小议网站本地化中的正则表达式
Posted 简言
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小议网站本地化中的正则表达式相关的知识,希望对你有一定的参考价值。
一、背景:
这学期的《翻译与本地化实践》课给学生布置了一个期末项目,是很早之前一次计算机辅助翻译大赛的赛题,也是北京大学计算机辅助翻译专业的一次本地化课程期末小组作业。项目内容就是将一个网站本地化成中文,其中有一个文件长这个样子:
啊,好像看不出来这个文件长什么样。
其实是下面这个样子:

这是一个格式为“php”的文件,里面存储的是网站上一些文本内容,也就是我们在做网站本地化时要翻译的文本。
(小注:PHP was created by Rasmus Lerdorf in 1994. It was orginally stood for "Personal Home Page" and now it is said to stand for "PHP: Hypertext Preprocessor", a recursive acronym.)
在这个PHP文件里头,真正要翻译的内容是最后面的两个单引号里的文字,而其他的文字不需要翻译。比如:
代码:$language['welcome']='Welcome!';
上面这段代码中要翻译的内容是:Welcome!
遇到这种文件,我们通常想使用的软件就是“计算机辅助翻译软件”(CAT软件),比如SDL Trados、memoQ、DejaVu这一类的。但是,当我们将这个文件导入CAT软件中时,却遇到下面这种情况:

这些要翻译的文字根本就没法识别。
是的,连要替代人类译者的谷歌翻译来了也翻不出来。(玩笑话玩笑话)
像这样的代码,在整个文件中有这么几种类型:
类型一:一个中括号,括号中全是英文
$language['welcome']='Welcome!';
类型二:一个中括号,括号中有英文也有下划线
$language['content_add']='Add content';
类型三:一个中括号,括号中有英文有下划线也有数字
$language['form_vote_state_1']='Normal';
类型四:两个中括号,括号中有英文也有下划线
$language['log_action']['batch_delete']='Bulk delete';
怎么样才能让CAT软件识别这里面要翻译的内容呢?
二、方案
我们一般会想到的方法是,这还不简单,让计算机去找前面有等号单引号,后面有引号分号的文字不就可以了,只要找到这四个标点符号不就可以定位要翻译的内容,管他什么有没有中括号呢。
这样想并没有错,只是对于软件来说,识别待翻译内容时,结尾确实是识别单引号和分号,但开头却没有那么简单,而是:以$language开头,一直持续到等号单引号这段代码。
为了能让软件识别这段看起来有规律,但又不知道准确描述规律的代码,我们就要引入正则表达式了。
正则表达式的英文叫做“Regular Expression”。至于“Regular”为什么要翻译成“正则”,我们以后再专门讨论。这篇帖子直接切入到如何使用这个玩意儿来帮助软件识别一连串代码。
准备工作:
我知道看这个帖子的人并不多,即便点击进来看了也不一定知道我在说什么,所以对于那些知道我在说什么的读者,可以打开两个网页:
网页一:正则表达式教程
http://www.runoob.com/regexp/regexp-tutorial.html
网页二:在线正则表达式测试工具
http://tool.oschina.net/regex/
第一个网页是用来恶补背景知识的,第二个网页是可以和我一起操作的。
首先将几个典型的代码粘贴到网页二中,如图:
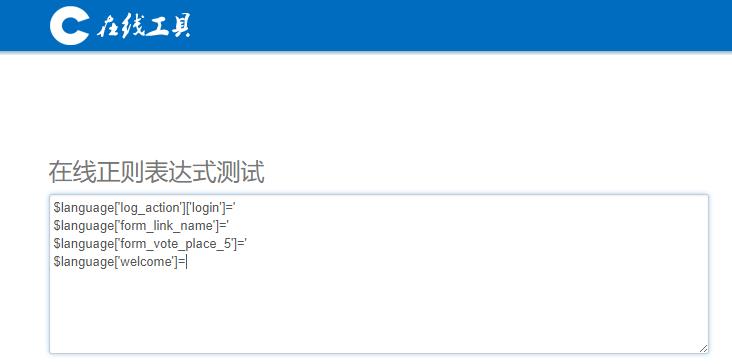
而我们的目标则是写一串“虽然现在看不懂但是一会儿就能看懂”的代码来识别这些内容。
我们的星辰大海是:
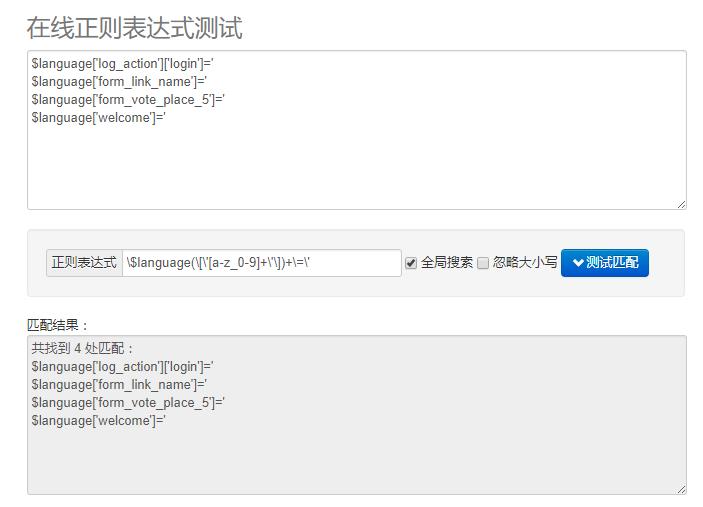
是的,这就是答案。
三、详解答案
如果你看懂了话就关掉这个网页吧,如果没有看懂的话,就顺着我的思路继续看。
第一步:识别四行代码都共有的:$language['
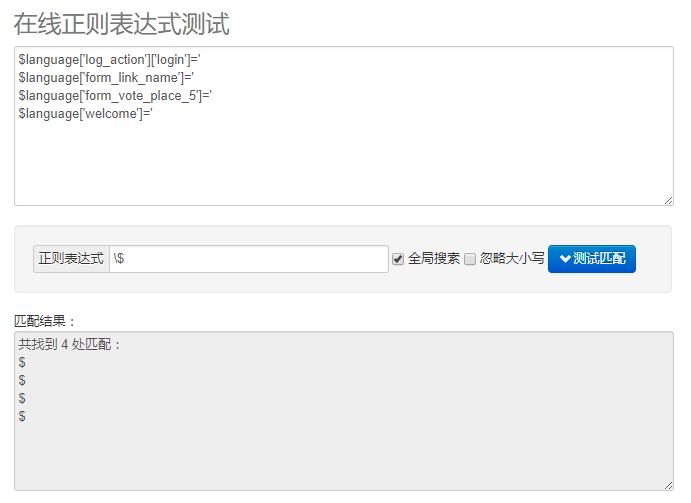
在正则表达式中,如果直接输入$,那么它不会匹配到上面这行代码中的$,因为$在正则表达式有特殊的作用:
匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。
(注:看不懂没关系,我直接粘贴过来的,我也没有看完)
所以,为了能让软件正确识别这个符号,需要在前面加一个“转义符”:\
就是这个样子:\$
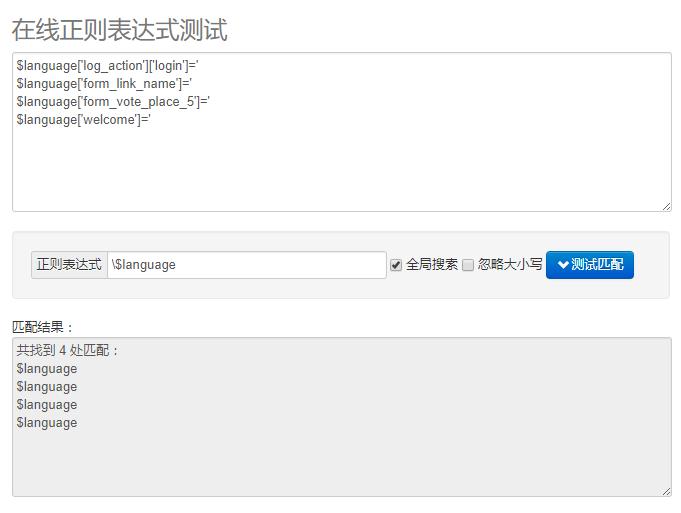
第二步:识别$后面的language
这个就没什么好讲的了,直接在\$后面加上language即可:
第三步:识别['
这个中括号和这个单引号在正则表达式也有专门的用途:
中括号:
标记一个中括号表达式的开始。要匹配 [,请使用 \[。
单引号:
在我给出的网页一对应的教程中好像没有提单引号是什么用,这里可以给它加转义符,也可以不用加,但在有些编程语言中它是有专门用途的,所以这里还是加上转义符比较好。
所以接下来要写的正则表达式就是:\$language\[\'
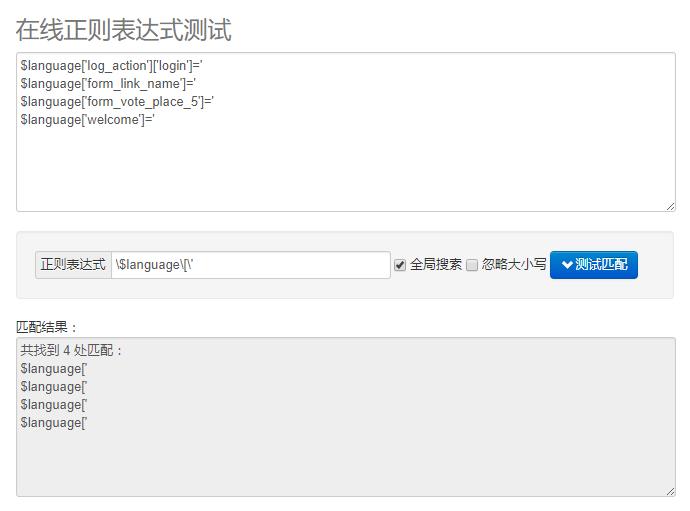
第四步:识别单引号中的英文字母、数字和标点符号
接下来就稍微有点复杂了,刚开始接触会不太好理解。
分析完那些代码后,发现有很多小写英文字母,而正则表达式中用来匹配小写英文字母的表达式是:[a-z],但如果直接用的话每次只能匹配从a到z中的一个小写英文字符,如果要匹配多个的话,就得在后面加一个加号:[a-z]+
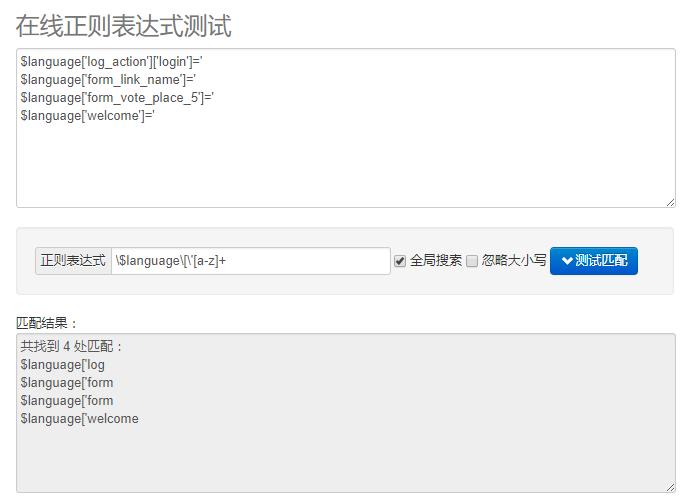
从图中可以看到,英文字母倒是识别了,但是标点符号没有识别到,所以需要在a-z后面加一个_,即:[a-z_]+
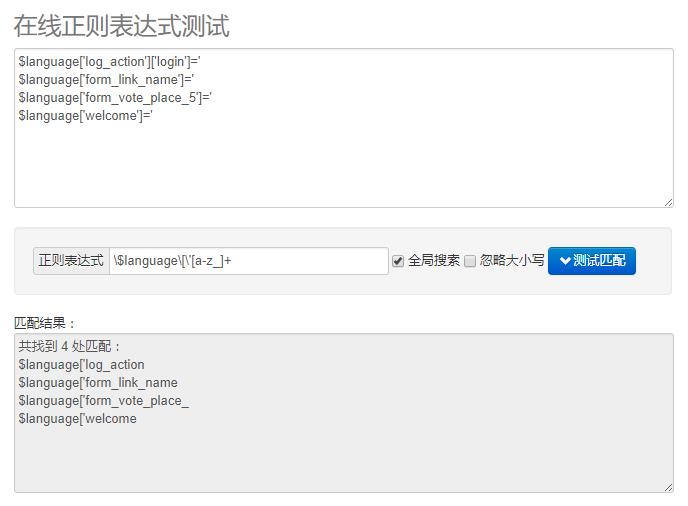
然而,第三行代码中的数字还没有识别出来。正则表达式的语法中,表示阿拉伯数字的表达式是:[0-9],所以再改一下表达式:[a-z_0-9]+
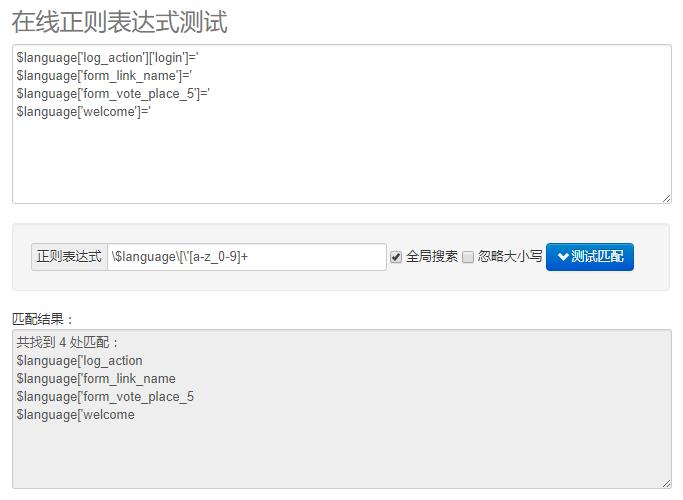
终于又往前进了一步,现在第一个中括号里面的内容我们已经识别出来了,可以继续加上对单引号和中括号的识别表达式,这样就可以结束了。
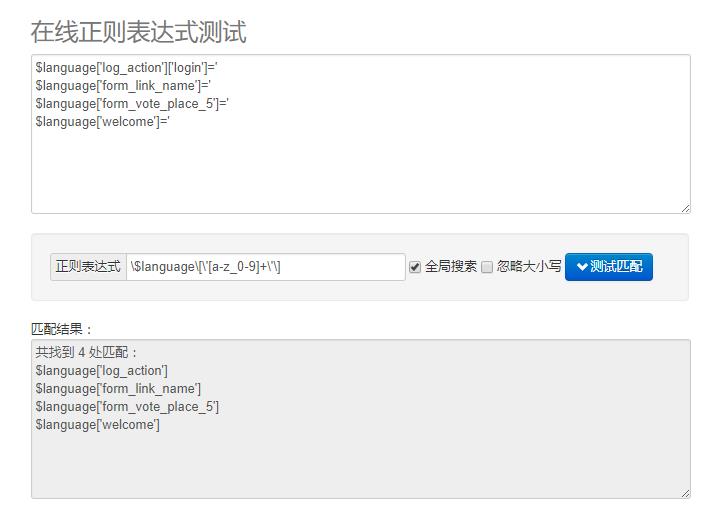
等等,第一行后面还有一个中括号没有识别到呢,咋回事儿?
第五步:识别多个同一类型的字符串
本质上来说,\[\'[a-z_0-9]+\'\] 这个正则表达式也可以识别第一行的['login'],但是我们刚刚写的表达式只能识别一个中括号,第二个中括号就识别不了了。如果我们再把这个表达式写一遍:\$language\[\'[a-z_0-9]+\'\]\[\'[a-z_0-9]+\'\]
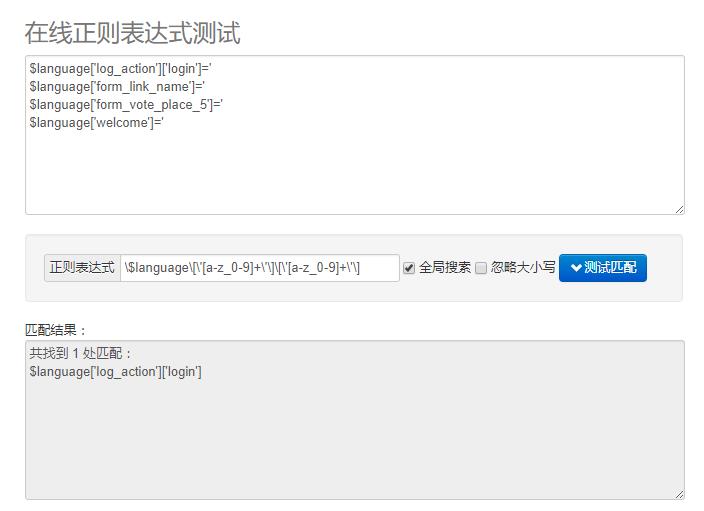
虽然第一行识别出来的,但是其他几行却不行。
所以,我们这里要引入一个新的正则表达式语法:()
它的作用是:标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。
所以我们可以用这个圆括号把刚才用来匹配中括号及其内容的字符串,然后在后面使用一个加号。
加号的所用是:匹配前面的子表达式一次或多次。
表达式如下:\$language(\[\'[a-z_0-9]+\'\])+
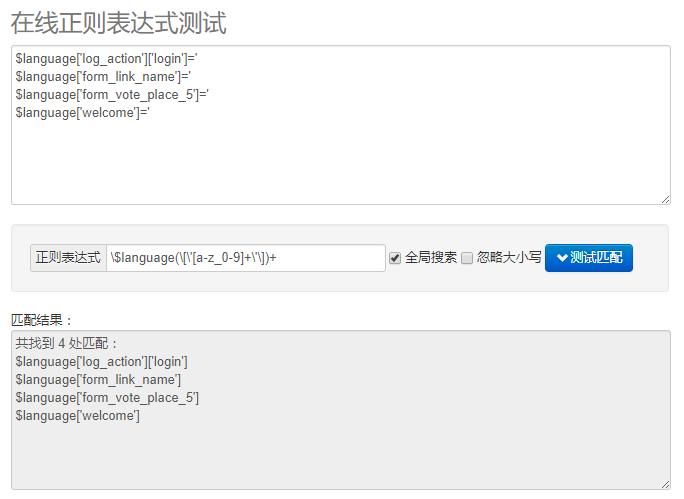
哦了,再有几个中括号都不怕了。
顺便再科普另外一种括号,花括号:{}
如:\$language(\[\'[a-z_0-9]+\'\]){1,}
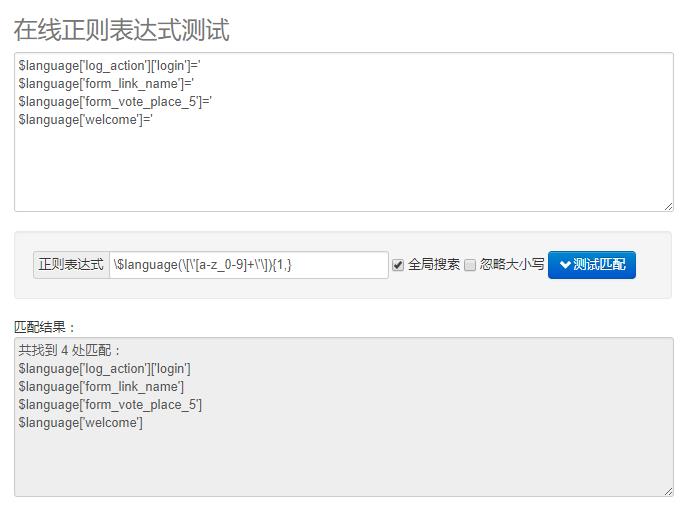
至于原理是什么,读者可以自己前往网页一去学习。
第六步:匹配等号和单引号:
表达式如下:\$language(\[\'[a-z_0-9]+\'\])+\=\'
第七步:匹配结尾的单引号和分号:
表达式如下:\'\;
四、剧终
根据上面的正则表达式,我们就可以分别匹配待译字符串的开头和结尾了,放到CAT软件去里设置一下:
要翻译的文件就变成这样了:
结语:
翻译只是本地化的一个环节,文科背景的翻译专业学生并不一定需要学正则表达式这种看起来很理科的东西,但如果学会了,未来能自己解决很多有意思的问题。
以上是关于小议网站本地化中的正则表达式的主要内容,如果未能解决你的问题,请参考以下文章