R语言 | 关于正则表达式的两个使用体会
Posted R语言与SPSS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言 | 关于正则表达式的两个使用体会相关的知识,希望对你有一定的参考价值。
我就在这里等你关注,不离不弃
——A·May
分享一下用正则表达式的感受,算是对正则的小总结,不是很专业,仅供参考。
May
2018年4月29日
library(RCurl)
## Loading required package: bitops
library(XML)
library(tidyverse)## -- Attaching packages ---------------------------------- tidyverse 1.2.1 --
## √ ggplot2 2.2.1 √ purrr 0.2.4 ## √ tibble 1.4.2 √ dplyr 0.7.4 ## √ tidyr 0.7.2 √ stringr 1.2.0 ## √ readr 1.1.1 √ forcats 0.2.0
## -- Conflicts ------------------------------------- tidyverse_conflicts() -- ## x tidyr::complete() masks RCurl::complete() ## x dplyr::filter() masks stats::filter() ## x dplyr::lag() masks stats::lag()
library(rlist)
imdb_url <- 'https://www.imdb.com/chart/top'
#请求到网页html文件
top <- getURL(imdb_url)
#解析html文件
parse_top <- htmlParse(top,encoding = 'UTF-8')
#读表
top_table <- readHTMLTable(parse_top)
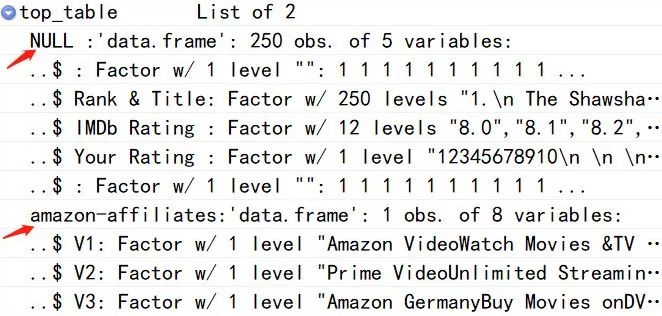
#列表分为两层,我们分别打开
top_table1 %>%`[[`(1)
top_table2 %>%`[[`(2)
#需要第一层的列表
top_f <- top_table1[,2:3]
#一波清洗,正则表达式绝对不是一次可以写完的!
head(top_f,3)## Rank & Title IMDb Rating ## 1 1.\n The Shawshank Redemption\n (1994) 9.2 ## 2 2.\n The Godfather\n (1972) 9.2 ## 3 3.\n The Godfather: Part II\n (1974) 9.0
#清洗:1将年份提取出来;2去除掉空格和\n#没有年份的变量,所以新建变量
#按正则进行提取对应的内容,不是对应的行内容,用str_extract_all#年份是用[0-9]数字,{4}表示一共有四个数字#如下:结果是列表,需要转为向量
head(top_f$year <- str_extract_all(top_f$`Rank & Title`,"[0-9]{4}"),4)## [[1]] ## [1] "1994" ## ## [[2]] ## [1] "1972" ## ## [[3]] ## [1] "1974" ## ## [[4]] ## [1] "2008"
#用unlist,发现出错了,因为发现有一条信息有两个年份,这就很奇怪top_f$year <- rank="">%unlist

#多列的list就需要改用list.rbind进行向量化,下面的操作到data.frame就可以模式化了
top_f$year <- str_extract_all(top_f$`Rank & Title`,"[0-9]{4}")%>%list.rbind()%>%data.frame()%>%.$X1
#查看记录,已经可以了
head(top_f$year,3)
## [1] 1994 1972 1974 ## 84 Levels: 1921 1924 1925 1926 1927 1928 1931 1934 1936 1939 1940 ... 2049
#处理第一列,处理掉第一段的字符#\n 的正则写法用[\\n],()的写法用[()],年份的写法用[0-9]{4},序号从1到250对应的写法用[0-9]{1,3}
top_f$`Rank & Title` <- str_replace_all(top_f$`Rank & Title` ,"[\\n]|[()]|[0-9]{4}|[0-9]{1,3}.","")%>%str_trim(side="both")
#结果已经OK
head(top_f$`Rank & Title`,3)## [1] "The Shawshank Redemption" "The Godfather" ## [3] "The Godfather: Part II"
#对结果用year的降序进行整理
top_ff <->%arrange(desc(as.character(year)))
#我天,还有2049年的,肯定是哪出错了,没注意到.当然,这次重在用正则,内容先忽略
head(top_ff)## Rank & Title IMDb Rating year ## 1 Blade Runner 8.1 2049 ## 2 Avengers: Infinity War 8.9 2018 ## 3 Coco 8.4 2017 ## 4 Three Billboards Outside Ebbing, Missouri 8.2 2017 ## 5 Logan 8.1 2017 ## 6 Dangal 8.3 2016
library(rlist)
#对于正则表达式,我的观点是:
#那个表 是用来理解和用的时候查的!!!! 别费时间在那上面,过目不忘的请忽略
#然后,其实用到正则的概率不多,毕竟我们又不是用正则来做爬虫,所以了解基础的就好
#之前被字符困扰,现在摸索的是这样的:
#标点符号用下面的方式解决,虽然有点麻烦
#我的这个写法就是,需要删除什么就一点一点删除,需要批量处理的时候再对应附录去找\d\D\s\S等
c <- "我是一个坏 人9527wc() .?-=+\n,/"
#无效写法:删除括号
c%>%str_replace_all("()","")## [1] "我是一个坏 人9527wc() .?-=+\n,/"
#有效写法:删除括号
c%>%str_replace_all("[()]","")## [1] "我是一个坏 人9527wc .?-=+\n,/"
#处理空格:正常空格一般是一个,非正常的一般是2个以上,所以写法是[ ]{2,},[]里面有一个空格
c%>%str_replace_all("[()]|[ ]{2,}","")## [1] "我是一个坏 人9527wc.?-=+\n,/"
library(jiebaRD)
library(jiebaR)
#关于文字的写法,就如上次的科学研究方法中的
rs <- read.csv("rways.csv")
head(rs)## X id grade title major ## 1 1 2121673 12级 网络内容服务商竞争行为的演化博弈分析 信息管理 ## 2 2 2131636 13级 《明史·艺文志》“易”类书目研究 图书馆 ## 3 3 2131636 13级 《明史·艺文志》“易”类书目研究 图书馆 ## 4 4 2141589 14级 《孙子兵法》对竞争情报工作的启示研究 信息管理 ## 5 5 2141589 14级 《孙子兵法》对竞争情报工作的启示研究 信息管理 ## 6 6 2141589 14级 《孙子兵法》对竞争情报工作的启示研究 信息管理 ## majorways easyornot innovation useornot ## 1 演化博弈模型 经过学习可掌握 有 不会 ## 2 文献分析法 已经掌握 有 会 ## 3 统计分析法 经过学习可掌握 有 会 ## 4 文献综述法 已经掌握 无 会 ## 5 跨学科研究法 经过学习可掌握 有 会 ## 6 案例分析法 经过学习可掌握 有 不会
#包含英文的研究方法#第一步,写正则,包含英文的研究方法,即.*[a-zA-Z].* # .* 表示 有任意字符任意数量
#其余步骤同上
s4 <- str_extract_all(rs$majorways,".*[a-zA-Z].*")%>%unlist()%>%str_replace_all("\\s","")%>%unique()
s4## [1] "DEMATEL法" "PEST分析法" "AHP-TOPSIS相结合" ## [4] "SPSS统计分析法" "SWOT分析法"
学习数据挖掘交流平台
长按二维码识别
以上是关于R语言 | 关于正则表达式的两个使用体会的主要内容,如果未能解决你的问题,请参考以下文章