干货 | Requests+正则表达式爬取猫眼电影
Posted 小井说了算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 | Requests+正则表达式爬取猫眼电影相关的知识,希望对你有一定的参考价值。
陪伴你
一直到 故事说完
hello,大家好,小井又上线了~
今天一名Python小白想要分享他的数据爬虫,利用Requests和正则表达式,综合评分和评论数,爬取猫眼电影排名前100的电影。
欢迎各界人士指点,下面我们来看看吧~
一、知识储备
1. Python基础语法知识
2. 爬虫基础知识
3. Requests库+正则表达式
其余知识如Jason库只引用了一个简单的函数,百度一下就可以了解,其中多线程抓取仅做简单介绍,当做一个延伸扩展。
二、流程框架
1. 抓取单页内容:利用requests请求单页目标站点,得到单个网页HTML代码,返回结果。
2. 正则表达式分析:根据HTML代码得到电影的名称、主演、上映时间,评分、图片链接等信息。
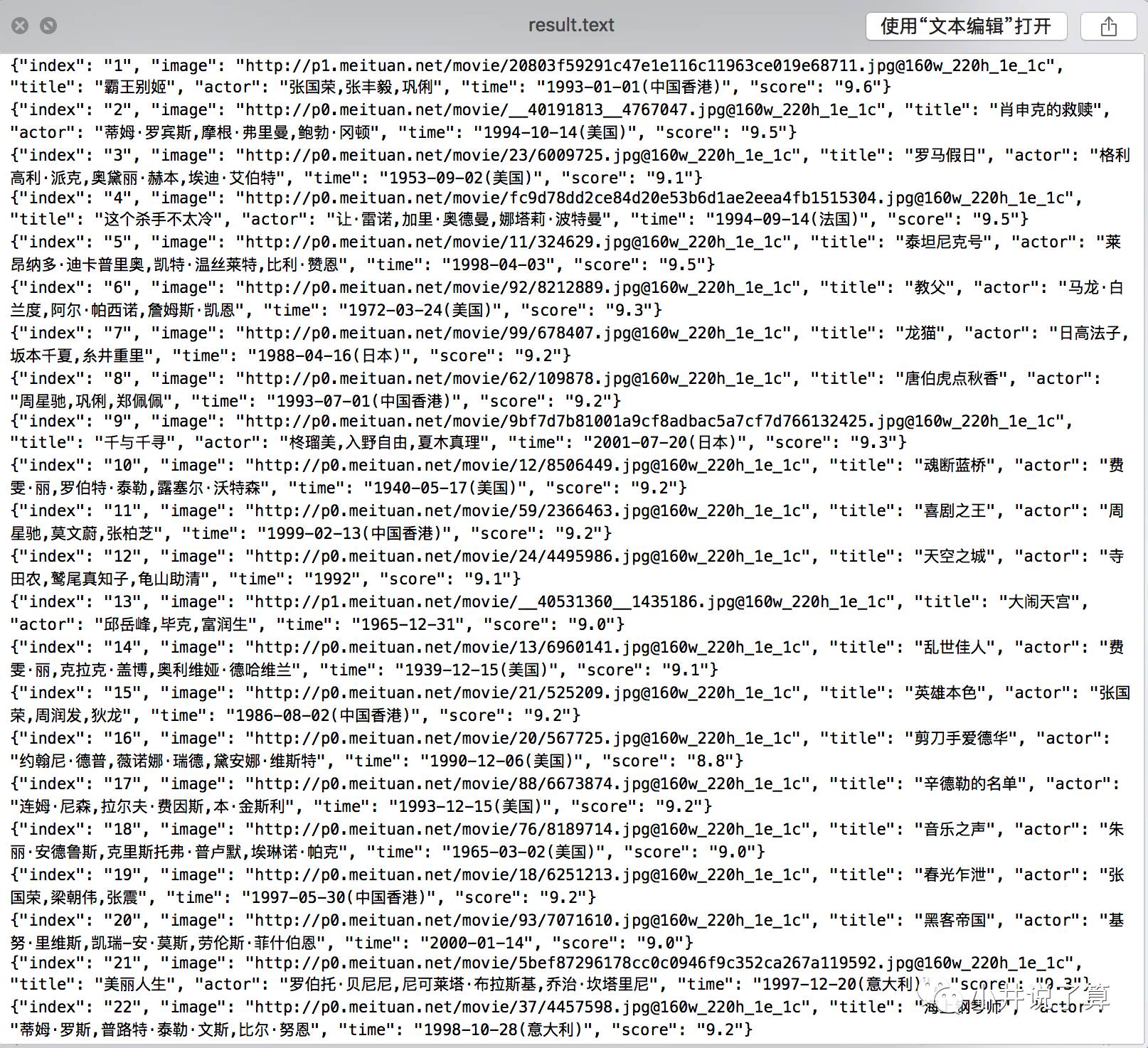
3. 保存至文件:通过文件的形式将结果保存,每一部电影一个结果一行Jason字符串。
4. 开启循环及多线程:对多页内容遍历,开启多线程提高抓取速度。

三、详细内容
3.1 目标站点分析

首先打开目标站点,用chrome浏览器右键-检查,调出开发者工具,对目标站点的网页代码进行分析。(http://maoyan.com/board/4)
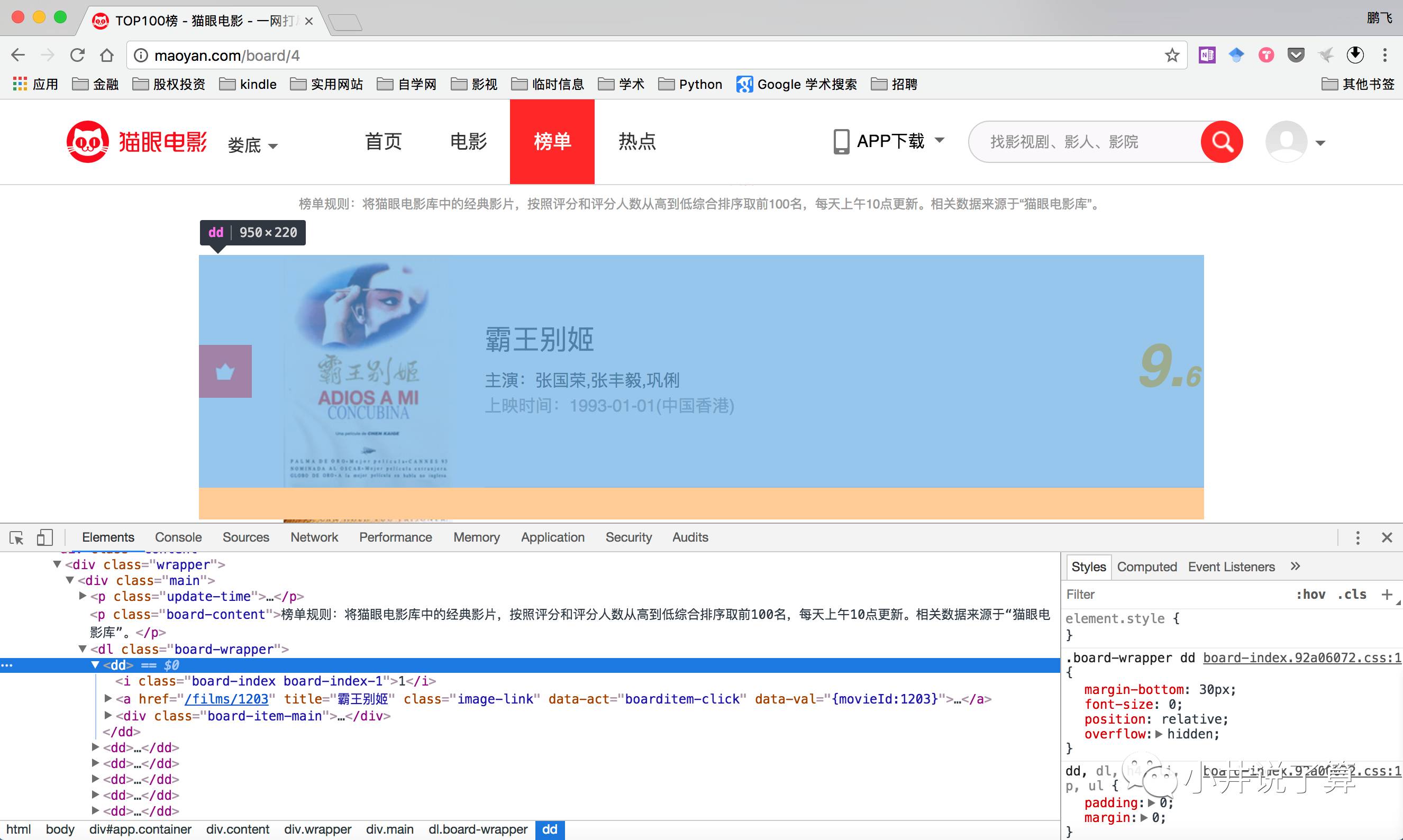
我们可以发现目标网站中每一个的电影信息都是由一个<dd>...<dd>的标签包围的。因为每个电影的内容格式是一样的,我们就可以利用一个正则表达式将我们需要的信息提取出来。
<dd>
<i class="board-index board-index-1">1</i>
<a href="/films/1203" title="霸王别姬" data-act="boarditem-click" data-val="{movieId:1203}">
<img alt="" />
<img src="/img?url=http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c" alt="霸王别姬" />
</a>
<div>
<div>
<div>
<p><a href="/films/1203" title="霸王别姬" data-act="boarditem-click" data-val="{movieId:1203}">霸王别姬</a></p>
<p>
主演:张国荣,张丰毅,巩俐
</p>
<p>上映时间:1993-01-01(中国香港)</p> </div>
<div class="movie-item-number score-num">
<p><i>9.</i><i>6</i></p>
</div>
</div>
</div>
</dd>
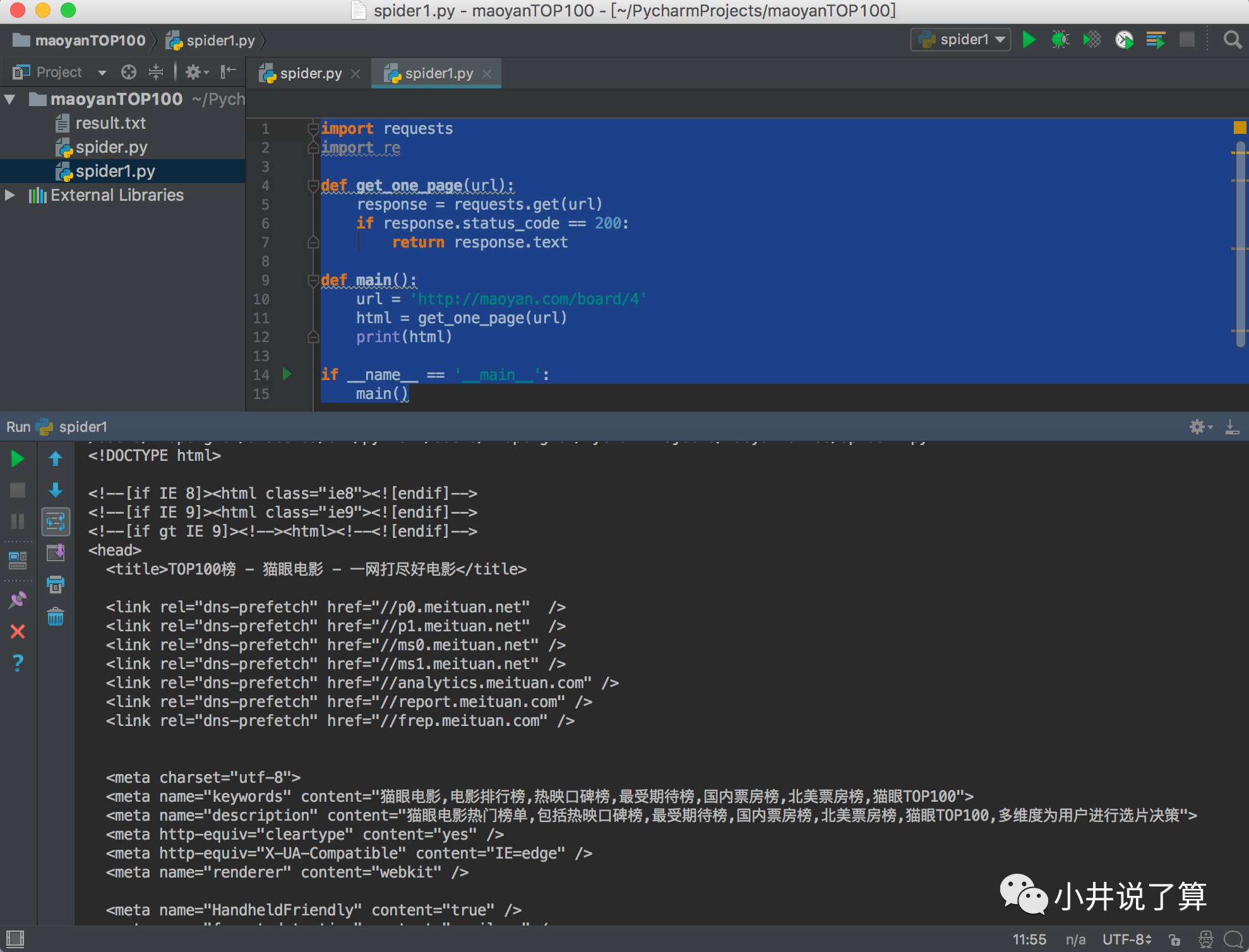
3.2 抓取单页内容
抓取单页网页的代码,运行下面程序,得到目标网站内容。
##抓取单页内容
import requests #引入requests和re库
import re
def get_one_page(url):
#创建一个请求单页内容的函数
response = requests.get(url)
if response.status_code == 200:
return response.text
def main():
#传入目标网站并打印网站内容
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
if __name__ == '__main__': #运行
main()
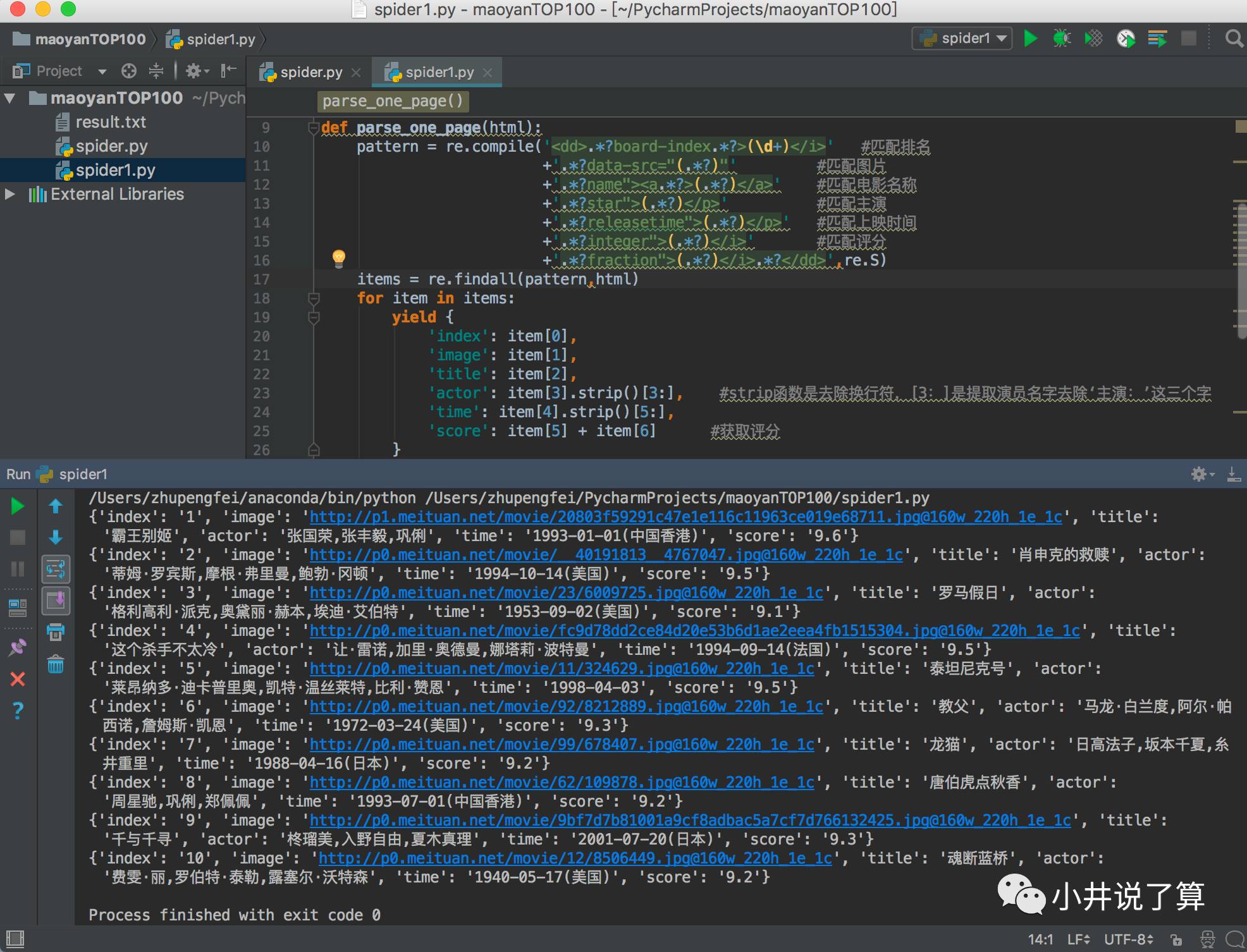
3.3 正则表达式分析
根据网站代码用正则表达式进行解析,获得我们想要的数据。
##正则表达式分析
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>' #匹配排名
+'.*?src="/img?url=(.*?)"' #匹配图片
+'.*?name"><a.*?>(.*?)</a>' #匹配电影名称
+'.*?star">(.*?)</p>' #匹配主演
+'.*?releasetime">(.*?)</p>' #匹配上映时间
+'.*?integer">(.*?)</i>' #匹配评分
+'.*?fraction">(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:], #strip函数是去除换行符,[3:]是提取演员名字去除‘主演:’这三个字
'time': item[4].strip()[5:],
'score': item[5] + item[6] #获取评分
}
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
if __name__ == '__main__':
main()
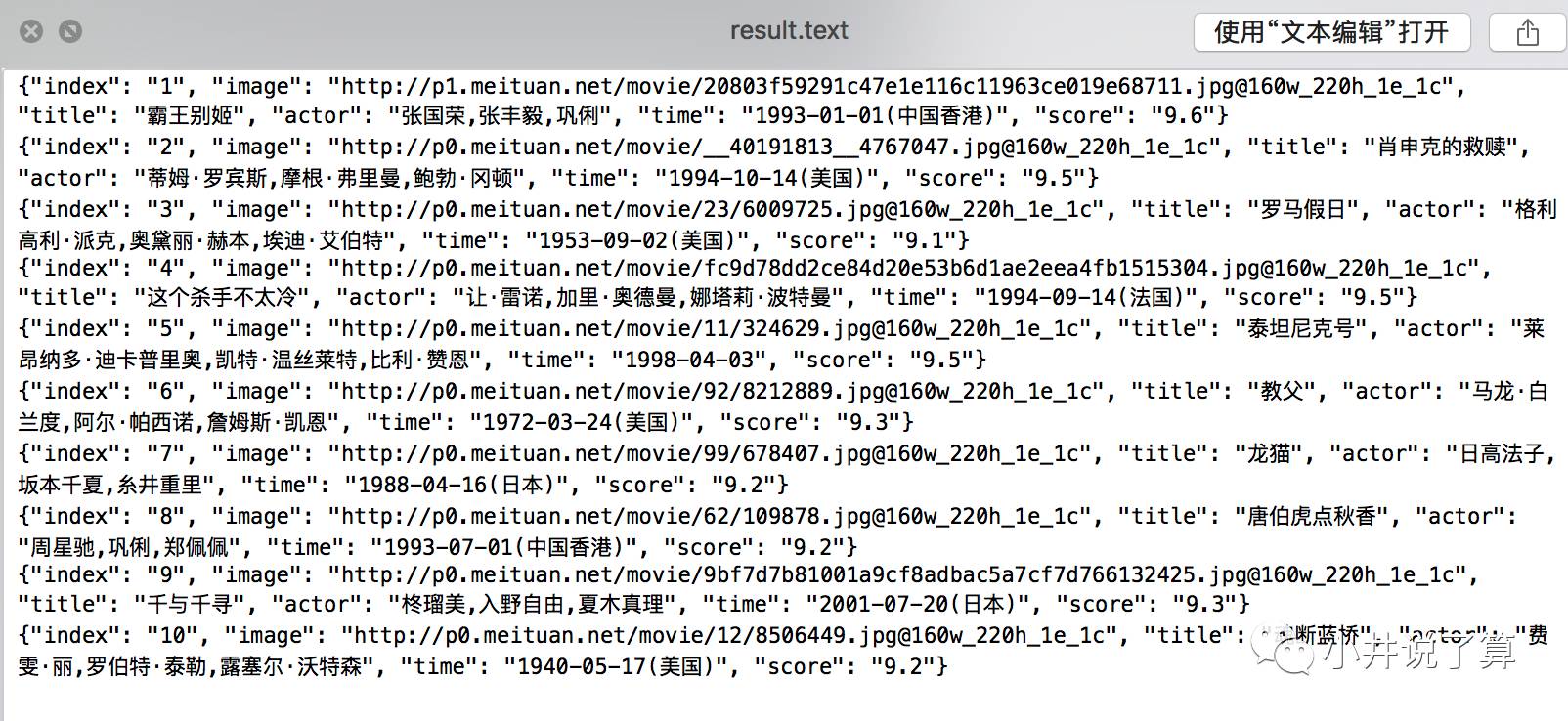
3.4 保存至文件
运行以下代码我们就实现了我们对猫眼TOP100的第一页抓取,并保存成text文档。
##保存至文件
import requests
import re
import json
###上同###
def write_to_file(content):
with open('result.text','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False) + '\n')
f.close()
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
main()
3.5 开启循环及多线程
但到目前为止我们只是对单页进行抓取,只获得了前10个电影的信息,继续对目标网站分析发现点击下一页网站的变化是,在原url后加了一个offset参数。
>http://maoyan.com/board/4
>http://maoyan.com/board/4?offset=10
>http://maoyan.com/board/4?offset=20
因此,对main()函数添加一个offset参数,我们就实现了对猫眼电影TOP100的抓取。
def main(offset):
url = 'https://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(i*10)
运行上面代码我们发现该爬虫是对目标网页一页一页依次进行抓取,运行时间有点长,我们要实现秒抓的话要引入多线程。这样就可以实现秒抓了。
##开启循环及多线程
from multiprocessing import Pool
if __name__ == '__main__':
# for i in range(10):
# main(i*10)
pool = Pool()
pool.map(main,[i*10 for i in range(10)])
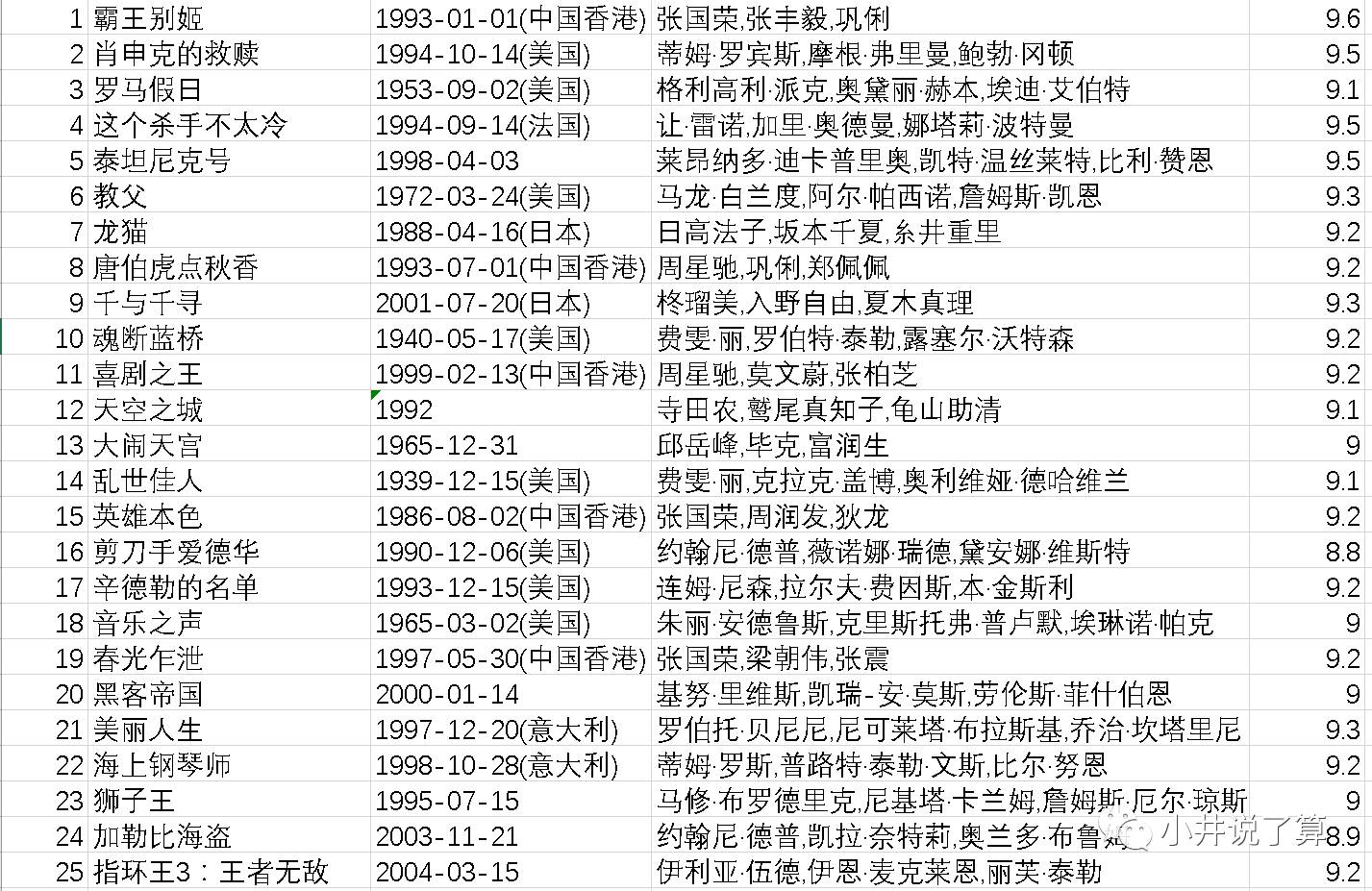
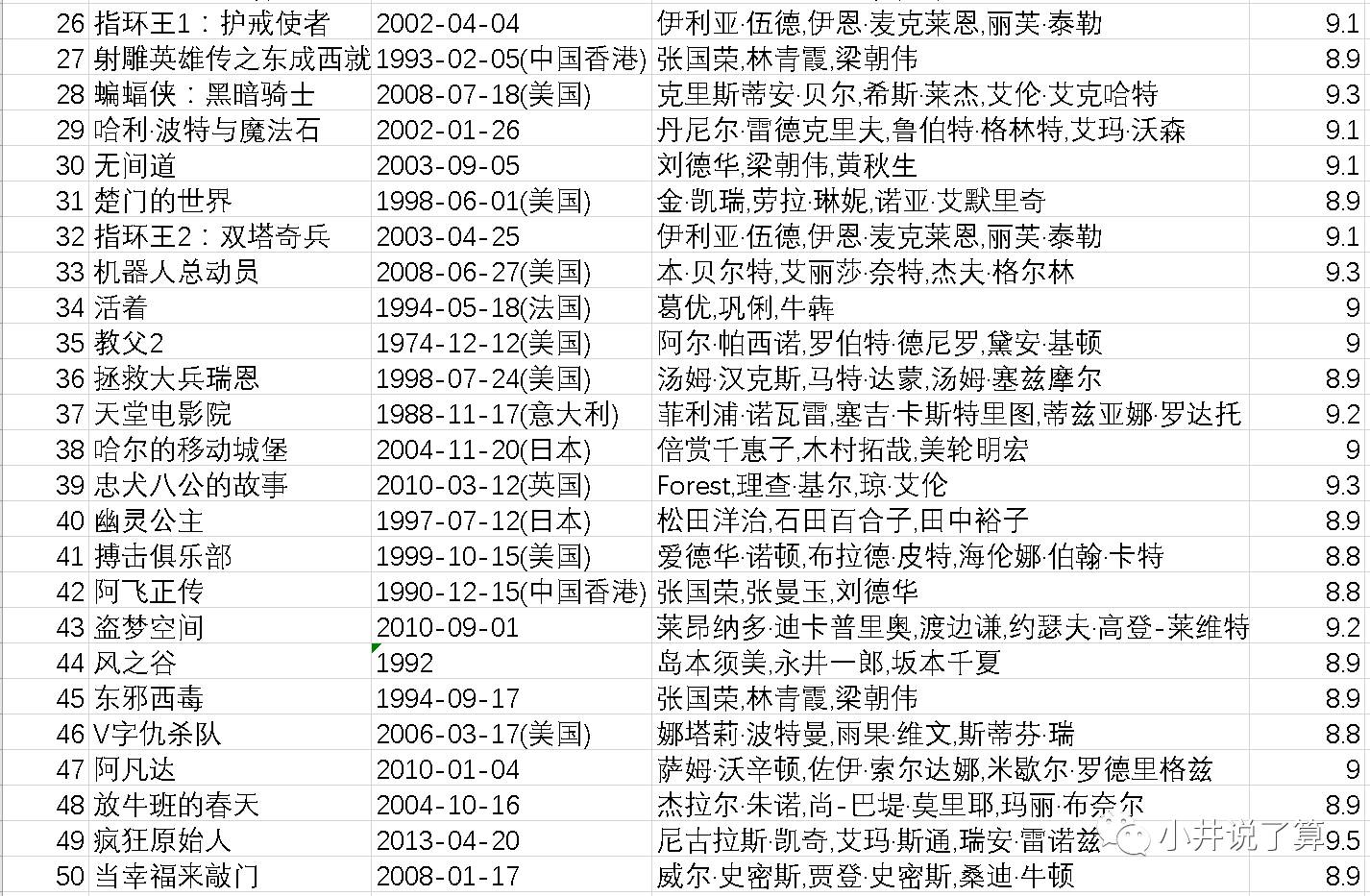
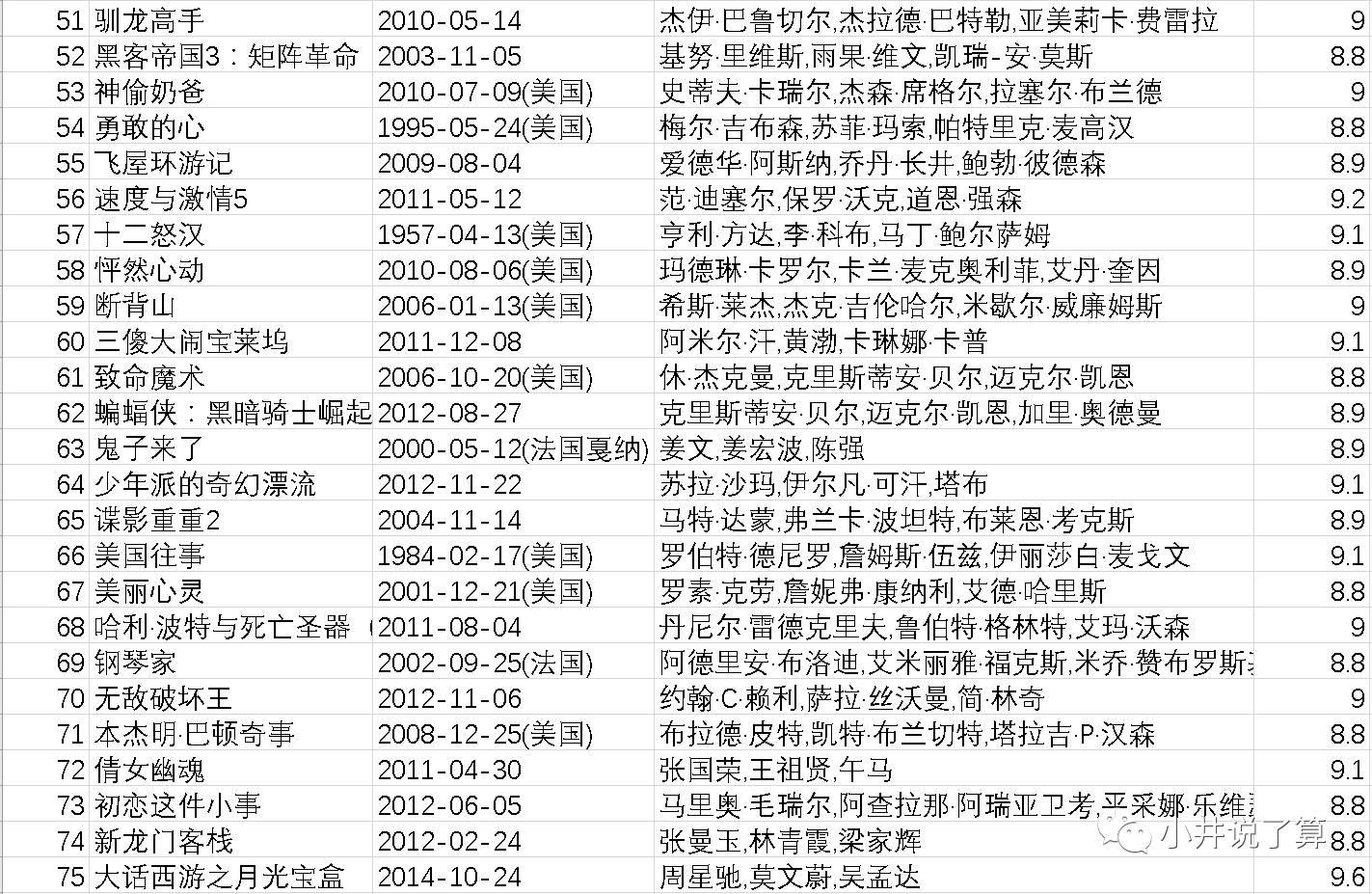
四、爬虫结果
最后,附上豆瓣排名前100的影片供大家茶余饭后观赏~
今天的分享到这就结束了,有需要完整代码或想抓取网页数据的小伙伴,请后台留言,小编将双手奉上~
小井说了算
以上是关于干货 | Requests+正则表达式爬取猫眼电影的主要内容,如果未能解决你的问题,请参考以下文章