zh.wikipedia.org/wiki/%E5%88%86%E6%B2%BB%E6%B3%95
原创不易 生活更难点赞在看 养成习惯 走心走肾不如走一波分享坚持写的我&坚持读的你 都比昨天更优秀!
以上是关于决战西二旗|你真的懂快速排序?的主要内容,如果未能解决你的问题,请参考以下文章