快速排序(part two)
Posted javasanity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快速排序(part two)相关的知识,希望对你有一定的参考价值。
欢迎点击蓝色字关注“javasanity”
快排完结篇终于来了。
①
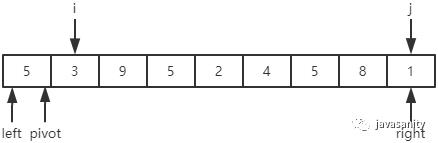
从上篇遗留问题说起
| 5 |
3 | 9 |
5 | 2 |
4 |
5 |
8 |
1 |
-
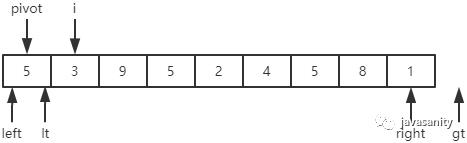
先从 i 开始向后扫描(或者,也可以先从 j 开始向前扫描),如果还没有遍历到 right 位置且当前值小于基准值,则不处理,继续查看下一个元素,直到找到一个值大于等于基准值; -
这时从 j 开始向前扫描,如果还没有遍历到 left + 1 位置且当前值大于基准值,则不处理,继续查看下一个元素,直到找到一个值小于等于基准值; -
此时,如果 i <= j,则交换 i 和 j 位置的值,之后 i 和 j 再分别指向下一个元素;否则跳出循环; -
跳出循环后,现在应该把基准值放到合适的位置。那么这个位置是 i 还是 j 呢?分析一下:此时 i 的位置,是从前往后第一个大于等于基准值的元素;此时 j 的位置,是从后往前第一个(也就是从前往后最后一个)小于等于基准值的元素;而基准值是处在小于等于基准值的这一端,所以要将 pivot 和 j 位置的值进行交换即可。
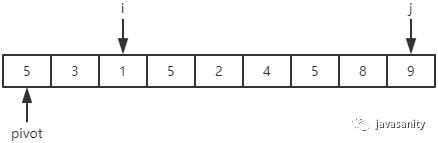
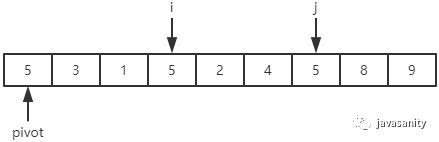
j:4 < 5,停止;
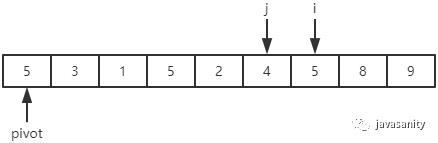
| 4 |
3 |
1 | 5 |
2 | 5 |
5 |
8 |
9 |
/*** quickSort双路快排* @param data 待排序的数组*/public void quickSort(int[] data) {quickSortHelper(data, 0, data.length - 1);}/*** 递归使用双路快排排序* @param data 待排序的数组* @param left 起始位置* @param right 结束位置*/private static void quickSortHelper(int[] data, int left, int right) {// 优化1:对于小规模数组(这里指定为16个元素), 使用插入排序if(right - left <= 15){insertSort(data, left, right);return;}int pivot = partition(data, left, right);// 递归排序基准数左部分quickSortHelper(data, left, pivot - 1);// 递归排序基准数右部分quickSortHelper(data, pivot + 1, right);}/*** 对数组 [left, right] 部分进行 partition 操作,双路* @param data 待排序的数组* @param left 起始位置* @param right 结束位置* @return 返回基准值位置,保证 data[left...pivot - 1] < data[pivot]; data[pivot + 1...right] > data[pivot]*/private static int partition(int[] data, int left, int right) {// 优化2:随机在 data[left...right] 范围中, 选择一个位置作为基准值int randomIndex = (int) (Math.random() * (right - left + 1)) + left;int temp = data[left];data[left] = data[randomIndex];data[randomIndex] = temp;// pivot,i,j 的定义在上边已经介绍int pivot = data[left], i = left + 1, j = right;while (true) {while (i <= right && data[i] < pivot) {i++;}while (j >= left + 1 && data[j] > pivot) {j--;}if (i > j) {break;}// swap i and jtemp = data[i];data[i] = data[j];data[j] = temp;i ++;j --;}// swap left and jdata[left] = data[j];data[j] = pivot;return j;}/*** 为了方便大家观看,这个插入排序的代码是直接从上一篇中拿过来的* 对data[l...r]的区间使用插入排序* @param data 待排序数组* @param l 起始index,代表left* @param r 结尾index,代表right*/private static void insertSort(int[] data, int l, int r) {for( int i = l + 1 ; i <= r ; i ++ ){int e = data[i];int j = i;for (; j > l && data[j-1] > e; j--) {data[j] = data[j - 1];}data[j] = e;}}
| 5 |
3 |
9 |
5 | 2 |
4 | 5 |
8 |
1 |
-
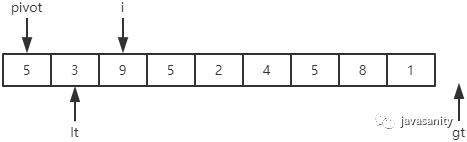
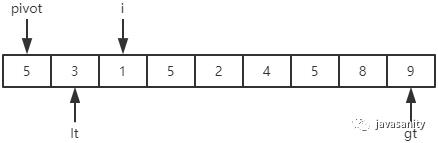
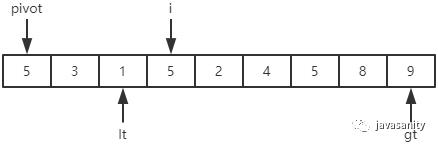
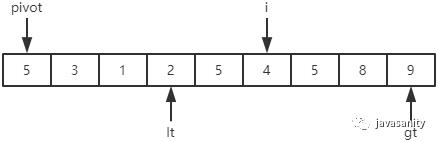
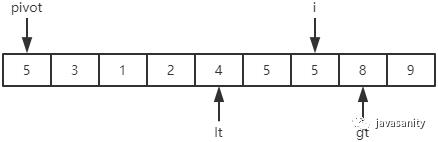
从 i 开始向后扫描,如果还没有遍历到 gt 位置,且当前值等于基准值,则不处理,继续查看下一个元素; -
如果还没有遍历到 gt 位置,且当前值小于基准值,则交换 i 和 lt + 1 位置的值;然后 i 和 lt 都指向下一个元素; -
如果还没有遍历到 gt 位置,且当前值大于基准值,则交换 i 和 gt - 1 位置的值;然后 gt 指向下一个元素。注意此时 i 是不用动的; -
i 遍历结束后,再把 pivot 和 lt 位置的值进行交换即可。
| 4 | 3 |
1 | 2 |
5 |
5 |
5 | 8 |
9 |
/*** quickSort三路快排* @param data 待排序的数组*/private void quickSort(int[] data) {quickSortHelper(data, 0, data.length - 1);}/*** 递归使用三路快排排序* 直接包含了对数组 [left, right] 部分进行 partition 操作的代码* @param data 待排序的数组* @param left 起始位置* @param right 结束位置*/private static void quickSortHelper(int[] data, int left, int right) {// 优化1:对于小规模数组(这里指定为16个元素), 使用插入排序if (right - left <= 15) {insertSort(data, left, right);return;}/* partition start */// 优化2:随机在 data[left...right] 范围中, 选择一个位置作为基准值int randomIndex = (int) (Math.random() * (right - left + 1)) + left;int temp = data[left];data[left] = data[randomIndex];data[randomIndex] = temp;// pivot,i,lt,gt 的定义在上边已经介绍int pivot = data[left], lt = left, gt = right + 1, i = left + 1;while (i < gt) {if (data[i] < pivot) {// swap i and lt + 1temp = data[i];data[i] = data[lt + 1];data[lt + 1] = temp;i ++;lt ++;} else if (data[i] > pivot) {// swap i and gt - 1temp = data[i];data[i] = data[gt - 1];data[gt - 1] = temp;gt --;} else {// if (data[i] == pivot)i ++;}}// swap left and ltdata[left] = data[lt];data[lt] = pivot;/* partition end */// 递归排序数组左部分quickSortHelper(data, left, lt - 1);// 递归排序数组右部分quickSortHelper(data, gt, right);}/*** 为了方便大家观看,这个插入排序的代码是直接从上一篇中拿过来的* 对data[l...r]的区间使用插入排序* @param data 待排序数组* @param l 起始index,代表left* @param r 结尾index,代表right*/private static void insertSort(int[] data, int l, int r) {for( int i = l + 1 ; i <= r ; i ++ ){int e = data[i];int j = i;for (; j > l && data[j-1] > e; j--) {data[j] = data[j - 1];}data[j] = e;}}
-
最优时间复杂度:O(n * logn) -
分析过程可以类似于归并排序,都是分治法。 -
最坏时间复杂度:O(n^2) -
平均时间复杂度:O(n * logn)
-
我们的快排代码是通过递归调用实现的,所以需要一个栈空间来辅助递归。最好情况下,类似于归并排序,所需栈的最大深度为 logn;最坏情况下,所需栈的最大深度为 n。所以,快排的空间复杂度为 O(logn) ~ O(n)。
-
上面双路快排的 demo 已经能够说明。

如果感觉有收获,可以点个“在看”嘛▼
以上是关于快速排序(part two)的主要内容,如果未能解决你的问题,请参考以下文章