正则表达式原理
Posted 转转App技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式原理相关的知识,希望对你有一定的参考价值。
什么是正则表达式
工作中我们经常使用正则表达式来解决问题。正则表达式又称规则表达式,其实就是事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。它是一个强大便捷高效的文本处理工具,正则表达式可以添加、删除、分离、叠加、插入和修正各种类型的文本和数据。
正则表达式是一个工具,各种不同的语言对正则表达式可能都有着不同的实现。但是使用的方法大同小异,各个不同语言也有自己特有的特性和能力,需要我们在实际使用的过程中自己发掘。
正则表达式的原理
正则表达式应用到目标字符串大致分为下面几步:
1、正则表达式编译。
2、引擎传动开始
3、元素检查
4、寻找匹配结果(成功则结束)
5、引擎传动装置驱动(下一个字符开始,回到3)
6、匹配彻底失败(结束)
我们知道正则表达式其实是一个“字符串”,因此编译和引擎是什么呢?其实计算机在实际使用正则表达式的时候,并不是直接使用这个字符串,而是通过编译翻译成特定的机器,这个机器就是我们所说的引擎。
这个引擎分为两种,NFA(非确定型有穷自动机)和DFA(确定型有穷自动机),有印象吗?学过编译原理的同学们?没学过或者忘了也不要紧。下面我们一起来学习下这两种机器吧。
正则表达式引擎
我们通过一个例子来看看NFA和DFA有哪些不同吧。
对于正则表达式:(a|b)*abb来说,NFA和DFA的示意图如下:
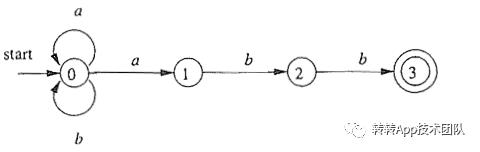
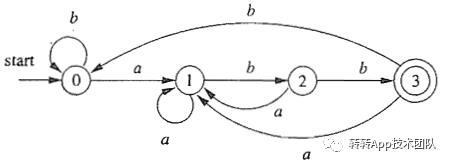
怎么样,是不是有点懵懵的呢?
对于一个正则表达式来说通常情况下有三种形式:ab(连接),a|b(或),a* (0到多个a)。对应的三种形态:
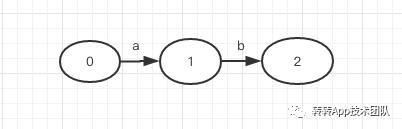
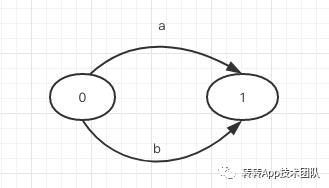
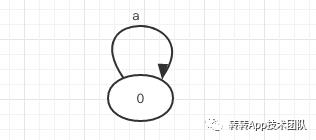
基于这三种基本的形态,根据正则表达式,我们很容易画出NFA的模型。

那么DFA就是确定型有穷自动机,不管输入什么我们都可以得到一个确定的状态,但是DFA又该如何得到呢?
DFA需要通过NFA推导出来。
1、首先我们开始的状态是0
2、0状态可以输入a和b,我们先输入a,这时可以得到0状态或者1状态。我们把这个状态成为一个新的状态(0,1),这个状态是状态0和状态1的集合态。然后状态0输入b得到的还是状态0。
3、然后看(0,1)状态。根据NFA的图,我们发现0可以输入a和b,1可以输入b,因此(0,1)可以输入a和b。输入a可以得到0和1,输入b可以得到0和2。因此(0,1)输入得到的还是(0,1),输入b得到(0,2)。
4、根据上述规律继续推导,我们得到下面的图。

这时我们现在只有0,(0,1),(0,2),(0,3)这四种状态,改变下状态的名称就得到了最开始的DFA的状态图。
当然这只是个简单的例子,实际中式子可能会非常复杂,DFA的状态数可能会远远大于NFA的总状态数。
那么NFA和DFA各自有什么特点,对于正则表达式又有什么影响呢?
NFA与DFA
编译速度:
通过上述的NFA和DFA的原理我们可以看到,NFA的状态数与正则表达式的长度有关系,而DFA的状态数最大可能是NFA状态数的排列组合之和。因此DFA编译起来要比NFA复杂的多。
匹配速度:
在输入一个字符之后,NFA可能到达的状态不一样,这时候需要进行选择,加入刚开始选择的分支最终无法匹配,那么我们需要重新回退到这个选择,选择另一个分支进行匹配。这就产生了回溯。而DFA到达的状态是确定的,因此只需要匹配一遍字符串就可以得到结果。虽然DFA有编译上的损耗,但是通常情况下回溯的损耗比较大,因此匹配上速度上DFA胜。
其他对比:
根据NFA和DFA的特点,我们还可以知道一些其他的对比情况,感兴趣的读者可以去查相关的资料。
最终两者的比较如下表:

现在大部分的语言都是基于NFA的,因为它支持的功能更全面。
匹配过程
NFA其实是表达式主导的,每次先检查正则的一部分,当遇到分歧时,先检查一个路径如果适合则匹配,如果不适合,则回退到分歧点进行另一部分的匹配,因此要检查的文本字符可能被检查多次,这就是回溯;
回溯(或者说选择路径)的原则有两个:1、优先量词还是忽略量词,2、LIFO。后进先出,回溯到最近的储存的路径。
DFA是文本主导的,扫描字符时,会记录”当前有效“的所有匹配可能,尽可能多的匹配字符串。例如:DFA中,today去匹配to(day)?这样的字符串,最终匹配出来的就是today。如果是toda去匹配则会得到to。DFA中每个字符只会匹配一次。
还是以(a|b)*abb这个为例,我们用分别用NFA和DFA来匹配babb这个字符串。
假设我们的NFA实现是以量词优先。
1、起始状态0,输入b得到状态0
2、状态0,输入a可以得到0或者1,我们先记住这次选择的路径,由于是量词优先,我们选择跳到状态0
3、状态0,输入b得到0
4、状态0,输入b得到0,输入完毕,0不是最终态,回退到之前的分叉2
5、状态0,输入a,由于选过0,这次选择到达状态1。
6、状态1,输入b,得到状态2
7、状态2,输入b,得到状态3,输入完毕,3是最终态,匹配成功。
DFA匹配:
1、起始状态0,输入b得到状态0
2、状态0,输入a得到状态1
3、状态1,输入b得到状态2
4、状态2,输入b得到状态3,输入完毕,状态3是最终态,匹配成功。
总结
正则表达式一直在用,但是一直也没有研究过正则表达式是怎么实现的。因为之前看到过有人说正则表达式的匹配可能会卡进程,刚开始不太相信,经过这次的学习总结,了解了正则表达式的原理,发现原来正则表达式的写法真的会影响性能(由于大部分语言的实现都是基于NFA的)。这一篇先介绍原理,之后有时间会再出一篇,大家一块研究探讨下如何提高正则表达式的效率。
以上是关于正则表达式原理的主要内容,如果未能解决你的问题,请参考以下文章