正则表达式之匹配汉字
Posted 爬虫俱乐部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式之匹配汉字相关的知识,希望对你有一定的参考价值。
我们知道stata14是采用Unicode 编码。Unicode 是全球文字统一编码。它把世界上的各种文字的每一个字符指定唯一编码,实现跨语种、跨平台的应用。中文用户最常接触的是汉字 Unicode 编码。中文字符数量巨大,日常使用的汉字数量有数千个,再加上生僻字,数量达到数万个。那么每一个字符都有一个Unicode码,如果我们知道每一个汉字的编码,是不是就可以用字符串函数匹配到汉字了呢?
在Stata中有ustrunescape(s)和ustrtohex(s[,n]) 两个函数可以实现Unicode转义字符的解码与编码。
1.ustrunescape(s):将unicode转义字符s进行解码。
2.ustrtohex(s[,n]):将字符s从第n个unicode字符开始进行编码,转换成unicode转义字符。
dis ustrtohex("爬虫俱乐部") // 将"爬虫俱乐部"进行编码,转换为unicode转义字符
dis ustrunescape("\u722c\u866b\u4ff1\u4e50\u90e8") //对 unicode转义字符进行解码
dis ustrtohex("爬虫俱乐部",2) // 将"爬虫俱乐部"从第二个unicode字符开始进行编码,相当于对"虫俱乐部"进行编码
Unicode转义字符是以“\uXXXX”格式表示的字符,其中X为16进制数字。unicode转义字符在许多领域,尤其是Web前端开发中,有广泛的应用。
Unicode转义字符可以直接用于正则表达式中,例如0-9的unicode转义字符为\u0030-\u0039,\d即[0-9]可以表示为[\u0030-\u0039]。通过unicode转义字符,我们可以匹配任一unicode码区间内的任一字符。比如基本汉字的unicode转义字符的范围为\u4e00-\u9fa5。在一些软件里面,[\u4e00-\u9fa5]是规定的匹配汉字的元字符,不能更换范围,但Stata中可以指定具体的范围。类比于[\u0030-\u0039]对应[0-9], [\u4e00-\u9fa5]也可以替换为[一-龥]来匹配任一基本汉字。
一般情况下,基本汉字是可以解决问题的,当然还有基本汉字补充等一些不常用的汉字。
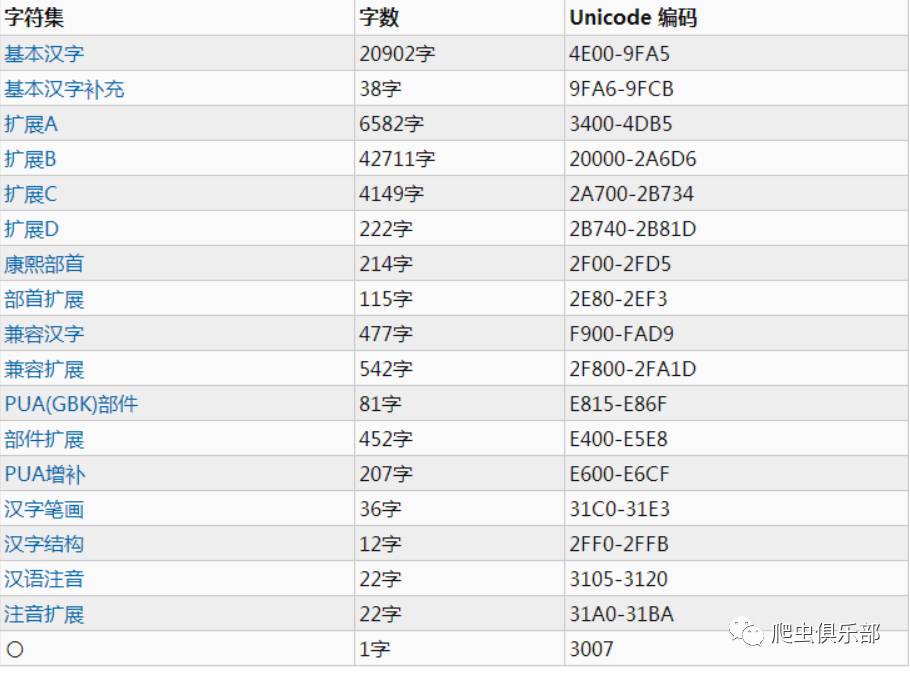
这里除了基本汉字,其他的都是很生僻的字,一般涉及不到,用这两万多的基本汉字已经足够了。例如扩展A:

为了方便大家尝试,我们手动输入一个数据,程序如下:
clear
set more off
input str40 v
ShangHai上海财经大学636
HuBei中南财经政法大学588
SiChuan西南财经大学590
BeiJing中央财经大学630
BeiJing对外经济贸易大学633
LiaoNing东北财经大学579
BeiJing首都经济贸易大学572
JiangXi江西财经大学566
ZheJiang浙江工商大学561
BeiJing北京工商大学568
end
结果如下:
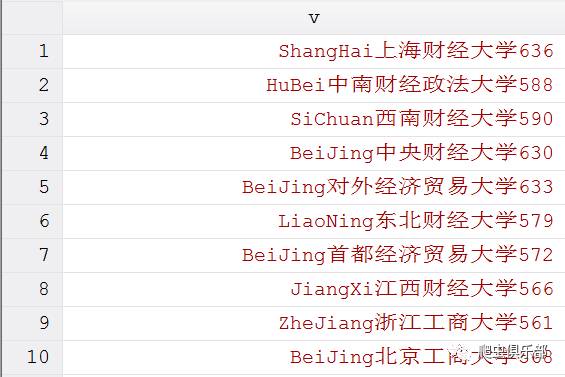
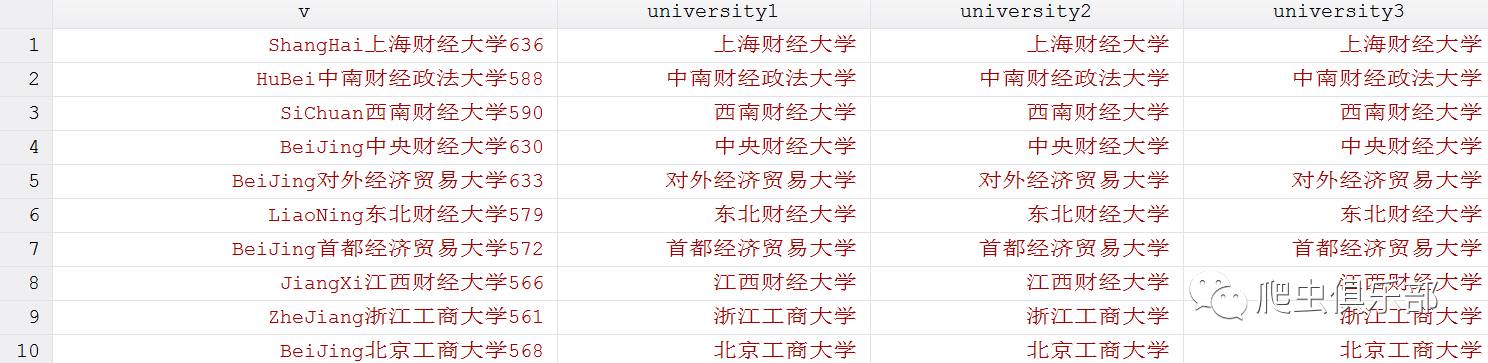
这个数据是10所财经类院校2015年湖北省的理科录取分数线。现在我们需要把学校名称提取出来,按照往常的做法我们可以通过以下程序来实现这一目的:
gen university1= ustrregexs(1) if ustrregexm(v,"[a-zA-Z]+(.+?)\d")
运行结果如下:
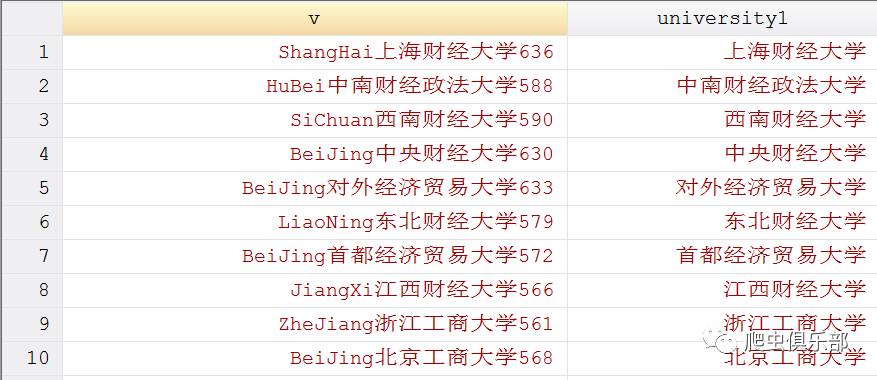
其中,[a-zA-Z]+表示学校所在地,如第一行的ShangHai。\d便是分数线的第一位数字,如第一行的“6”。那么子表达式(.+?)就表示学校所在地与分数线中间的部分,即学校名称。
还有没有其他办法了呢?你要知道,我们现在可是会用stata匹配汉字啦!另外,我们发现学校所在地和分数线分别是英文字符和数字字符,只有学校名称是汉字。因此,我们可以通过直接提取汉字来获取学校名称。
程序如下:
gen university2 = ustrregexs(0) if ustrregexm(v,"[\u4e00-\u9fa5]+")
执行结果如下:
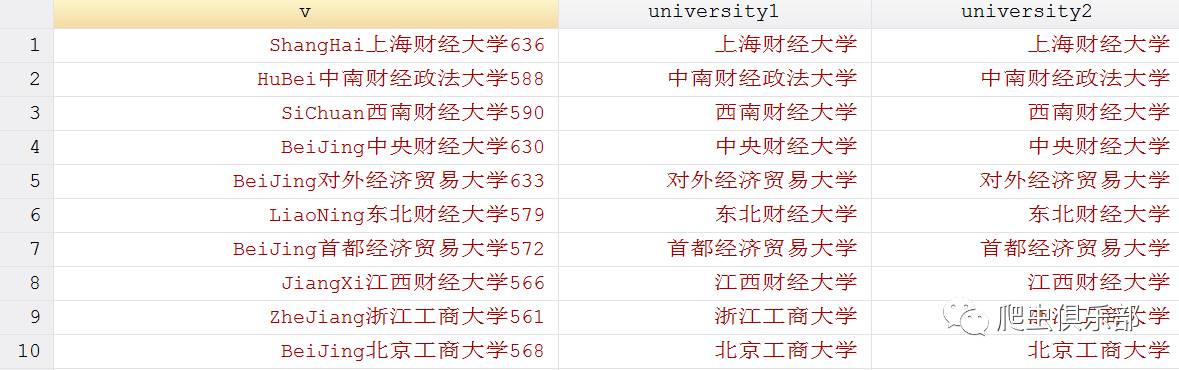
我们看到,两次的结果是一样的。其中,[\u4e00-\u9fa5]表示所有基本汉字的unicode转义字符,其可以匹配到基本汉字。我们前边讲到, [\u4e00-\u9fa5]也可以替换为[一-龥]来匹配任一基本汉字,程序如下:
gen university3 = ustrregexs(0) if ustrregexm(v,"[一-龥]+")
执行结果如下:
接下来是空气质量报告
全国空气质量如下

河北的朋友们珍重
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~,点赞打赏随您心意,么么哒~
编辑by强宇曦
往期推文推荐:
2
3
4
5
6
7
8
9.
关于我们
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
欢迎关注爬虫俱乐部
以上是关于正则表达式之匹配汉字的主要内容,如果未能解决你的问题,请参考以下文章