正则表达式re
Posted 杨少侠Studio
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式re相关的知识,希望对你有一定的参考价值。
通过这篇文章为大家介绍崔庆才老师对Python爬虫正则表达式re的讲解,包括基本原理及其理论知识点
本文共有约1200字,建议阅读时间10分钟,并且注重理论与实践相结合
觉得文章比较枯燥和用电脑观看的可以点击阅读原文即可跳转到CSDN网页
目录:
一、什么是正则表达式?
二、样例展示
三、用法讲解
四、实例演练
一、什么是正则表达式?
正则表达式对子符串操作的一种逻辑公式,就是事先定义好的一些特定字符、及这些特定字符的组合,组成一个‘规则字符串’,这个‘规则字符串’用来表达对字符串的一种过滤逻辑。(非Python独有,re模块实现)
二、样例展示
1.官网:http://tool.oschina.net/regex
2.view-source:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html
如抓取最好大学中的学校名称及其排名也可以用正则表达式

三、用法讲解
常用匹配模式
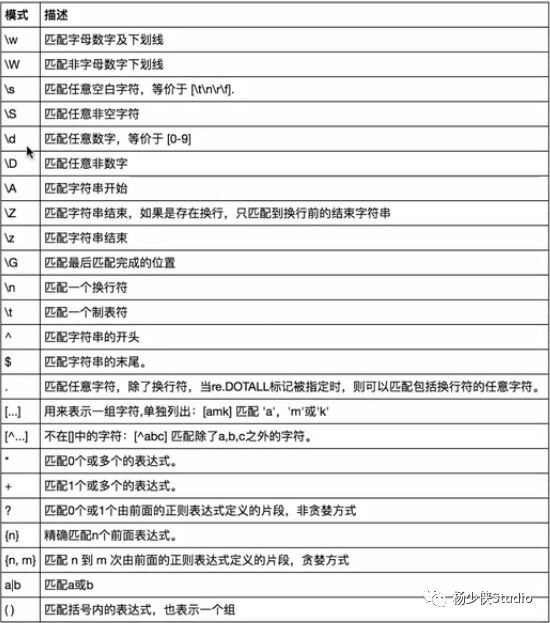
http://www.runoob.com/菜鸟教程,里面有re模块的详解
re.match
re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None
re.match(pattern,string,flags=0)
#最常规的用法
#.
import re content = 'Hello 123 4567 World_This is a Regex Demo' result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}.*Demo$',content) print(result) <_sre.SRE_Match object; span=(0, 41), match='Hello 123 4567 World_This is a Regex Demo'> print(result.span())#span输出匹配结果的范围 (0, 41) print(result.group())#group返回匹配结果 Hello 123 4567 World_This is a Regex Demo #泛匹配(.*就可以把中间字符匹配到,但是必须制定起始位置)
#.
result1 = re.match('^Hello.*Demo$',content) print(result1) <_sre.SRE_Match object; span=(0, 41), match='Hello 123 4567 World_This is a Regex Demo'> print(result1.group()) Hello 123 4567 World_This is a Regex Demo print(result1.span()) (0, 41) #匹配目标
content1 = 'Hello 1234567 World_This is a Regex Demo' result2 = re.match('^Hello\s(\d+)\sWorld.*Demo$',content1) print(result2) <_sre.SRE_Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'> print(result2.group(1))#将第一括号括起来的内容打印出来,依次可推group(2) print(result2.span()) (0, 40) #贪婪匹配
#
result3 = re.match('^He.*(\d+).*Demo$',content) print(result3) <_sre.SRE_Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'> print(result3.group(1))#打印结果为7,意味着‘.*’将前面的数字全部包含了 #非贪婪匹配
result4 = re.match('^He.*?(\d+).*Demo$',content)#注意看我的细节:“?” print(result4) <_sre.SRE_Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'> print(result4.group(1)) #匹配模式
content = '''Hello 1234567 World_This is a Regex Demo''' result5 = re.match('^He.*?(\d+).*?Demo$',content)#无视换行的下场 print(result5) None result6 = re.match('^He.*?(\d+).*?Demo$',content,re.S)#添加参数re.S就可以无视换行 print(result6) #转义
content2 = 'price is $5.00' result7 = re.match('price is \$5\.00',content2)#添加‘\’即可把特殊字符进行转义 print(result7) #总结:尽量使用泛匹配,使用括号得到匹配目标,尽量使用非贪婪模式、有换行符就用re.S#re.search(扫描整个字符串并返回第一个成功的匹配)content3 = 'Extra stings Hello 123232 World_This is a Regex Demo Extra stings' result8 = re.match('Hello.*?(\d+).*?Demo',content3) print(result8)#结果为None,说明从开始就匹配失败 result9 = re.search('Hello.*?(\d+).*?Demo',content3)#re.search不管开头是否相符,只要条件满足就可以找到 print(result9) print(result9.group(1)) #总的来说,能用search就不用match #匹配演练
html = '''<div id="songs-list"> <h2 class="title">经典老歌</h2> <p class="introduction"> 经典老歌列表 </p> <ul id="list"class="list-group"> <li data-view="2">一路上有你</li> <li data-view="7"> <a href="/2.mp3"singer="任贤齐">沧海一声笑</a> </li> <li data-view="4"class="active"> <a href="/3.mp3"singer="齐秦">往事随风</a> </li> <li data-view="6"><a href="/4.mp3"singer="begoud">光辉岁月</a></li> <li data-view="5"><a href="/5.mp3"singer="陈慧琳">记事本</a><li> <li data-view="5"> <a href="/6.mp3"singer="邓丽君"><li class="fa fa-user">但愿人长久</a> </li> </ul> </div>''' result = re.search('<li.*?active.*?singer="(.*?)">(.*?)</a>',html,re.S) print(result.group(1),result.group(2)) result1 = re.search('<li.*?singer="(.*?)">(.*?)</a>',html,re.S) print(result1.group(1),result1.group(2)) result2 = re.search('<li.*?singer="(.*?)">(.*?)</a>',html) if result2: print(result2.group(1),result2.group(2))#re.search()只找寻一个结果 #re.findall(搜索字符,以列表的形式返回全部匹配的字符串) result3 = re.findall('<li.*?href="(.*?)".*?singer="(.*?)">(.*?)</a>',html,re.S) print(result3)#以元组的形式将所有值输出 print(type(result3)) for result3 in result3: print(result3) print(result3[0],result3[1],result3[2]) #关于换行问题,“(<a.*?>)?”括号内表示一个组,“?”表示a标签可能有
result4 = re.findall('<li.*?>\s*?(<a.*?>)?(\w+)(</a>)?\s*?</li>',html,re.S) print(result4) for result4 in result4: print(result4[1]) #re.sub(替换字符串中每一个匹配的字符串后返回替换后的字符串)
content6 = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings' content5 = re.sub('\d+','Replacement',content6) print(content5) #在原来的基础上增加 content4 = re.sub('(\d+)',r'\1 45545',content6) print(content4) html = '''<div id="songs-list"> <h2 class="title">经典老歌</h2> <p class="introduction"> 经典老歌列表 </p> <ul id="list"class="list-group"> <li data-view="2">一路上有你</li> <li data-view="7"> <a href="/2.mp3"singer="任贤齐">沧海一声笑</a> </li> <li data-view="4"class="active"> <a href="/3.mp3"singer="齐秦">往事随风</a> </li> <li data-view="6"><a href="/4.mp3"singer="begoud">光辉岁月</a></li> <li data-view="5"><a href="/5.mp3"singer="陈慧琳">记事本</a></li> <li data-view="5"> <a href="/6.mp3"singer="邓丽君"><li class="fa fa-user">但愿人长久</a> </li> </ul> </div>''' html2 = re.sub('<a.*?>|</a>','',html)#把a标签替换掉 result10 = re.findall('<li.*?>(.*?)</li>',html2,re.S) print(result10) for result10 in result10: print(result10.strip())#去掉换行符 #re.compile(将正则字符串编译成正则表达式对象,以便于复用该匹配对象)
content8 = '''hello 1234545 World_This is a Regex Demo''' pattern = re.compile('hello.*Demo',re.S) result12 = re.match(pattern,content8) print(result12) result13 = re.match('hello.*Demo',content8,re.S) print(result13)
四、实战演练
import re
import requests
content = requests.get('https://book.douban.com/').text
#这里我照着写着写着也出错了,我有一个方法就是先把这段源代码copy下来再替换成.*?
pattern = re.compile('<li.*?"cover">.*?href="(.*?)" title="(.*?)".*?"more-meta".*?"author">(.*?)</span>.*?"year">(.*?)</span>.*?</li>',re.S)
result88 = re.findall(pattern,content)
#print(result88)
for result in result88:
url,name,author,date = result
author = re.sub('\s','',author)#使用re.sub将(\n)代替
date = re.sub('\s','',author)
print(url,name,author,date)
以上是关于正则表达式re的主要内容,如果未能解决你的问题,请参考以下文章