正则表达式之Dotall模式
Posted 爬虫俱乐部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式之Dotall模式相关的知识,希望对你有一定的参考价值。
有问题,不要怕!点击推文底部“阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~
在推文中,元字符“.”匹配的应当是除了回车符(\r)和换行符(\n)之外的任意字符,并且讲到可以利用具有相反含义的元字符的组合([\s\S]、[\w\W])来匹配任意单个字符。但是,今天要告诉大家,元字符“.”也可以匹配任意单个字符,包括换行符和回车符。这是怎么回事呢?
默认情况下,元字符“.”不会匹配换行符和回车符, 设置了Dotall模式后, 其就会匹配所有字符包括换行符和回车符。但是Stata中的几个正则表达式字符串函数(regexm、regexs、regexr、ustrregexm、ustrregexs等)是不能使用Dotall模式的,那么我们怎么在stata中使用这种模式呢?这里给大家介绍一个命令:jregex。这里命令目前没有上传到ssc上,大家可以输入以下代码下载该命令:
net inst jregex, from("http://wbuchanan.github.io/StataRegex/")
语法结构
jregex是一个基于java的插件,用于Stata中的正则表达式。jregex命令可以实现stata与java的交互,通过stata调用java中的正则表达式,jregex的语法结构如下:

jregex有非常丰富的选项,这篇推文中我们着重介绍以下几个:
1.pattern(string):指的是用来匹配文本的正则表达式,这个选项是必须指定的。
2. dotall:即dotall模式,该模式下,元字符“.”可以匹配任意单个字符,包括换行符和回车符;
3. replace(string):指的是用来替代匹配值的字符串;
4. repfirst:指定该选项后,仅仅替换第一个匹配值;
例子
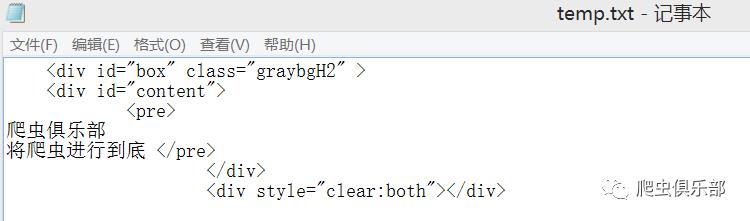
我们来看一个例子,首先用file命令生成一个名为“temp”的txt文件:
tempname temp
file open `temp' using 文档1.txt, text write replace
file write `temp' `" <div id="box" > "' _n
file write `temp' `" <div id="content"> "' _n
file write `temp' `" <pre>"' _n
file write `temp' `"爬虫俱乐部"' _n
file write `temp' `"将爬虫进行到底 </pre> "' _n
file write `temp' `" </div> "' _n
file write `temp' `" <div style="clear:both"></div> "'
file close `temp'
shellout temp.txt //打开temp.txt文件
假设temp.txt是源代码的一部分,首先,将其用fileread()函数导入stata:
clear
set more off
set obs 1
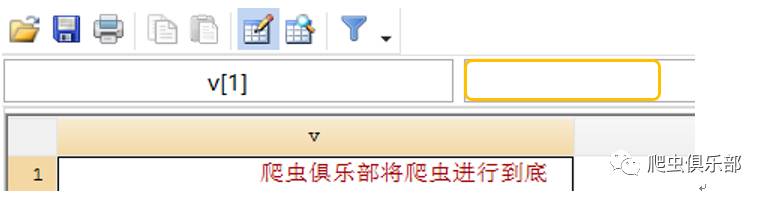
gen v = fileread("temp.txt")
list

在推文中,我们讲到上图阴影部分(即文本不同行之间)是存在换行符和回车符的,现在假设要从变量v中提取“爬虫俱乐部”以及“将爬虫进行到底”这两个字符串,通过分析网页源代码可知,在提取内容的起始位置有一个唯一的字符串“<pre>”,末尾位置有唯一的字符串“</pre>”,那么我们把字符串“<pre>” 及之前多余的字符串和“</pre>”及之后多余的字符串删掉即可,我们首先用元字符“.”进行匹配:
replace v = ustrregexra(v,".+<pre>","")
replace v = ustrregexra(v,"</pre>.+","")
list

由于这里存在着换行符(\n)和回车符(\r),而元字符“.”不能匹配到它们,因此匹配结果仅仅是位于字符串“<pre>”的所在行以及字符串“</pre>”的所在行。因此,在没有指定Dotall模式下,元字符“.”是不能匹配换行符和回车符的,这在之前的推文中已经详细介绍过。接下来,我们用jregex命令进行替换,并指定Dotall模式:
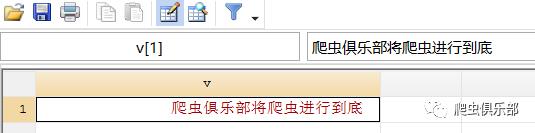
jregex replace v ,p(".+<pre>") rep("") dotall
jregex replace v ,p("</pre>.+") rep("") dotall
首先,简单介绍一下上述程序:
(1) jregex replace v指的是直接在变量v上进行修改,如果v后边再跟一个新变量(比如说:v1),即jregex replace v v1,那么将生成一个新变量v1,原变量v的内容不变,生成的新变量v1是匹配和替换后的结果;
(2)选项p(".+<pre>"),即pattern(string),指的是用来匹配文本的正则表达式,这里“p(".+<pre>")”指的是字符串“<pre>”及其之前的多余字符串;
(3)选项rep(""),即replace(string):指的是用来替代匹配值的字符串,这里把匹配值(选项p()的匹配结果)全部替换为missing。
(4)dotall:即指定dotall模式
compress
list

可以看到,在Dotall模式下,元字“.”是可以匹配换行符和回车符的。我们再来看一下,stata内存中的数据:
我们注意到,stata编辑框中并没有显示出文本的内容,这是因为我们用正则表达式".+<pre>"和"</pre>.+"匹配字符串“<pre>” 及之前多余的字符串和“</pre>”及之后多余的字符串,并将其替换为missing,但是“爬虫俱乐部”之前,及“爬虫俱乐部”和“将爬虫进行到底”之间的换行符和回车符并没有删除,所以编辑框中没有显示出文本的内容,我们可以用字符串函数ustrregexra()或者jregex命令将换行符和回车符删掉,这里我们用jregex命令。
jregex replace v ,p("\r\n") rep("")
到了这里,大家应该非常清楚正则表达式的Dotall模式了,关于jregex命令的内容还有很多,我们将在之后的推文中继续介绍相关用法,请大家继续关注爬虫俱乐部哦!
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同纯属巧合!

以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
文字编辑:王 明
技术总编:刘贝贝
往期推文推荐:
关于我们
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
欢迎关注爬虫俱乐部
以上是关于正则表达式之Dotall模式的主要内容,如果未能解决你的问题,请参考以下文章