众里寻她千百度,正则表达式
Posted Python开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了众里寻她千百度,正则表达式相关的知识,希望对你有一定的参考价值。
来源:伯乐在线专栏作者 - selfboot
链接:http://python.jobbole.com/86553/
先来看一个让人震撼的小故事,故事来自知乎问题PC用户的哪些行为让你当时就震惊了?(http://www.zhihu.com/question/20100408)
同学在一个化妆品公司上班,旁边一个大妈(四十多岁)发给他一个exl表,让他在里面帮忙找一个经销商的资料。
表格里面大约有几百个客户资料,我同学直接筛选填入信息,然后没找到,就转头告诉大妈,说这个表里没有。
大妈很严厉的批评了我同学,说年轻人干工作一定要沉的住气,心浮气躁可不行。这才几分钟啊,我才看了二十行,你怎么就找完了。
同学过去一看,大妈在一行一行的精挑细选,顿时一身冷汗。把筛选办法告知后,大妈不但不领情,还召集办公司其他老职员,一起声讨我同学,我们平时都是这么找的,你肯定是偷工减料,我们找一个小时没找完,你几分钟就找完了。
不知道是否确有此事,不过看起来好吓人的样子。仔细想想,大多数人都是用以往的经验来分析遇见的新问题的。就上面的大妈而言,在接触计算机之前的几十年里,她面对的都是纸质的客户资料,此时,要查找某一客户资料,只能一行一行看下去了。
现在,虽然有了计算机,但是只是简单的把它看做一个比较大的纸质资料库罢了,并没有认识到计算机的强大之处。这里的强大主要就是说计算机在处理电子文档时的强大的搜索功能了。
当然,对于大部分年轻人来说,计算机中的搜索功能是再熟悉不过了。我们可以在word、excel、网页中搜索特定内容,可以在整个计算机文件系统中搜索文件名,甚至搜索文件中的内容(Win下的everthing,Mac下的Spotlight)。
这些搜索主要用到了两种技术:
正则表达式
数据库索引
这里我们先介绍一下正则表达式。
正则表达式介绍
简单来说,正则表达式就是用来匹配特定内容的字符串。举个例子来讲,如果我想找出由a、b组成的,以abb结尾的字符串,比如ababb,那么用正则表达式来表示就是[ab]*abb。
正则表达的理念是由数学家Stephen Kleene在1950年首次提出来的,开始时主要用于UNIX下文本编辑器ed和过滤器grep中。1968年开始广泛应用于文本编辑器中的模式匹配和编译器中的词法分析。1980年,一些复杂的正则表达语句开始出现在Perl中,使用了由Henry Spencer实现的正则表达解析器。而Henry Spencer后来写了更高效的正则解析器Tcl,Tcl混合使用了NFA(非确定有限自动机)/DFA(确定有限自动机)来实现正则表达语法。
正则表达式有以下优点:
容易理解
能高效实现
具有坚实的理论基础
正则表达式的语法十分简单,虽然各种编程语言在正则表达式的语法上有细节上的区别,不过主要部分如下:
[a-z]表示所有小写字母,[0-9]表示所有数字,[amk]表示a、m或k。
+表示字符重复1或者多次,*表示字符重复0或者多次。在使用+或者*时,正则表达式遵从maximal munch的原则,也就是说它匹配能够匹配到的最大字符串。
a|z 表示匹配字符’a’或者’z’
?表示字符出现0次或者1次
是正则表达式中的escape符号,\*表示的就是’*’这个字符,而不是它在正则表达式中的功能。
. 表示出了换行符之外的任何字符,而^表示出了紧接它的字符以外的任何字符
^ 匹配字符串的开始,$ 匹配字符串的结尾。
回到我们前面的例子中,我们用正则表达式[ab]*abb来匹配由a、b组成的,以abb结尾的字符串。这里[ab]*abb即可以这样解读:a或者b重复0或者多次,然后是abb的字符串。
下面用python在”aababbaxz abcabb abbbbabb”中搜索[ab]*abb:
import re
content = "aababbaxz abcabb abbbbabb"
pattern = re.compile("[a|b]*abb")
print pattern.findall(content)
# outputs: ['aababb', 'abb', 'abbbbabb']
其实,正则表达式不只用于文本搜索和模糊匹配,还可以用于以下场景:
合法性检查
文本的自动更正和编辑
信息提取
正则表达式实现原理
正则表达式便于我们理解使用,但是如何让计算机识别用正则表达式描述的语言呢?仍然以前面的[a|b]*abb为例,计算机如何识别[a|b]*abb的意义呢?首先我们来看判断输入内容是否匹配正则表达式的流程图:
图中一共有4个状态S0, S1, S2, S3,在每个状态基础上输入字符a或者b就会进入下一个状态。如果经过一系列输入,最终如果能达到状态S3,则输入内容一定满足正则表达式[a|b]*abb。
为了更清晰表述问题,将上图转换为状态转换表,第一列为当前状态,第二列为输入a后当前状态的跳转,第三列为输入b后当前状态的跳转。其中S0为起始状态,S3为接受状态,从起始状态起经过一系列输入到达接受状态,那么输入内容即满足[a|b]*abb。
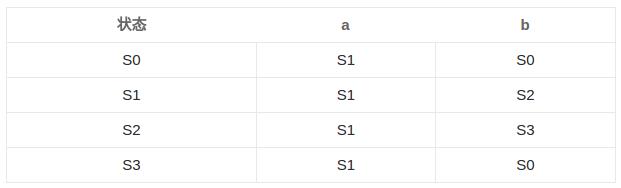
其实上图就是一个DFA实例(确定有限自动机),下面给出DFA较为严格的定义。一个确定的有穷自动机(DFA) M 是一个五元组:M = (K, ∑, f, S, Z),其中:
K是一个有穷集,它的每个元素称为一个状态;
∑是一个有穷字母表,它的每个元素称为一个输入符号,所以也称∑为输入符号表;
f是转换函数,是在K×∑→K上的映射,如f(ki, a)→kj,ki∈K,kj∈K就意味着当前状态为ki,输入符号为a时,将转换为下一个状态kj,我们将kj称作ki的一个后继状态;
S∈K是唯一的一个初态;
Z⊆K是一个状态集,为可接受状态或者结束状态。
DFA的确定性表现在转换函数f:K×∑→K是一个单值函数,也就是说对任何状态ki∈K和输入符号a∈∑,f(k, a)唯一地确定了下一个状态,因此DFA很容易用程序来模拟。
下面用字典实现[a|b]*abb的确定有限自动机,然后判断输入字符串是否满足正则表达式。
DFA_func = {0: {"a": 1, "b": 0},
1: {"a": 1, "b": 2},
2: {"a": 1, "b": 3},
3: {"a": 1, "b": 0}
}
input_symbol = ["a", "b"]
current_state = 0
accept_state = 3
strings = ["ababaaabb",
"ababcaabb",
"abbab"]
for string in strings:
for char in string:
if char not in input_symbol:
break
else:
current_state = DFA_func[current_state][char]
if current_state == 3:
print string, "---> Match!"
else:
print string, "--->No match!"
current_state = 0
"""outputs:
ababaaabb ---> Match!
ababcaabb --->No match!
abbab --->No match!
"""
上面的例子可以看出DFA识别语言简单直接,便于用程序实现,但是DFA较难从正则表达式直接转换。如果我们能找到一种表达方式,用以连接正则表达式和DFA,那么就可以让计算机识别正则表达式了。事实上,确实有这么一种表达方式,可以作为正则表达式和DFA的桥梁,而且很类似DFA,那就是非确定有限自动机(NFA)。
还是上面的例子,如果用NFA表示流程图,就如下图所示:
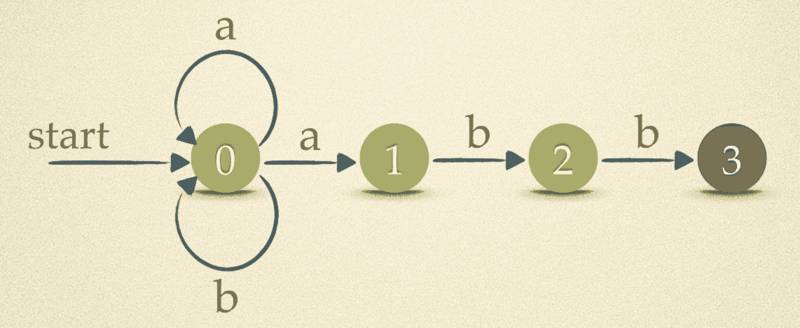
看上去很直观,很有[a|b]*abb的神韵。它转换为状态转换表如下:

NFA的定义与DFA区别不大,M = (K, ∑, f, S, Z),其中:
K是一个有穷集,它的每个元素称为一个状态;
∑是一个有穷字母表,它的每个元素称为一个输入符号,ε表示输入为空,且ε不存在于∑;
f是转换函数,是在K×∑*→K上的映射,∑*说明存在遇到ε的情况,f(ki, a)是一个多值函数;
S∈K是唯一的一个初态;
Z⊆K是一个状态集,为可接受状态或者结束状态。
数学上已经证明:
DFA,NFA和正则表达式三者的描述能力是一样的。
正则表达式可以转换为NFA,已经有成熟的算法实现这一转换。
NFA可以转换为DFA,也有完美的实现。
这里不做过多陈述,想了解详情可以参考《编译原理》一书。至此,计算机识别正则表达式的过程可以简化为:正则表达式→NFA→DFA。不过有时候NFA转换为DFA可能导致状态空间的指数增长,因此直接用NFA识别正则表达式。
正则表达式应用实例
前面已经使用python的re模块,简单展示了正则表达式[ab]*abb的匹配过程。下面将结合几个常用的正则表达式例子,展示正则表达式的强大之处。
开始之前,先来看下python中正则表达的一些规定。
\w 匹配单词字符,即[a-zA-Z0-9_],\W 则恰好相反,匹配[^a-zA-Z0-9_];
\s 匹配单个的空白字符:space, newline(\n), return(\r), tab(\t), form(\f),即[ \n\r\t\f\v],\S 相反。
\d 匹配数字[0-9],\D 恰好相反,匹配[^0-9]。
(…P<name>…) 会产生一个分组,在后面需要时可以用数组下标引用。
(?P…) 会产生命名组,需要时直接用名字引用。
(?!…) 当…不出现时匹配,这叫做后向界定符
r”pattern” 此时pattern为原始字符串,其中的”\”不做特殊处理,r”\n” 匹配包含”\”和”n”两个字符的字符串,而不是匹配新行。当一个字符串是原始类型时,Python编译器不会对其尝试做任何的替换。关于原始字符串更多的内容可以看stackflow上问题Python regex – r prefix(https://stackoverflow.com/questions/2241600/python-regex-r-prefix)
python中常用到的正则表达式函数主要有re.search, re.match, re.findall, re.sub, re.split。
re.findall: 返回所有匹配搜索模式的字符串组成的列表;
re.search: 搜索字符串直到找到匹配模式的字符串,然后返回一个re.MatchObject对象,否则返回None;
re.match: 如果从头开始的一段字符匹配搜索模式,返回re.MatchObject对象,否则返回None。
re.sub(pattern, repl, string, count=0, flags=0): 返回repl替换pattern后的字符串。
re.split: 在pattern出现的地方分割字符串。
re.search和re.match均可指定开始搜索和结束搜索的位置,即re.search(string[, pos[, endpos]])和re.match(string[, pos[, endpos]]),此时从pos搜索到endpos。需要注意的是,match总是从起始位置匹配,而search则从起始位置扫描直到遇到匹配。
re.MatchObject默认有一个boolean值True,match()和search()在没有找到匹配时均返回None,因此可以用简单的if语句判断是否匹配。
match = re.search(pattern, string)
if match:
process(match)
re.MatchObject对象主要有以下方法:group([group1, …])和groups([default])。group返回一个或多个分组,groups返回包含所有分组的元组。
例子1:匹配Hello,当且仅当后面没有紧跟着World。
strings = ["HelloWorld!",
"Hello World!"]
import re
pattern = re.compile(r"Hello(?!World).*")
for string in strings:
result = pattern.search(string)
if result:
print string, "> ", result.group()
else:
print string, "> ", "Not match"
'''
outputs:
HelloWorld! > Not match
Hello World! > Hello World!
'''
content = """
alice@google.com
alice-bob@gmail.._com gmail
alice.bob@apple.com apple
alice.bob@gmailcom invalid gmail
"""
import re
address = re.compile(r'[\w.-]+@[\w-]+\.[\w.-]+')
print address.findall(content)
'''
outpus:
['alice@google.com', 'alice-bob@gmail.._com', 'alice.bob@apple.com']
'''
例子3:给函数添加装饰器。
original = """
def runaway():
print "running away..."
"""
import re
pattern = re.compile(r"def (\w+\(\):)")
wrapped = pattern.sub(r"@get_car\ndef \1", original)
print original, "--->", wrapped, "----"
"""outputs
def runaway():
print "running away..."
--->
@get_car
def runaway():
print "running away..."
----
"""
看起来正则表达式似乎无所不能,但是并不是所有的场合都适合用正则表达式,许多情况下我们可以找到替代的工具。比如我们想解析一个html网页,这时候应该使用使用 HTML 解析器,stackflow上有一个答案(https://stackoverflow.com/questions/1732348/regex-match-open-tags-except-xhtml-self-contained-tags)告诉你此时为什么不要使用正则表达式。python有很多html解析器,比如:
BeautifulSoup 是一个流行的第三方库
lxml 是一个功能齐全基于 c 的快速的库
参考
Wiki: Regular expression
正则表达式和有限状态机
Python Regular Expressions
Python check for valid email address?
Python正则表达式的七个使用范例
高级正则表达式技术
编译原理: 有穷自动机
专栏作者简介 ( )
selfboot:热爱计算机技术的学生...书中寻求心灵的平静...selfboot,自启动,只有自己能启动自己所以不要寄希望于别人,自我蜕变展翅飞翔吧!
打赏支持作者写出更多好文章,谢谢!
关注「Python开发者」
看更多精选技术文章
↓↓↓
以上是关于众里寻她千百度,正则表达式的主要内容,如果未能解决你的问题,请参考以下文章