这可能是迄今最好的正则表达式学习笔记
Posted topgeek
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这可能是迄今最好的正则表达式学习笔记相关的知识,希望对你有一定的参考价值。
编者注:
正则这个东西,不管你是学什么语言的,总会用到的,毕竟它是如此的方便。 原标题: 《正则表达式学习笔记》。编者略作修改。 作者:水墨寒湘原文链接:http://gold.xitu.io/post/582dfcfda22b9d006b726d11
正则表达式对于我来说一直像黑暗魔法一样的存在。手机正则去网上搜,邮箱正则去网上搜,复杂点的看看文档拼凑一下,再复杂只能厚着脸皮让其他同事给写一个。从来没有系统的学习过,今天准备拿下它。
1. 学习目标
了解正则表达式语法
在IDE中使用正则表达式
在javascript中使用正则表达式处理字符串
2. 什么事正则表达式
正则表达式:又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
通俗的讲就是按照某种规则去匹配符合条件的字符串。
3. 利用图形化工具理解正则表达式
辅助理解正则表达的在线工具 https://regexper.com/ 我们利用这个工具辅助理解,正则表达式。语法没懂表着急,后面会有,这里只是学会用工具帮助我们学习。手机号正则:/^1[34578][0-9]{9}$/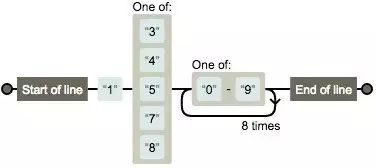
注释:以1开头,第二位为3 4 5 7 9 其中一个,以9位(本身1次加重复8次)0-9数字结尾。
单词边界:/\bis\b/
注释: is前后都是单词的边界,比较晦涩难懂?感受下两者的区别,\b会方道语法部分讲解。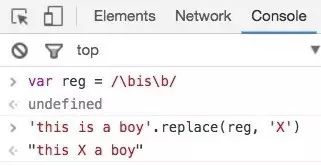
URL分组替换:/http:(\/\/.+\.jpg)/看不懂的不要慌语法部分后面会有介绍,这里只是展示利用可视化的图形帮助我们理解正则表达式,可以回来再看木有关系。
正则表达式中括号用来分组,这个时候我们可以通过用$1来获取 group#1的内容。
说下这个正则的意义,如果网站用了https,网站引用静态资源也必须是https,否则报错。如果写成// 会自动识别 http 或者 https。
日期匹配与分组替换/^\d{4}[/-]\d{2}[/-]\d{2}$/
这个正则比较复杂,画符念咒的地方太多了,一一分析:
Start of line 是由
^生效的表示以此开头。对应结尾End of line 由
$生效表示以此结尾。接着看digit 由
\d生效表示数字。3times 由
{4}生效表示重复4次,开始的时候有疑问,为什么不是 4times 。后来明白作者的用意,正则表达式是一个规则,用这个规则去从字符串开始匹配到结束(注意计算机读字符串可是不会分行的,都是一个串,我们看到的多行,人家会认为是个\t)这里设计好像小火车的轨道一直开到末尾。digit 传过一次,3times表示再来三次循环,共4次,后面的once同理。 自己被自己啰嗦到了。接下来,是 one of 在手机正则里面已经出现了。表示什么都行。只要符合这两个都让通过。
好了这个正则解释完了,接下来用它做什么呢?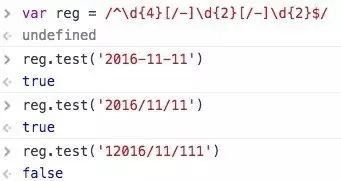
我们可以验证日期的合法性:结合URL分组替换所用到的分组特性,我们可以轻松写出日期格式化的方法。改造下这个正则:/^(\d{4})[/-](\d{2})[/-](\d{2})$/轻松的可以拿到 group#1 #2 #3 的内容,对应 $1 $2$3
到现在已经能结合图形化工具看懂正则表达式表达式了,如果想自己写,还要在正则语法上下点功夫。
4. Js中Regexp对象
Javascript 通过内置对象RegExp支持正则表达式,有两种方法实例化RegExp对象字面量方法const reg =/\bis\b/g构造函数const reg = new RegExp('\\bis\\b', 'g')注意:第一个参数为正则表达式字符串(注意转译),第二个参数为修饰符,修饰符g代表全局搜索,后面会有详细介绍。
5. 正则表达式语法
5.1 修饰符 (三个 g i m)
修饰符与其他语法特殊,字面量方法声名的时候放到//后,构造函数声明的时候,作为第二个参数传入。整个正则表达式可以理解为正则表达式规则字符串+修饰符
g:global 执行一个全局匹配
i:ignore case执行一个不区分大小写的匹配
m: multiple lines多行匹配
修饰符可以一起用 const reg =/\bis\b/gim来说说他们有什么作用有g和没有g的区别: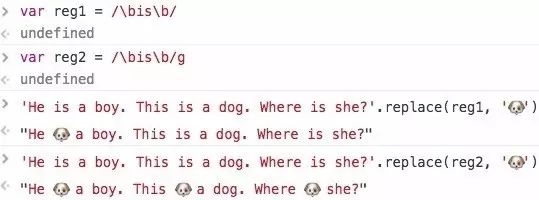
没有g只替换了第一个,有g 所有的都换了
有i和没有i的区别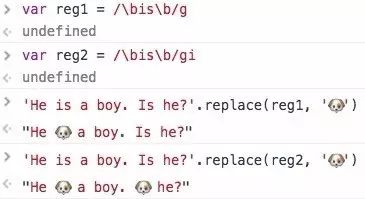
有i忽略大小写,没有i严格区分大小写
5.2 元字符
正则表达式由两种基本字符组成:
原义字符
非打印字符
元字符 (* + ? $ ^ . | \ ( ) { } [ ])
5.3 原义字符
这个没什么好解释的,我们一直在举例的/is/ 匹配字符串'is'\将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,n”匹配字符“n”。“\n”匹配一个换行符。序列“\\”匹配“\”而“\(”则匹配“(”。
5.4 非打印字符
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v] |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v] |
| \t | 匹配一个制表符。等价于 \x09 和 \cI |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK |
非打印字符,以\n为例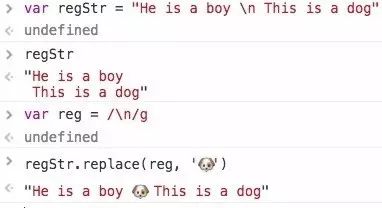
其他的在前端引用比较少,应该在后端处理文本文件的时候会用到。
5.5 字符类 []
在前面的手机号正则例子 以上是关于这可能是迄今最好的正则表达式学习笔记的主要内容,如果未能解决你的问题,请参考以下文章