正则表达式和字符串处理
Posted 菠菜队长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式和字符串处理相关的知识,希望对你有一定的参考价值。
正则表达式
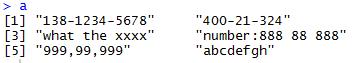

number<-“([0-9][-, ] [0-9][-, ] [0-9])|([0-9]-[0-9]-[0-9])”
(其中竖线是或的意思)
还有一些小规则讲一下,[0123456789]也是[0-9]的意思,若是要匹配小写字母,那就是[a-z],匹配所有字母,就是[a-Z];
‘^’是非的意思,也就是[^a-Z]意思是匹配所有非字母的字符;
‘.’是通配符,可以匹配任意字符;
‘.*’表示匹配任意长度的任意字符;
花括号的次数也有一些巧妙用法,举例说明吧,a{1,4}可以匹配"a"或者"aaaa",a{1-3}可以匹配"a"、"aa"、"aaa",colou{0,1}r就可以同时匹配到color和colour啦。还有若是这样a{3, },就可以匹配连续出现三次及以上的a呢。
正则表达式函数
为了偷个懒,我就直接复制我的笔记了写得很清楚的=。=(标题是函数,括号内是每个位置上的参数哈)
1.grep(正则表达式,要匹配的文本,value=FALSE,invert=FALSE)
不改后两个默认参数则返回带有正则表达式的文本序号,当value为真时,返回匹配的文本内容;当invert为真时,返回没被匹配到的文本序号。
2.grepl(正则表达式,要匹配的文本)
返回的是由true/false组成的逻辑向量表示每个位置有没有匹配到。
3.regexpr(正则表达式,要匹配的文本)
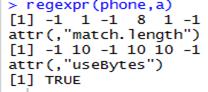
返回内容第一行表示正则表达式在列表每一项的第N个位置开始被匹配到,-1表示没有匹配到,第二行表示匹配到的长度,-1表示没有匹配到。不要问我第三行是什么,反正我很少用这个函数,要定位裁剪和裁剪匹配到的长度时,我通常用的下面讲的那个包。
4. gsub(正则表达式,要替换成什么,要被替换的字符文本)
可以在文本中搜索正则表达式的内容,然后替换成预设的文本;
最后用思考题来结束这一部分,我在做kaggle的一个题目时,有这么一个人名列:

这是数据集full里的name变量,有位选手做了如下操作:
full$Title <- gsub('(.*, )|(\\..*)', '', full$Name)
stringr包
1.str_c(a,b)
用来做字符串连接的函数,我们可以用它连接两个字符串,也可以连接两个字符串向量。ab可同为字符串,或同为等长字符串向量,按序号连接。
2.str_length(a)
计算字符串长度,可以操作单个字符串,也可以操作向量。
3.str_sub(a,c1,c2)
按位置截取我们想要的字符串,c1为截取的起始位置(默认值为1),c2为终点位置(默认值为-1)。
4.str_detect(a,c)
检测字符串a或字符串列表a是否能匹配到正则表达式c,返回逻辑值。
5.str_locate(a,c)
找出字符串a或字符串列表a匹配到正则表达式c的起始位置和终点位置(二维的wor),不含有c的返回NA。(我经常拿来和str_sub结合找到我要裁的位置然后剪出来)
6.str_extract(a,c)
7.str_replace(a,c,b)
替换,将字符串a或字符串列表a中匹配到正则表达式c的部分替换成b,和gsub( )一个功能,参数位置不同而已啦。
8.str_spilt(char,分隔符)
分割字符串,分隔符是见到什么符号就分割,结果不保留分隔符。
9.str_trim(char)
去除字符串前后的空白。
技术贴尝试告一段落,之后一定还会有超酷的题目的,不会就这样停的,然后我要试试其他路线了,等着我的毒鸡汤或者可怕的叙事文吧!可能写得很烂但我求求你不要取关嘛=。=
这里是菠菜队长
有事直接呼叫后台
队长帮你解决一切困难
以上是关于正则表达式和字符串处理的主要内容,如果未能解决你的问题,请参考以下文章