浅谈正则表达式匹配模式—懒惰模式
Posted 爬虫俱乐部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈正则表达式匹配模式—懒惰模式相关的知识,希望对你有一定的参考价值。
哈喽,诸君安。在上篇推文中,我们讲了正则表达式匹配模式中的贪婪模式,那么与贪婪模式相对应的就是懒惰模式。接下来,小编就给大家介绍一下正则表达式匹配的懒惰模式。
经过笔者测试,在Stata14之前,Stata正则表达式的三个字符串函数regexm()、regexs()与regexr()不具备懒惰匹配模式。在Stata14以及新出的stata15中,以ustr开头的四个字符串函数才可以使用懒惰模式。之前的推文也介绍过,Stata14之前的版本只能使用以下正则表达式元字符:“[]”、“a-z”、“.”、“*”、“+”、“?”、“^”、“$”、“|”、“()”,其他元字符只能在stata14、stata15中使用。可见Stata14、Stata15的正则表达式比起之前版本确实强大了很多,因此笔者也更推荐使用Stata14和Stata15对字符串进行处理。
当使用除“{n}”之外的数量元字符后面跟上“?”元字符时,会进入正则表达式匹配的懒惰模式,也称非贪婪模式。在懒惰模式下,首先看字符串中的第一个字符是否与正则表达式匹配,如果单独这一个字符没有匹配成功,就读入下一个字符,组成两个字符的字符串,如果还是没有匹配成功,继续读入下一个字符。如果直到读入整个字符串都没有实现匹配,就返回从第二个字符开始,重复上述的工作。直到匹配成功或者全部尝试过后也没有匹配出任何字符。用“懒惰”这个词,也可以把这个模式解释为:从头开始一个字符一个字符地吃,能少吃绝不多吃,直接匹配成功为止。

例如,正则表达式re符合懒惰模式,对字符串“abc”进行匹配。
1、首先字符串“abc”的第一个字符“a”进行匹配;
2、如果匹配不上,加上下一个字符“b”,对“ab”进行匹配;
3、如果匹配不上,加上下一个字符“c”,对“abc”进行匹配;
4、如果匹配不上,将“abc”第一个字符“a”去掉,对字符串“bc”第一个字符“b”进行匹配;
5、如果匹配不上,加上下一个字符“c”,对“bc”进行匹配;
6、如果匹配不上,去掉“bc”中的第一个字符“b”,对“c”进行匹配。
下面我们用一个例子来展示一下懒惰模式:
clear
set obs 10
gen v = "A" + "B" * (_n - 1)
gen v1 = ustrregexs(0) if ustrregexm(v, "AB*?")
gen v2 = ustrregexs(0) if ustrregexm(v, "AB+?")
gen v3 = ustrregexs(0) if ustrregexm(v, "AB??")
gen v4 = ustrregexs(0) if ustrregexm(v, "AB{1,3}?")
gen v5 = ustrregexs(0) if ustrregexm(v, "AB{3,}?")
list, sep(0)
程序执行结果如下:
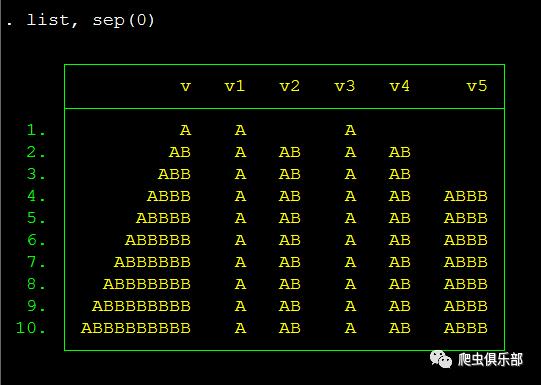

首先,变量v1是正则表达式"AB*?"的匹配结果,元字符“*”之后跟着“?”元字符,便会进入正则表达式的懒惰模式。我们以变量v中第一条观测值“A”和最后一条观测值“ABBBBBBBBB”为例。对于“A”,正则表达式“AB*?”首先对字符串“A”的第一个字符(即“A”)进行匹配,匹配成功,这时候事实上对“B”匹配了0次;对于“ABBBBBBBBB”,正则表达式“AB*?”首先对字符串“ABBBBBBBBB”的第一个字符“A”进行匹配,匹配成功,这里对字符“B”也是匹配了0次;

v2是正则表达式“AB+?”的匹配结果,与“AB*?”不同的是这里对字符“B”至少匹配一次,因为元字符“+”表示对前一个字符或子表达式匹配一次或多次;所以对变量v中“A”进行匹配时,首先匹配字符串“A”中的第一个字符“A”,因为至少对“B”匹配一次,所以匹配不成功;对字符串“ABBBBBBBBB”进行匹配时,首先对字符串的第一个字符“A”进行匹配,匹配不成功,然后加上下一个字符“B”,变为“AB”,即匹配成功,对“B”匹配了1次,“AB”即为匹配结果。

v3是正则表达式“AB??”的匹配结果,元字符“?”表示对前一个字符或子表达式匹配0次或1次,后边跟上元字符“?”也会进入正则表达式的懒惰模式。我们还以“A”和“ABBBBBBBBB”为例。首先,对于字符串“A”进行匹配时,首先对字符串的第一个字符“A”进行匹配,匹配成功,这时候对字符“B”匹配了0次;对“ABBBBBBBBB”进行匹配时,首先匹配字符串“ABBBBBBBBB”的第一个字符“A”,匹配成功,这时候对字符B也匹配了0次,匹配结果为“A”。

v4是正则表达式“AB{1,3}?”的匹配结果,元字符“{n1,n2}”表示对前一个字符或子表达式匹配至少n1次,至多n2次,后边跟上元字符“?”同样也会进入正则表达式的懒惰匹配模式。所以在对“A”进行匹配时,首先,把字符串的第一个字符“A”进行匹配,因为至少对字符“B”匹配1次,所以匹配不成功;对于“ABBBBBBBBB”,同样先对字符串“ABBBBBBBBB”中的第一个字符串“A”进行匹配,由于对字符“B”至少匹配1次,所以匹配不成功,接着按懒惰模式的匹配法则,加上后一个字符“B”,变为“AB”,匹配成功,这时候对字符“B”匹配了1次。
变量v5是正则表达式AB{3,}的匹配结果,元字符{n,}表示对前一个字符或子表达式匹配至少n次(此例中即表示至少匹配3次),加上元字符“?”便会进入懒惰模式。对“A”进行匹配时,因为至少对字符“B”匹配3次,所以匹配不成功;对于字符串“ABBBBBBBBB”匹配时,首先,匹配字符串“ABBBBBBBBB”的第一个字符“A”,匹配不成功,然后加上后一个字符“B”,变为“AB”,仍然匹配不成功,然后再加后一个字符“B”,变为“ABB”,还是匹配不成功,接着加后边一个字符“B”,变为“ABBB”,匹配成功,这时候对字符“B”匹配了3次。

和贪婪模式一样,这里也需要注意一点,懒惰模式并不是说我们匹配出的就是整个字符串中所能匹配到的最短的子字符串,其匹配顺序为先尝试匹配字符串中的第一个字符,然后依次读入下一个字符...也就是说在懒惰匹配模式下,匹配出的实际上也是从尽可能靠近字符串开头的位置开始的,与正则表达式相匹配的最短的字符串。我们以下边一个例子为例:
clear
set obs 1
gen str v = "aaaaab"
gen v1 = ustrregexs(0) if ustrregexm(v, "a+?b")list
list
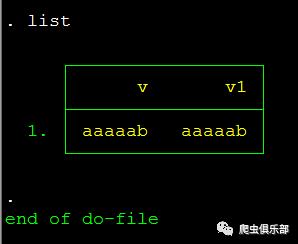
可以发现,在懒惰模式下匹配的并不是整个字符串中最短的子字符串“ab”,而是以靠近字符串开头位置开始,与正则表达式相匹配的最短字符串“aaaaab”。它的匹配过程为:首先,元字符“+”是一个数量元字符,表示匹配前一个字符或子表达式至少一次,其后跟元字符“?”便会进入懒惰模式,首先匹配字符串的第一个字符“a”,因为整个正则表达式匹配的是多个“a”,后边紧跟着“b”,因此单个字符“a”匹配不成功,接着往后边加上下一个字符“a”,变为“aa”,仍然匹配不成功......直到加上最后一个字符“b”,变为字符串“aaaaab”,匹配成功,这时候对“a”匹配了5次。
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
文字编辑:司海涛
技术总编:刘贝贝
往期推文推荐:
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
关于我们
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
欢迎关注爬虫俱乐部
以上是关于浅谈正则表达式匹配模式—懒惰模式的主要内容,如果未能解决你的问题,请参考以下文章