正则表达式?清理数据的神器
Posted Idata
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式?清理数据的神器相关的知识,希望对你有一定的参考价值。
其实,我是不懂正则表达式的。
大家都说,学爬虫,一定要学正则表达式。
我跑过去问我们的“攻城狮”:“哥,你给我讲讲正则表达式呗。” 他甩过来一张图:
此刻,我的内心是崩溃的。啥,这都是啥?

于是,我决定放弃治疗。
太难了太难了,不学了。

直到我拿到一份世界500强的名单,老大让我把每个企业的英文名提取出来,数据是这样的:
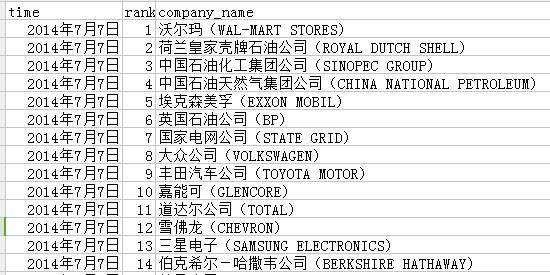
我的第一反应,这个数据是可以用Stata里的split来解决的,但认真看了这个数据之后,觉得使用slit来分拆会造成误伤,比如出现这种观测值:“中国人寿保险(集团)公司(CHINA LIFE INSURANCE)”,而且这个数据最奇葩的一点是左边的括号是中文格式,右边的括号是英文括号。
于是我去找“攻城狮”:哥,你给我把这个正则表达式写一下呗。
他给我甩过来一个链接:
http://tool.oschina.net/regex/(在线正则表达式测试工具)
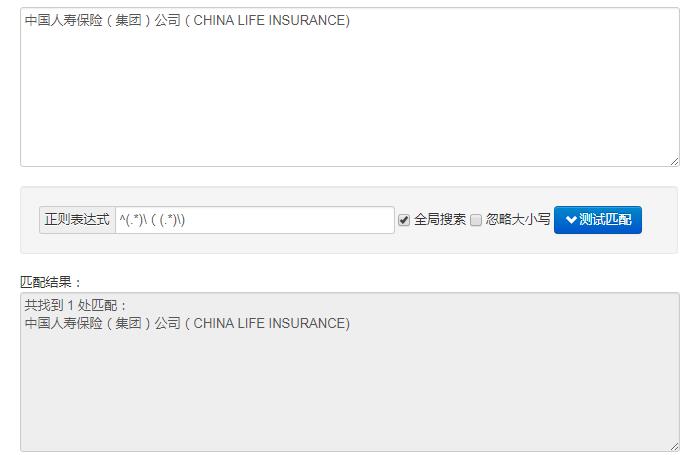
我用在Stata里处理一下,代码是这样:
clear
set obs 1
gen v="中国人寿保险(集团)公司(CHINA LIFE INSURANCE)"
gen a=regexs(1) if regexm(v,"^(.*)\((.*)\)")
gen b=regexs(2) if regexm(v,"^(.*)\((.*)\)")
list a b
得到的结果:

大功告成!
以上是关于正则表达式?清理数据的神器的主要内容,如果未能解决你的问题,请参考以下文章