2.快速排序
Posted 老咪聊计算机
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2.快速排序相关的知识,希望对你有一定的参考价值。
1.经典快速排序
快速排序作为最重要的排序算法之一,有时间还是得温习温习。
先说说Partition的过程,经典快排用数组的最后一个元素作为及基准值。将数组的所以小于基准值的数放在数组的左边,等于基准值的数放在数组的中间,大于基准值的放在数组的最后面。
一开始的情况
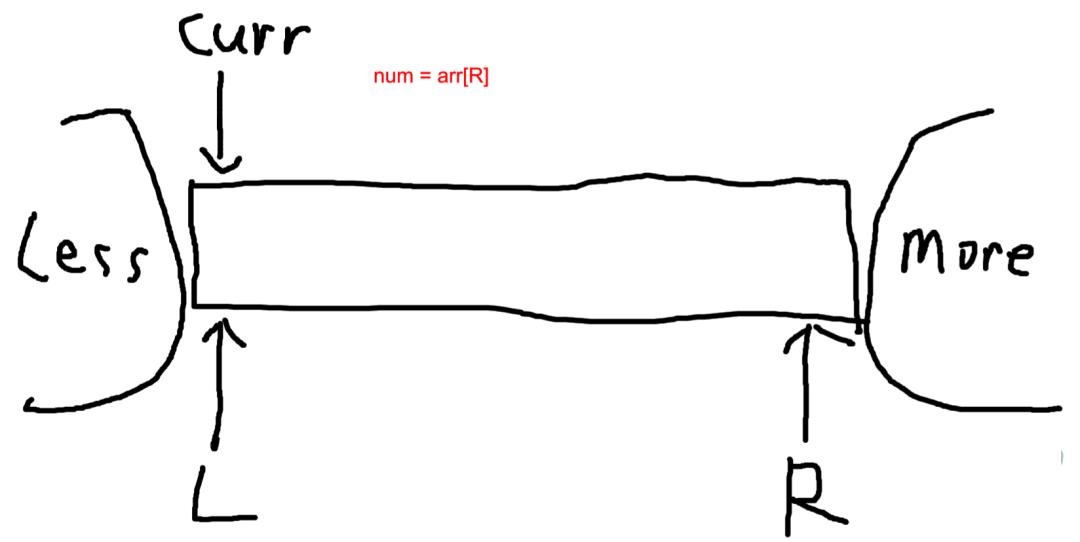 然后下面循环,直到curr < more的时候结束. 这里我们注意,整个过程像是数组中小于基准值部分推着等于基准值部分向前走.
然后下面循环,直到curr < more的时候结束. 这里我们注意,整个过程像是数组中小于基准值部分推着等于基准值部分向前走.
-
0 到 less是小于区, -
less + 1 到 curr - 1是等于区, -
curr 到 more - 1是待定区, -
more到数组的最后的元素 是大于区.
最后返回等于区域的下标即可.
Partition完成后就可以写快排的代码了. 快排就是递归的进行Partitio即可.
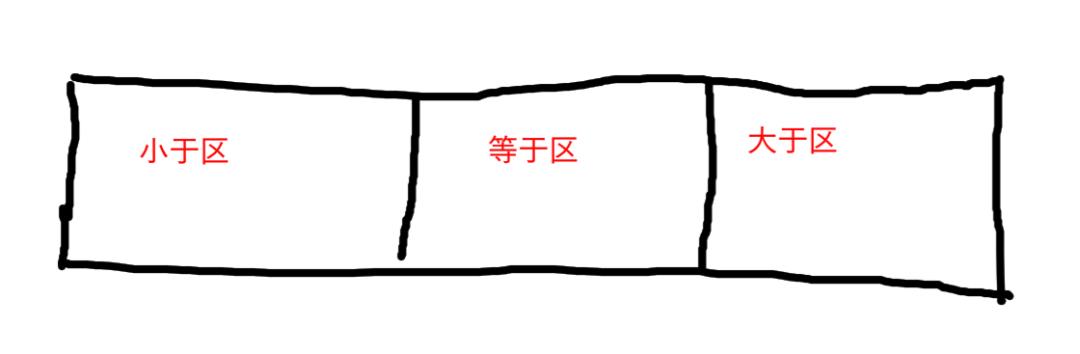 然后在小于区和大于区分别进行Partition. 最终快排就完成了.
然后在小于区和大于区分别进行Partition. 最终快排就完成了.
public class Sort {
public static void swap(int[] arr, int index1,int index2){
int temp = arr[index1];
arr[index1] = arr[index2];
arr[index2] = temp;
}
public static int[] partition(int[] arr, int L, int R){
int less = L - 1;
int more = R + 1;
int curr = L;
int num = arr[R];
while (curr < more){
if (arr[curr] == num){
curr++;
}else if(arr[curr] < num){
swap(arr, ++less, curr++);
}else if (arr[curr] > num){
swap(arr, --more, curr);
}
}
return new int[] {less + 1, more - 1};
}
public static void quickSort(int[] arr, int L, int R){
if (L < R){
int[] p = partition(arr, L, R);
quickSort(arr, 0, p[0] - 1 );
quickSort(arr,p[1] + 1, R);
}
}
}
我们冷静的分析一波,经典快排存在的问题. 当排序的数组中的数据状况是如下情况的时候
那么我们选取的基准值总是数组的最小值, 这时算法的复杂度就是 , 额外空间复杂度为 . 但是我们并不想这样.
2.随机快速排序
使用Math.random()令系统随机选取一个0~1之间的double类型小数,将其乘以一个数,比如25,就能得到一个0~25范围内的随机数.
public class Sort {
public static void swap(int[] arr, int index1,int index2){
int temp = arr[index1];
arr[index1] = arr[index2];
arr[index2] = temp;
}
public static int[] partition(int[] arr, int L, int R){
int less = L - 1;
int more = R + 1;
int curr = L;
int num = arr[R];
while (curr < more){
if (arr[curr] == num){
curr++;
}else if(arr[curr] < num){
swap(arr, ++less, curr++);
}else if (arr[curr] > num){
swap(arr, --more, curr);
}
}
return new int[] {less + 1, more - 1};
}
public static void quickSort(int[] arr, int L, int R){
if (L < R){
swap(arr, L + (int)(Math.random() * (R - L + 1)), R);
int[] p = partition(arr, L, R);
quickSort(arr, 0, p[0] - 1 );
quickSort(arr,p[1] + 1, R);
}
}
}
随机快排就蕴含着很重要的思想,算法在设计的过程中想绕开它本身的数据状况该怎么办? 一般有两种处理方法,
-
第一种就是用随机的方式打乱原始的数据状况, -
第二种是用Hash的方式也能绕开原始的数据状况.
总结
时间复杂度为 , 额外空间复杂度为 . 快排在工程中是最重要的排序算法之一, 在工程中大部分的排序都是使用快排.
虽然说快速排序的时间复杂度是 的和归并排序和堆排序的时间复杂度一致, 但是快排的实现代码是非常的简洁的, 这说明它的常数项操作少,常数项时间很低.
以上是关于2.快速排序的主要内容,如果未能解决你的问题,请参考以下文章