有问必答:聊聊正则表达式里的转义字符
Posted 爬虫俱乐部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了有问必答:聊聊正则表达式里的转义字符相关的知识,希望对你有一定的参考价值。
hello!诸君安!
近日有位朋友问了这么一个问题:他想将形如’A|B’字符串中的B提取出来,但是使用正则表达式一直无法成功,这该怎么办呢?
爬虫君看到这个问题时心中暗喜,它看似简单,但却富有启发,下面让爬虫君细细说来。
匹配元字符本身?——转义
在正则表达式中,存在着一些“特殊字符”,我们称之为元字符。正则表达式元字符是代表着特殊含义的字符,包括基本元字符、数量元字符、位置元字符等,当用这些元字符匹配文本时,如果要表示“元字符”本身,而不是其代表的特殊含义,就需要对元字符进行转义,转义的方法也很简单,在正则表达式中的元字符前面加上”\”即可。
以下两个正则表达式,一个未对元字符转义,一个进行了转义。元字符”|”代表逻辑“或”操作符。
set obs 1
gen result="blue|glue"
gen result2=ustrregexs(1) if ustrregexm(result,"|(.*)")
gen result3=ustrregexs(1) if ustrregexm(result,"\|(.*)")
list
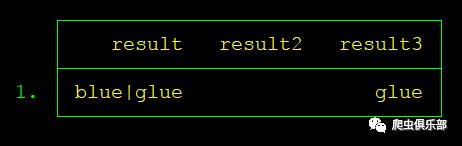
我们可以看到,未对元字符转义的正则表达式匹配失败,后者则匹配成功,匹配到了glue字符串。
现在我们来看一看这位粉丝的问题。
use "D:\stataABC\转义字符\PROVINCE_NAME.dta"
list
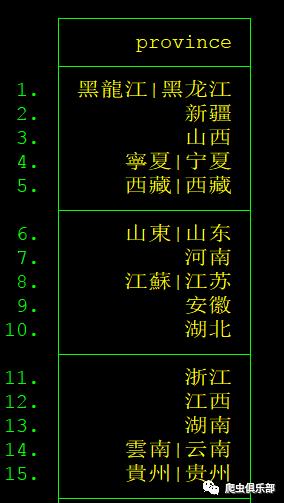
数据集给出了中国34个省级行政区域的名称,其中部分观测值的形式是 繁体|简体 现在我们只想要简体,而去掉繁体。 如果将表达式直接写成”|(.*)”的形式,则匹配不到字符串中的|字符,这也是粉丝反应的无法提取的原因。正确方案是对元字符|进行转义:
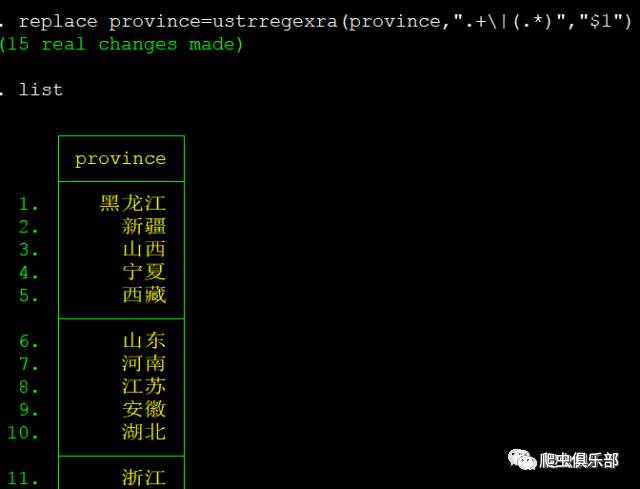
replace province=ustrregexs(1) if ustrregexm(province,"\|(.*)")
或者我们使用 ustrregexra 进行替换。
(1)replace province=ustrregexra(province,".+\| ","")
(2)replace province=ustrregexra(province,".+\|(.*)","$1")
ustrregexra是正则表达式替换函数,它将所有正则表达式匹配到的字符串都换成指定字符串,我们以上式为例,第一个参数(province)是要替换的变量,第二个参数(".+\| ")是正则表达式要匹配的文本,第三个参数是所要替换成的子字符串。
(1)式是将元字符|以及其之前的内容全部置换为空
(2)式使用回溯引用,$1表示将前面匹配到的文本替换成第一个子表达式(即(.*)里的内容)
split命令——更快更易懂
事实上,除了正则表达式,Stata还有更方便的命令处理类似的问题,它就是split。
split命令可以将指定变量内容依据给定的特殊字符进行自动分割,在处理上更加直观, 在这个问题中,我们以”|”作为分割的字符
use "D:\stataABC\转义字符\PROVINCE_NAME.dta"
split province,parse(|)
list
我们可以看到,由于部分观测值没有|符号,因此它们的简体字被归到了province1中,此时我们只需要将province2为空的观测值的province1的值赋给province2即可。
replace province2=province1 if province2==""
list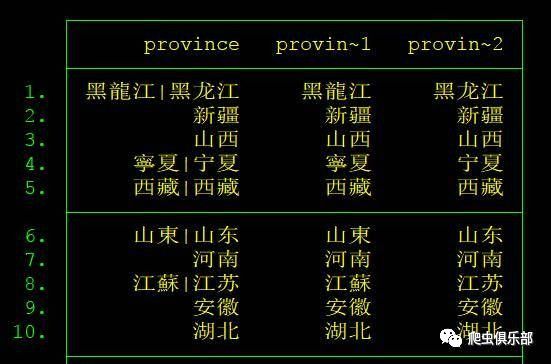

看不懂的记得戳下方视频哦~

注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
文字编辑:王凯丽
技术总编:刘贝贝
往期推文推荐:
关于我们
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
欢迎关注爬虫俱乐部
以上是关于有问必答:聊聊正则表达式里的转义字符的主要内容,如果未能解决你的问题,请参考以下文章