图解:什么是快速排序?
Posted 数据结构与算法
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解:什么是快速排序?相关的知识,希望对你有一定的参考价值。
Python实战社群
Java实战社群
长按识别下方二维码,按需求添加
扫码关注添加客服
进Python社群▲

扫码关注添加客服
进Java社群▲
作者丨景禹
来源丨景禹(LifeAtaraxia)
快速排序
快速排序思想篇
与归并排序一样,我们今天要学习的快速排序也是一个分治算法。
快速排序首先选一个基准(你也可以认为是要放到排序后数组正确位置的元素)pivot,然后将数组按照选取的基准 pivot 进行划分。而选取 pivot 的方式又有很多种,所以快速排序具有很多版本。
-
总是选择第一个元素作为基准 pivot; -
总是选择最后一个元素作为基准;(本文后续的实现就是依次为例) -
随机的选择一个元素作为基准; -
选择最中间的元素作为基准;
快速排序的关键是划分 partion() 。每一趟划分,我们就可以将作为 pivot 的值 x 放到排序数组的正确位置,并且将所有比 x 小的放到 x 的左边,所有比 x 大的元素放到 x 的右边。而且划分操作的时间复杂度是线性的奥,即
量级!
正所谓一图胜千文,我们看图学算法吧!
为了讲解快速排序并验证其稳定性,我们用下面的数组进行说明(其中两个4分别用不同的颜色标注):
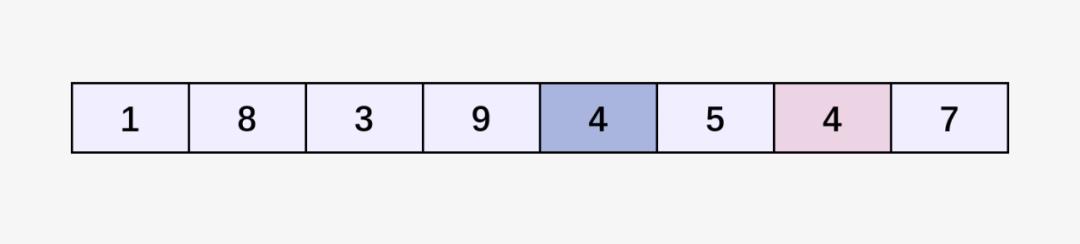
首先选择数组当中的最后一个位置元素 7 作为 pivot:
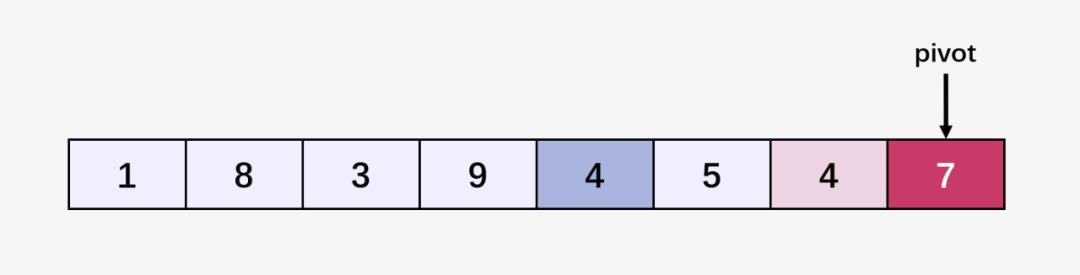
然后就是执行第一趟快速排序啦!!!
第一步:设置一个指针 i = -1 (初始化为 -1,用于找到 pivot 的正确位置),设置一个遍历数组的指针 j = 0 ,用于遍历从 0 到 pivot 的前一个元素 4 (即两条竖线之间的元素,从而将 7 放到排序后数组的正确位置):
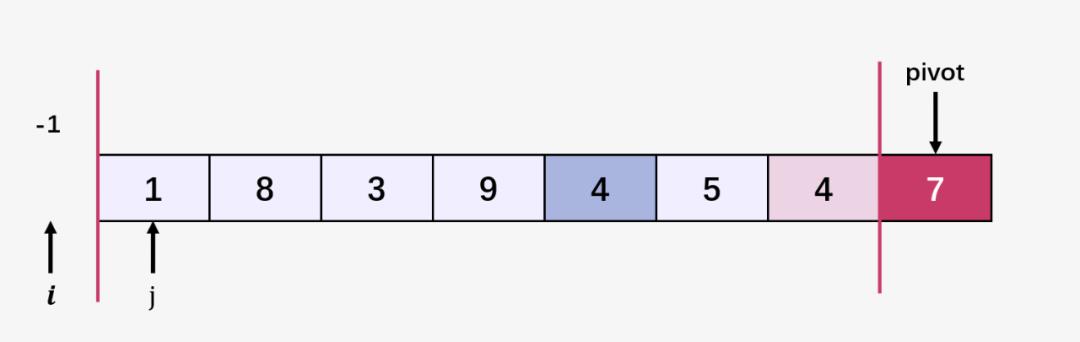
第二步:比较 j 当前指向的元素 1 和 7 ,1 <= 7 ;指针 i++ ,即 i = 0 ,交换 arr[i] 和 arr[j] ,即 交换 arr[0] 和 arr[0] (数组本身并无变化) ;然后指针 j 向右移动:
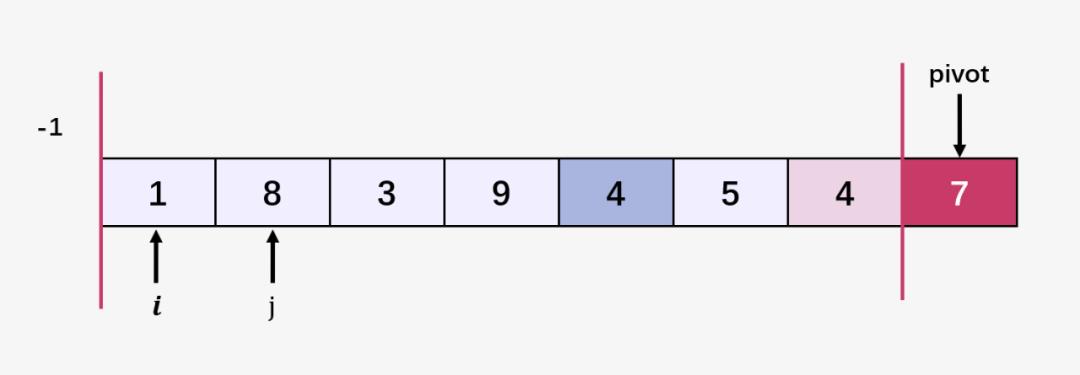
第三步:比较当前 j 指向的元素 8 和 7 (pivot),8 > 7;什么都不做;然后指针 j 向右移动:
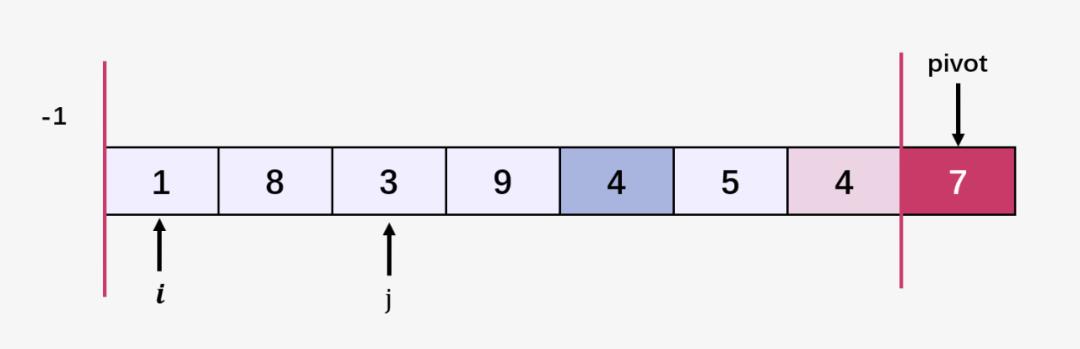
第四步:比较当前 j 指向的元素 3 和 7 ,3 <= 7;指针 i++ ,即 i = 1 ,交换 arr[i] 和 arr[j] ,即 交换 arr[1] = 8 和 arr[2] = 3 ;然后指针 j 向右移动:
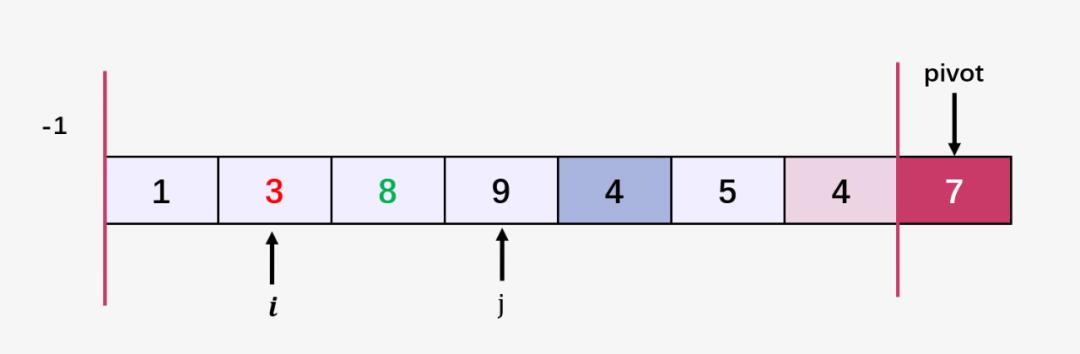
第五步:比较当前 j 指向的元素 9 和 7 ,9 > 7;什么都不做;然后指针 j 向右移动:
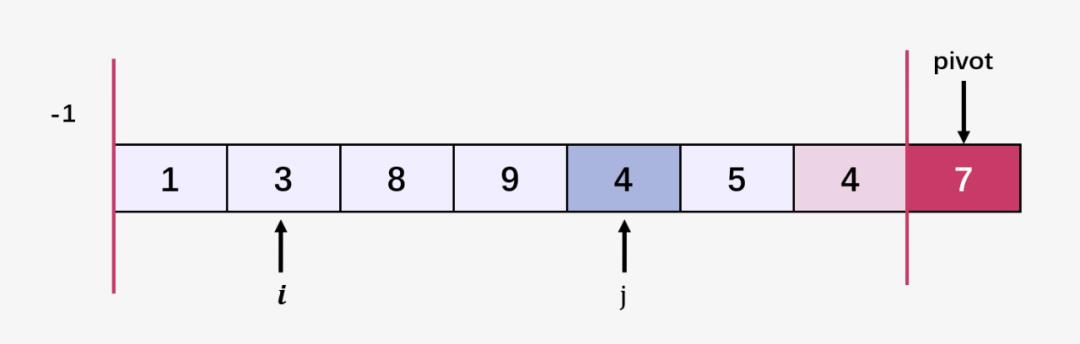
第六步:比较当前 j 指向的元素 4 和 7 ,4 <= 7;指针 i++ ,即 i = 2 ,交换 arr[i] 和 arr[j] ,即交换 arr[2] = 8 和 arr[4] = 4 ;然后指针 j 向右移动:
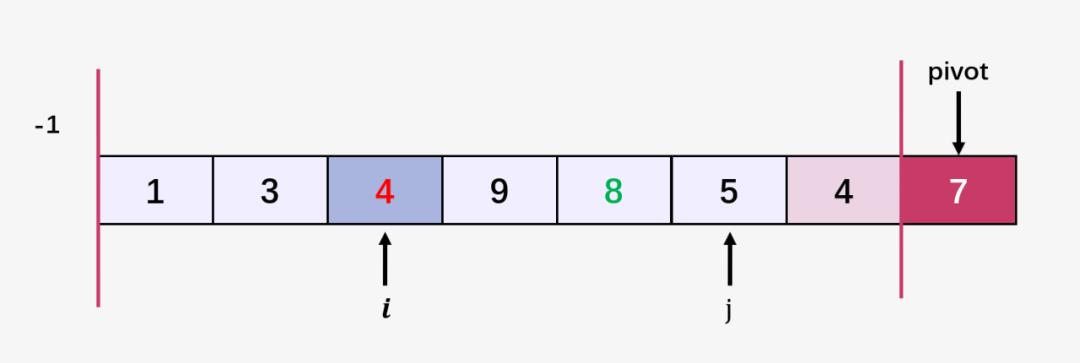
第七步:比较当前 j 指向的元素 5 和 7 ,5 <= 7;指针 i++ ,即 i = 3 ,交换 arr[i] 和 arr[j] ,即交换 arr[3] = 9 和 arr[5] = 5 ;然后指针 j 向右移动:
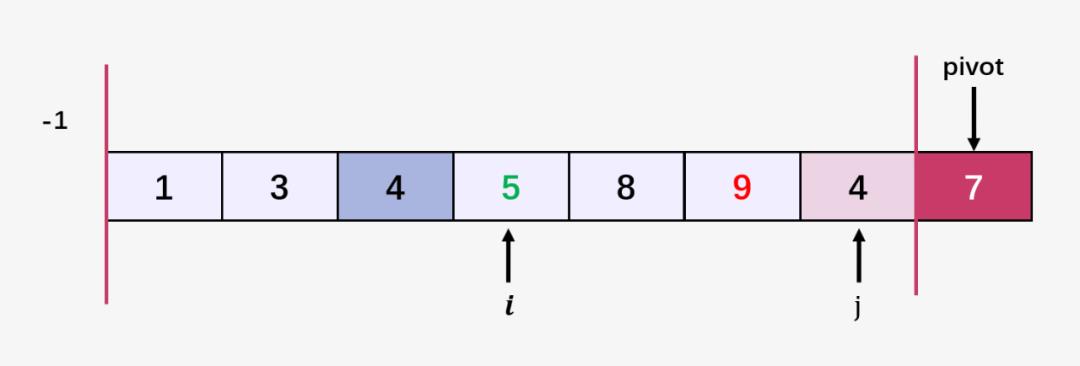
第八步:比较当前 j 指向的元素 4 和 7 ,4 <= 7;指针 i++ ,即 i = 4 ,交换 arr[i] 和 arr[j] ,即交换 arr[4] = 8 和 arr[6] = 4 ;然后指针 j 向右移动:
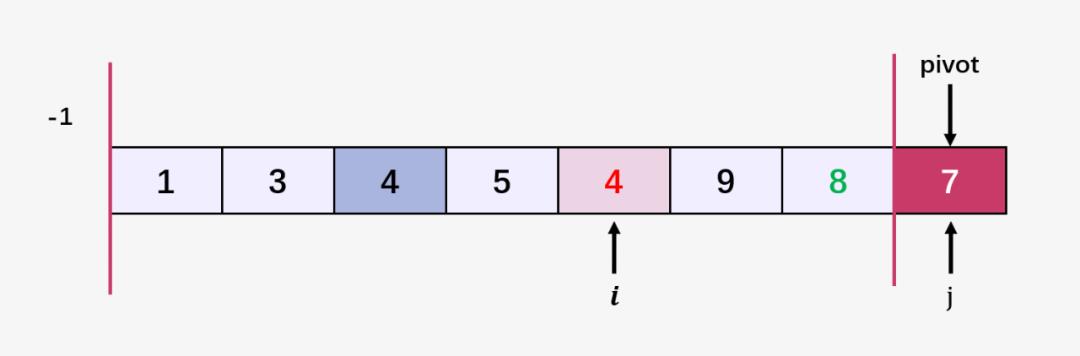
第九步:此时遍历结束,交换 arr[i+1] 和 arr[high] = pivot ,即交换 9 和 7
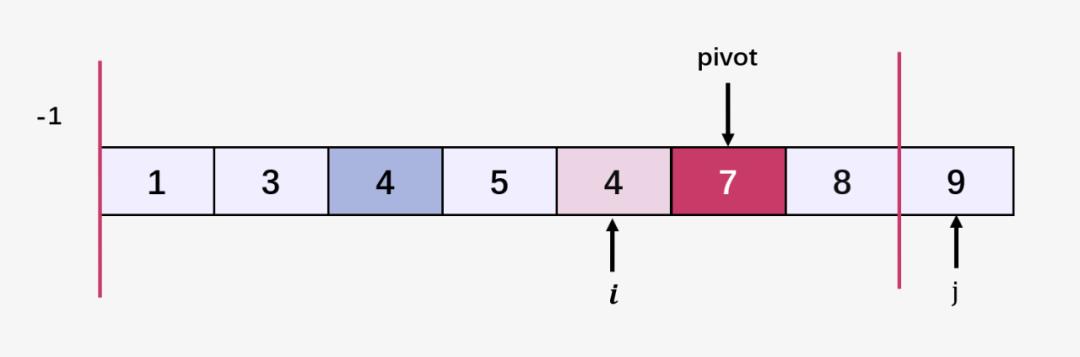
此时第一趟快速排序结束啦,我们确定了最开始选择的 pivot 的正确位置。
接下就是分别对 7 左侧比 7 小的元素 [1,3,4,5,4] ,与右侧比 7 大的元素进行快速排序,过程和第一趟排序过程一样,此处不再赘述。


前面提到快速排序和归并排序一样均属于分治算法,而我之前在写归并排序时提到过,分治与递归就是一个孪生兄弟,提到了分治,怎能缺少递归呢?
递归三要素中最核心的就是确定一个函数的功能,而我们经过上面对一趟快速排序的介绍,可以发现,之后的每一趟快速排序事实上和第一趟是一样的,也就意味着反复调用同一个函数存在,即快速排序的过程中蕴含了递归思想,这也是分治的一个佐证。
但是我们也可以有更清晰的解释,且看下图:
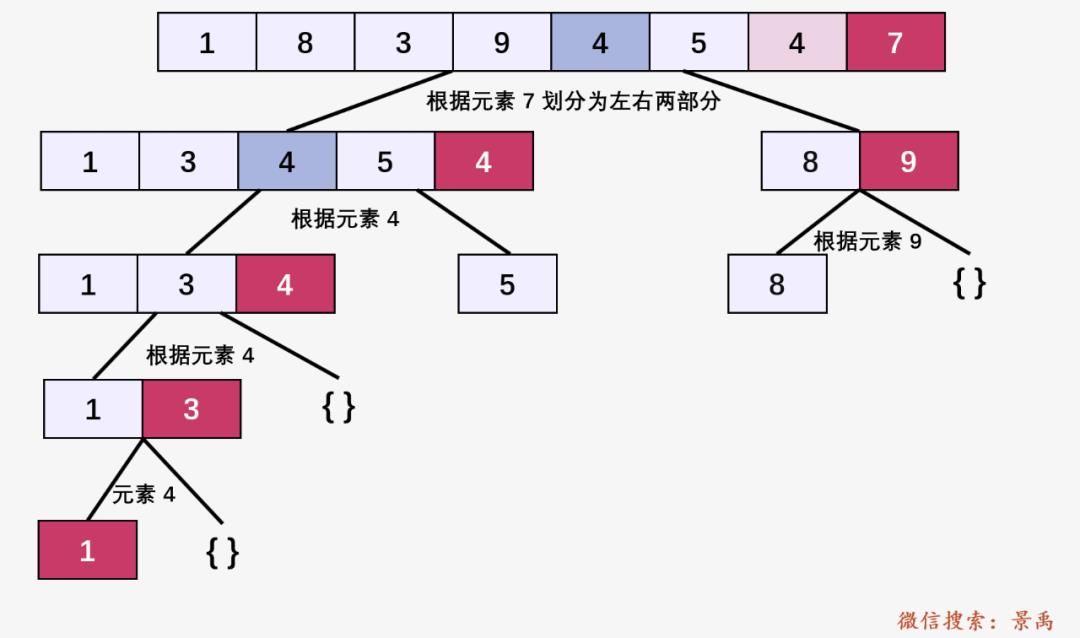
首先根据原始数组 [1,8,3,9,4,5,4,7] ,将数组划分为小于等于 7 的数组 [1,3,4,5,4] 和 [8,9] ,然后将 [1,3,4,5,4] 根据 4 划分为 [1,3,4] 和 [5] ;将 [1,3,4] 根据 4 划分为 [1,3] ;将 [1,3] 根据 3 划分为 [1] ;将 [8,9] 根据 9 划分为 [8] ;这个过程不就是二分吗?
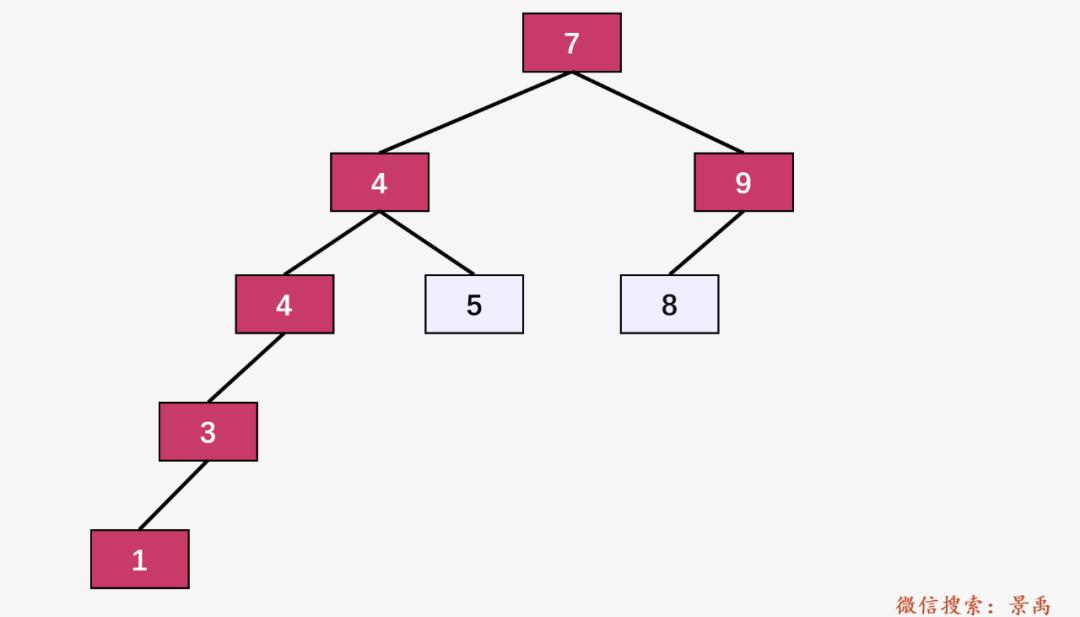
的确如此,只不过对于这个数组而言选择最末尾的元素作为 pivot 得到的树的高度并不是我们期望的 ,而是 4 。
说到这里,我们顺带说一下快速排序的缺点,对于一个有序数组 [1,3,4,4,5,7,8,9] 而言,如果每次选择最后一个元素作为 pivot ,就会得到下面一幅图:

而这时树的高度变成了
,也就意味着快速排序退化成了一颗单链,这不是我们希望看到的。但是我们每一次选择最中间的元素作为 pivot ,又会怎么样呢?
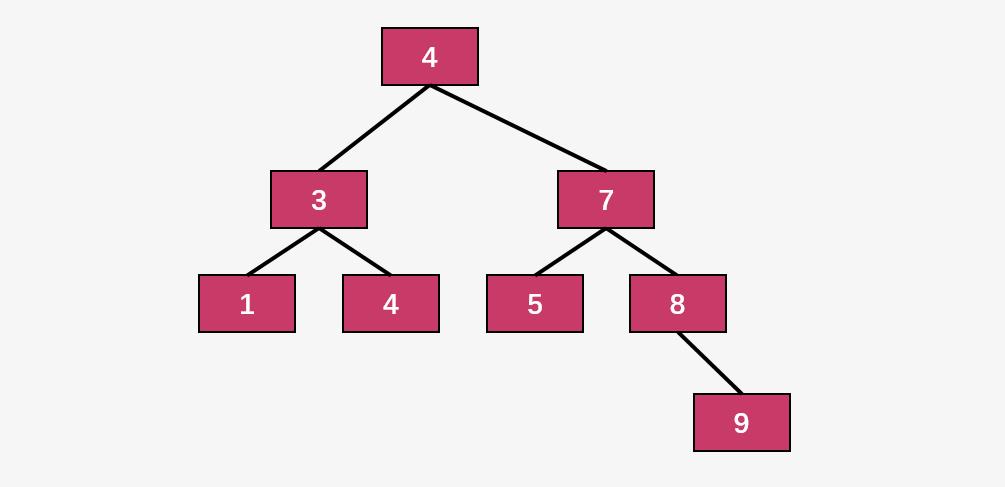
思考: 如果将数组 [1,8,3,9,4,5,4,7] 重新调整顺序,使得快速排序的的分治过程如上图所示?
看着图就能写出来了,当然答案可能有很多个,最简单的一个就是 [1,4,3,5,8,9,7,4] 。
快速排序实现代码
class QuickSort
{
/*将最后一个元素作为 pivot 进行划分操作*/
int partition(int arr[], int low, int high)
{
int pivot = arr[high];
int i = (low-1); // 比 pivot 小的元素的下标
for (int j = low; j < high; j++)
{
// 如果当前的元素小于 pivot
if (arr[j] < pivot)
{
i++;
// 交换 arr[i] 和 arr[j]
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
// 交换 arr[i+1] 和 arr[high] (也就是pivot)
int temp = arr[i+1];
arr[i+1] = arr[high];
arr[high] = temp;
return i+1;
}
/*分的阶段,利用递归调用实现快速排序*/
void sort(int arr[], int low, int high)
{
if (low < high)
{
/* pi 就是 pivot 排序后位置的下标*/
int pi = partition(arr, low, high);
// 递归调用 pivot 的前后数组
sort(arr, low, pi-1);
sort(arr, pi+1, high);
}
}
/* 打印输出 */
static void printArray(int arr[])
{
int n = arr.length;
for (int i=0; i<n; ++i)
System.out.print(arr[i]+" ");
System.out.println();
}
// 主函数
public static void main(String args[])
{
int arr[] = {1,8,3,9,4,5,4,7};
int n = arr.length;
QuickSort ob = new QuickSort();
ob.sort(arr, 0, n-1);
System.out.println("sorted array");
printArray(arr);
}
}
复杂度分析
时间复杂度分析
快速排序的时间通常表示为:
其中
和
分别表示递归调用,而最后一项
表示 partition() 的处理过程,
表示比 pivot 小的元素的数目。
而快速排序的时间复杂度取决于输入的数组和划分策略,所以需要从三个方面分析:
一、最坏情况
最后情况就是我们每一次选择最大的元素或者最小的元素作为 pivot 。以我们上面讲快速排序选择做末尾的元素作为 pivot,最坏情况就是输入的待排序数组为有序数组(以升序为例),此时
,那么:
,即: ;
所以最坏情况下的时间复杂度为 量级。
不理解推导没关系,看栗子,设对有序数组 [1,3,4,4,5,7,8,9] 进行快速排序,每次选择最末尾的元素作为 pivot,那么就会得到下图所示的情况:
也就说需要选择 个 pivot,并且以每一个 pivot 进行划分需要 的时间,那么总的时间就是 量级。
二、最好情况
当划分过程中每一次都能选择最中间的元素作为基准 pivot ,那么快速排序的时间复杂度就等于:
其中
表示快速排序的时间复杂度,
表示划分出的两个子数组排好序所用的时间,
表示 partion() 函数的执行时间。
根据主定理(Master Theorem),快速排序最好情况下的时间复杂度为 .
主定理不明白的可以看一下
当然我们也可以换一个角度来算,比如对数组 [1,8,3,9,4,5,4,7] 而言,我们希望得到的是下面一幅图:
这个树的高度就是
,也就是选择 pivot 需要
次,而根据每一个 pivot 我们需要
的时间执行 partition() 函数,所以总的时间复杂度为
量级。
三、平均情况
对于平均时间复杂度分析而言,我们需要考虑数组的所有可能的排列,并计算出对每一个排列所需要的时间,然后求平均,但是实在太复杂了。我们可以考虑一个一般的假设,比如对于一个数组而言, 的元素每次比选择的 pivot 小,而 的元素比 pivot 大,那么快速排序的时间复杂度为:
.
根据主定理,快速排序的时间复杂度依旧是 , 也就意味着只要只要每一次不是选择最大或者最小的元素作为 pivot ,时间复杂度都在 量级。
快速排序的平均时间复杂度为 量级。
空间复杂度分析
快速排序的实现中,我们仅使用了一个临时变量用于交换操作,也就是其空间复杂度为 ,所以快速排序也是一个原地排序算法。
稳定性分析
快速排序的划分阶段会进行交换操作,而这种交换操作会破坏原始数组中元素之间的相对位置,也就意味着,快速排序是一个不稳定的排序算法。
当然所有的排序算法都可以变得稳定,有机会我们再谈稳定的快速排序如何实现。
快速排序 vs 归并排序
一、对数组中元素的划分
在归并排序中,数组总被划分为两半(即 );而快速排序,数组可能被划分为任意比例(比如之前提到的 和 ),而不是强制要求将数组划分为相等的两部分。
二、最坏时间复杂度
快速排序最坏情况下的时间复杂度为 ,而归并排序,最坏情况和平均情况下的时间复杂度均为 。
三、对数据的敏感性
归并排序适用于任何类型的数据集,不受数据集大小限制;而快速排序不适用于大规模数据集(简单来说,就是数组太大,快速排序效果并不好)。
四、空间复杂度
归并排序需要额外的存储空间 ,不是一个原地排序算法;而快速排序不需要额外的空间,空间复杂度为 ,为原地排序算法。
五、效率
归并排序在大规模的数据集上比快速排序更加高效,而快速排序在小规模的数据集上更高效。具体这个规模的界定,在 Java 的 sort 中有一个参考的界定。
六、排序方法
快速排序是一个内部排序算法,所有的数据都存储在主存当中;而归并排序是一个外部排序算法,待排序的数据无法容纳在主存中,而且需要额外的存储空间进行辅助合并。
七、稳定性
归并排序是一个稳定的排序算法,因为两个等值元素在排序前后的相对位置不会发生变化;快速排序不是一个稳定的排序算法,但是可能通过调整代码让其变得稳定。
八、对数组和链表的敏感度
快速排序更适用于数组排序,而归并排序两者皆适合。
综合来看,尽管快速排序最坏情况下的时间复杂度为 ,比归并排序最坏情况下的时间复杂度高。但是在实际应用中,快速排序排序更快,因在大多数的真实数据中,快速排序可以以更高效的方式实现。快速排序也可以通过改变 pivot 的选择方式而实现不同的版本,最坏情况其实很少发生。当然,归并排序在大规模和存储在外部存储器的数据更为适合。

程序员专栏
扫码关注填加客服
长按识别下方二维码进群


近期精彩内容推荐:


在看点这里好文分享给更多人↓↓
以上是关于图解:什么是快速排序?的主要内容,如果未能解决你的问题,请参考以下文章