C++ 中也能使用的正则表达式
Posted CPP开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++ 中也能使用的正则表达式相关的知识,希望对你有一定的参考价值。
来源:我是一只C++小小鸟,2015-10-05
www.cnblogs.com/ittinybird/p/4853532.html
如有好的文章
正则表达式Regex(regular expression)是一种强大的描述字符序列的工具。在许多语言中都存在着正则表达式,C++11中也将正则表达式纳入了新标准的一部分,不仅如此,它还支持了6种不同的正则表达式的语法,分别是:ECMASCRIPT、basic、extended、awk、grep和egrep。其中ECMASCRIPT是默认的语法,具体使用哪种语法我们可以在构造正则表达式的时候指定。
注:ECMAScript是一种由Ecma国际(前身为欧洲计算机制造商协会,英文名称是European Computer Manufacturers Association)通过ECMA-262标准化的脚本程序设计语言。它往往被称为javascript,但实际上后者是ECMA-262标准的实现和扩展。
下面我们就以本篇博客的页面(http://www.cnblogs.com/ittinybird/p/4853532.html)源码为例,从零开始演示如何在C++中使用正则表达式提取一个网页源码中所有可用的http链接。如果有时间的话,近期我想用C++11的新特性,改写一下以前的C++爬虫程序,分享出来。
确保你的编译器支持 Regex
如果你的编译器是GCC-4.9.0或者VS2013以下版本,请升级后,再使用。我之前使用的C++编译器,是GCC 4.8.3,有regex头文件,但是GCC很不厚道的没有实现,语法完全支持,但是库还没跟上,所以编译的时候是没有问题的,但是一运行就会直接抛出异常,非常完美的一个坑有木有!具体错误如下:
terminate called after throwing an instance of 'std::regex_error'
what(): regex_error
Aborted (core dumped)
如果你也遇到了这个问题,请不要先怀疑自己,GCC这一点是非常坑爹的!!!我在这个上面浪费了半天的时间才找了出来。所以在尝鲜C++的正则表达式之前,请升级你的编译器,确保你的编译器支持它。
regex 库概览
在头文件<regex>中包含了多个我们使用正则表达式时需要用到的组件,大致有:
ECMASCRIPT正则表达式语法
正则表达式式的语法基本大同小异,在这里就浪费篇幅细抠了。ECMASCRIPT正则表达式的语法知识可以参考W3CSCHOOL。
构造正则表达式
构造正则表达式用到一个类:basic_regex。basic_regex是一个正则表达式的通用类模板,对char和wchar_t类型都有对应的特化:
typedef basic_regex<char> regex;
typedef basic_regex<wchar_t> wregex;
构造函数比较多,但是非常简单:
//默认构造函数,将匹配任何的字符序列
basic_regex();
//用一个以‘\0’结束的字符串s构造一个正则表达式
explicit basic_regex( const CharT* s,flag_type f =std::regex_constants::ECMAScript );
//同上,但是制定了用于构造的字符串s的长度为count
basic_regex( const CharT* s, std::size_t count,flag_type f = std::regex_constants::ECMAScript );
//拷贝构造,不赘述
basic_regex( const basic_regex& other );
//移动构造函数
basic_regex( basic_regex&& other );
//以basic_string类型的str构造正则表达式
template< class ST, class SA >
explicit basic_regex( const std::basic_string<CharT,ST,SA>& str, flag_type f = std::regex_constants::ECMAScript );
//指定范围[first,last)内的字符串构造正则表达式
template< class ForwardIt >
basic_regex( ForwardIt first, ForwardIt last, flag_type f = std::regex_constants::ECMAScript );
//使用initializer_list构造
basic_regex( std::initializer_list<CharT> init, flag_type f = std::regex_constants::ECMAScript );
以上除默认构造之外的构造函数,都有一个flag_type类型的参数用于指定正则表达式的语法,ECMASCRIPT、basic、extended、awk、grep和egrep均是可选的值。除此之外还有其他几种可能的的标志,用于改变正则表达式匹配时的规则和行为:
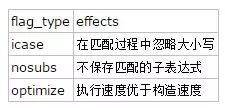
有了构造函数之后,现在我们就可以先构造出一个提取http链接的正则表达式:
std::string pattern("http(s)?://([\\w-]+\\.)+[\\w-]+(/[\\w- ./?%&=]*)?"); //匹配规则很简单,如果有疑惑,可以对照语法查看
std::regex r(pattern);
值得一提的是在C++中’\’这个字符需要转义,因此所有ECMASCRIPT正则表达式语法中的’\’都需要写成“\\”的形式。我测试的时候,这段regex如果没有加转义,在gcc中会给出警告提示,vs2013编译后后运行直接崩溃了。
正确地处理输入
先扯一个题外话,假设我们不是使用了网络库自动在程序中下载的网页,在我们手动下载了网页并保存到文件后,首先我们要做的还是先把网页的内容(html源码)存入一个std::string中,我们可能会使用这样的错误方式:
int main()
{
std::string tmp,html;
while(std::cin >> tmp)
html += tmp;
}
这样一来源代码中所有的空白字符就无意中被我们全处理了,这显然不合适。这里我们还是使用getline()这个函数来处理:
int main()
{
std::string tmp,html;
while(getline(std::cin,tmp))
{
html += tmp;
html += '\n';
}
}
这样一来原来的文本才能得到正确的输入。当然个人以为这些小细节还是值得注意的,到时候出错debug的时候,我想我们更多地怀疑的是自己的正则表达式是否是有效。
regex_search() 只查找到第一个匹配的子序列
根据函数的字面语义,我们可能会错误的选择regex_search()这个函数来进行匹配。其函数原型也有6个重载的版本,用法也是大同小异,函数返回值是bool值,成功返回true,失败返回false。鉴于篇幅,我们只看我们下面要使用的这个:
template< class STraits, class SAlloc,class Alloc, class CharT, class Traits >
bool regex_search( const std::basic_string<CharT,STraits,SAlloc>& s,
std::match_results<typename std::basic_string<CharT,STraits,SAlloc>::const_iterator, Alloc>& m,
const std::basic_regex<CharT, Traits>& e,
std::regex_constants::match_flag_type flags = std::regex_constants::match_default );
第一个参数s是std::basic_string类型的,它是我们待匹配的字符序列,参数m是一个match_results的容器用于存放匹配到的结果,参数e则是用来存放我们之前构造的正则表达式对象。flags参数值得一提,它的类型是std::regex_constants::match_flag_type,语义上匹配标志的意思。正如在构造正则表达式对象时我们可以指定选项如何处理正则表达式一样,在匹配的过程中我们依然可以指定另外的标志来控制匹配的规则。这些标志的具体含义,我从cppreference.com 引用过来,用的时候查一下就可以了:
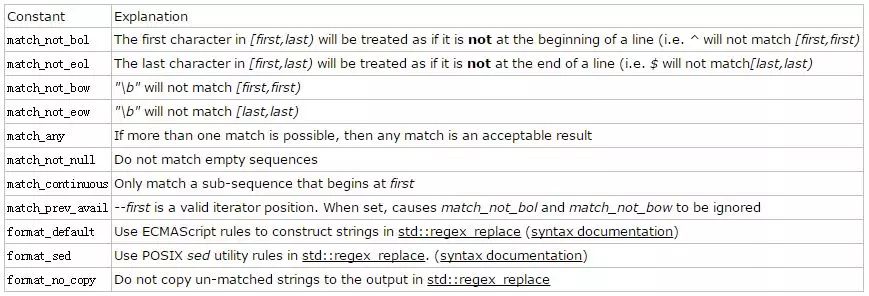
根据参数类型,于是我们构造了这样的调用:
std::smatch results;<br>regex_search(html,results,r);
不过,标准库规定regex_search()在查找到第一个匹配的子串后,就会停止查找!在本程序中,results参数只带回了第一个满足条件的http链接。这显然并不能满足我们要提取网页中所有HTTP链接需要。
使用 regex_iterator 匹配所有子串
严格意义上regex_iterator是一种迭代器适配器,它用来绑定要匹配的字符序列和regex对象。regex_iterator的默认构造函数比较特殊,就直接构造了一个尾后迭代器。另外一个构造函数原型:
regex_iterator(BidirIt a, BidirIt b, //分别是待匹配字符序列的首迭代器和尾后迭代器
const regex_type& re, //regex对象
std::regex_constants::match_flag_type m = std::regex_constants::match_default); //标志,同上面的regex_search()中的
和上边的regex_search()一样,regex_iterator的构造函数中也有std::regex_constants::match_flag_type类型的参数,用法一样。其实regex_iterator的内部实现就是调用了regex_search(),这个参数是用来传递给regex_search()的。用gif或许可以演示的比较形象一点,具体是这样工作的(颜色加深部分,表示可以匹配的子序列):
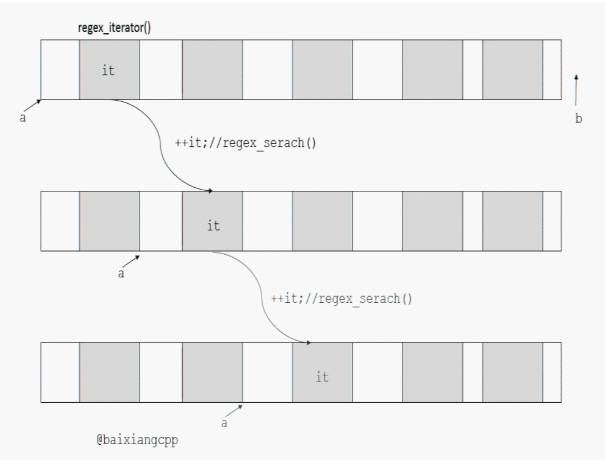
首先在构造regex_iterator的时候,构造函数中首先就调用一次regex_search()将迭代器it指向了第一个匹配的子序列。以后的每一次迭代的过程中(++it),都会在以后剩下的子序列中继续调用regex_search(),直到迭代器走到最后。it就一直“指向”了匹配的子序列。
知道了原理,我们写起来代码就轻松多了。结合前面的部分我们,这个程序就基本写好了:
#include <iostream>
#include <regex>
#include <string>
int main()
{
std::string tmp,html;
while(getline(std::cin,tmp))
{
tmp += '\n';
html += tmp;
}
std::string pattern("http(s)?://([\\w-]+\\.)+[\\w-]+(/[\\w- ./?%&=]*)?");
pattern = "[[:alpha:]]*" + pattern + "[[:alpha:]]*";
std::regex r(pattern);
for (std::sregex_iterator it(html.begin(), html.end(), r), end; //end是尾后迭代器,regex_iterator是regex_iterator的string类型的版本
it != end;
++it)
{
std::cout << it->str() << std::endl;
}
}
下载本页的html源码保存为test.html,编译这个源码测试一下,大功告成:
[regex]g++ regex.cpp -std=c++11 -omain
[regex]main < test.html
http://www.cnblogs.com/ittinybird/rss
http://www.cnblogs.com/ittinybird/rsd.xml
http://www.cnblogs.com/ittinybird/wlwmanifest.xml
http://common.cnblogs.com/script/jquery.js
http://files.cnblogs.com/files/ittinybird/mystyle.css
http://www.cnblogs.com/ittinybird/
http://www.cnblogs.com/ittinybird/
http://www.cnblogs.com/ittinybird/
http://i.cnblogs.com/EditPosts.aspx?opt=1
http://msg.cnblogs.com/send/%E6%88%91%E6%98%AF%E4%B8%80%E5%8F%AAC%2B%2B%E5%B0%8F%E5%B0%8F%E9%B8%9F
http://www.cnblogs.com/ittinybird/rss
http://www.cnblogs.com/ittinybird/rss
http://www.cnblogs.com/images/xml.gif
http://i.cnblogs.com/
http://www.cnblogs.com/ittinybird/p/4853532.html
http://www.cnblogs.com/ittinybird/p/4853532.html
http://www.w3school.com.cn/jsref/jsref_obj_regexp.asp
http://www.cnblogs.com/ittinybird/
http://i.cnblogs.com/EditPosts.aspx?postid=4853532
http://www.cnblogs.com/
http://q.cnblogs.com/
http://news.cnblogs.com/
http://home.cnblogs.com/ing/
http://job.cnblogs.com/
http://kb.cnblogs.com/
regex 和异常处理
如果我们的正则表达式存在错误,则在运行的时候标准库会抛出一个regex_error异常,他有一个名为code的成员,用于标记错误的类型,具体错误值和语义如下表所示:
有关异常处理的基本内容,不是本篇要讨论的内容,就不赘述了。
小结
C++11标准库中的正则表达式部分还有部分内容本文没有涉及,个人以为掌握了以上的内容后,基本上看一看接口就知道怎么使用了,这里就不浪费篇幅了。
谢谢你的阅读,错误之处还请您指正,我将万分感谢:)。
觉得本文有帮助?请分享给更多人
关注「CPP开发者」
看更多精选C/C++技术文章
↓↓↓
以上是关于C++ 中也能使用的正则表达式的主要内容,如果未能解决你的问题,请参考以下文章