珍藏版长文详解python正则表达式
Posted 深度学习自然语言处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了珍藏版长文详解python正则表达式相关的知识,希望对你有一定的参考价值。
阅读大概需要15分钟
跟随小博主,每天进步一丢丢

目录
一、正则函数
二、re模块调用
三、贪婪模式
四、分组
五、正则表达式修饰符
六、正则表达式模式
七、常见的正则表达式
导读
注:例子中如果涉及部分还未讲解的知识,若例子未看懂,可以将下面内容都看完后再回过头来看。
一、正则函数
1. re.match函数
功能:re.match尝试从字符串的起始位置匹配一个模式,如果匹配成功则返回一个匹配的对象,如果不是起始位置匹配成功的话,match()就返回none。
语法:re.match(pattern,string,flags=0)
例子:

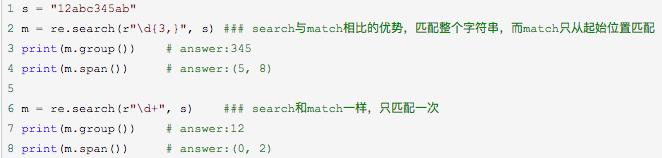
2. re.search函数
功能:re.search 扫描整个字符串并返回第一个成功的匹配,如果匹配成功re.search方法返回一个匹配的对象,否则返回None。
语法:re.search(pattern, string, flags=0)
例子:
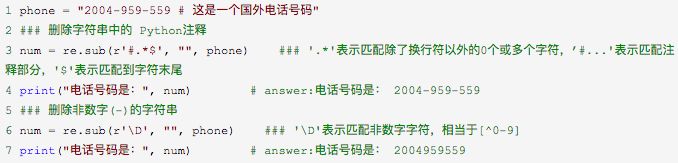
3. re.sub函数
功能:re.sub用于替换字符串中的匹配项。
语法:re.sub(pattern, repl, string, count=0, flags=0)
repl参数可以为替换的字符串,也可以为一个函数。
如果repl是字符串,那么就会去替换字符串匹配的子串,返回替换后的字符串;
如果repl是函数,定义的函数只能有一个参数(匹配的对象),并返回替换后的字符串。
例子:
count可指定替换次数,不指定时全部替换。例如:

repl可以为一个函数。例如:

4. re.subn函数
功能:和sub函数差不多,但是返回结果不同,返回一个元组“(新字符串,替换次数)”
例子:

5. re.compile函数
功能:compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。如果匹配成功则返回一个Match对象。
语法:re.compile(pattern[, flags])
注:compilte函数调用情况比较复杂,下面会有一节专门讲解。
6. findall函数
功能:在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
语法:findall(string[, pos[, endpos]])
例子:

7. re.finditer函数
功能:在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
语法:re.finditer(pattern, string, flags=0)
例子:

8. re.split函数
功能:split 方法用pattern做分隔符切分字符串,分割后返回列表。如果用'(pattern)',那么分隔符也会返回。
语法:re.split(pattern, string[, maxsplit=0, flags=0])
例子:

小结:
1. 函数辨析:match和search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
re.search匹配整个字符串,直到找到一个匹配。
2. 函数辨析:3个匹配函数match、search、findall
match 和 search 只匹配一次 ,匹配不到返回None,findall 查找所有匹配结果。
3. 函数返回值
函数re.finditer 、 re.match和re.search 返回匹配对象,而findall、split返回列表。
4. re.compile函数是个谜。
二、re模块调用
re模块的使用一般有两种方式:
方法1:
直接使用上面介绍的 re.match, re.search 和 re.findall 等函数对文本进行匹配查找。
方法2:
(1)使用compile 函数将正则表达式的字符串形式编译为一个 Pattern 对象;
(2)通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果(一个 Match 对象);
(3)最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作。
接下来重点介绍一下compile函数。
re.compile函数用于编译正则表达式,生成一个Pattern对象,调用形式如下:
re.compile(pattern[, flag])
其中,pattern是一个字符串形式的正则表达式,flag是一个可选参数(下一节具体讲解)。
例子:

1. match函数
使用语法:
(1)re.match(pattern, string[, flags])
这个之前讲解过了。
(2)Pattern对象:match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
例子:
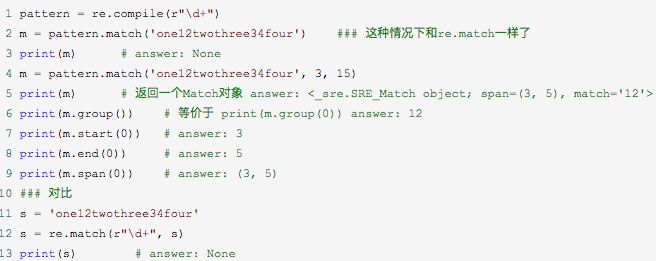
当匹配成功时会返回一个Match对象,其中:
group([0, 1, 2,...]): 可返回一个或多个分组匹配的字符串,若要返回匹配的全部字符串,可以使用group()或group(0)。
start(): 匹配的开始位置。
end(): 匹配的结束位置。
span(): 包含起始、结束位置的元组。等价于(start(), end())。
groups(): 返回分组信息。等价于(m.group(1), m.group(2))。
groupdict(): 返回命名分组信息。
例子:

2. search函数
使用语法:
(1)re.search(pattern, string, flags=0)
这个函数前面已经讲解过了。
(2)Pattern对象:search(string[, pos[, endpos]])
例子:

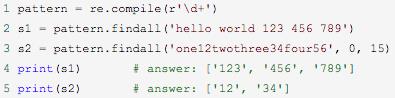
3. findall函数
使用语法:
(1)findall(string[, pos[, endpos]])
这个函数前面已经讲解过了。
(2)Pattern对象:findall(string[, pos[, endpos]])
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
例子:
4. finditer函数
使用语法:
(1)re.finditer(pattern, string, flags=0)
这个函数前面已经讲解过了。
(2)Pattern对象:finditer(string[, pos[, endpos]])
finditer 函数与 findall 类似,但是它返回每一个匹配结果(Match 对象)的迭代器。
例子:
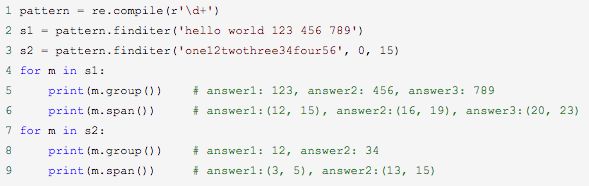
5. split函数
使用语法:
(1)re.split(pattern, string[, maxsplit=0, flags=0])
这个函数前面已经讲解过了。
(2)Pattern对象:split(string[, maxsplit]])
maxsplit 可指定分割次数,不指定将对字符串全部分割。
例子:

6. sub函数
使用语法:
(1)re.sub(pattern, repl, string, count=0, flags=0)
这个函数前面已经讲解过了。
(2)Pattern对象:sub(repl, string[, count])
当repl为字符串时,可以用\id的形式引用分组,但不能使用编号0;当repl为函数时,返回的字符串中不能再引用分组。
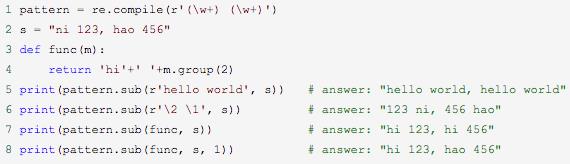
7. subn函数
subn和sub类似,也用于替换操作。使用语法如下:
Pattern对象:subn(repl, string[, count])
返回一个元组,元组第一个元素和sub函数的结果相同,元组第二个元素返回替换次数。
例子:

小结:
1. 使用Pattern对象的match、search、findall、finditer等函数可以指定匹配字符串的起始位置。
2. 对re模块的两种使用方式进行对比:
使用 re.compile 函数生成一个 Pattern 对象,然后使用 Pattern 对象的一系列方法对文本进行匹配查找;
直接使用 re.match, re.search 和 re.findall 等函数直接对文本匹配查找。
例子:

在上述例子中,我们发现他们共用了同一个正则表达式,表明上看好像没发现什么问题,但是当我们结合正则表达式的匹配过程进行分析时,就会发现这两种调用方式的效率是不一样的。使用正则表达式进行匹配的流程如下图所示:
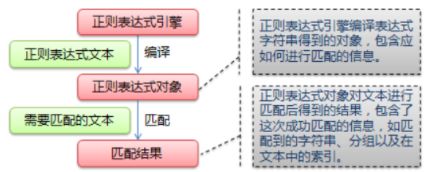
所以匹配流程是先对正则表达式进行编译,然后得到一个对象,再使用该对象对需要匹配的文本进行匹配。这时我们就发现方式2会对正则表达式进行了多次编译,这样效率不就降低了嘛。
所以我们可以得到如下结论:
如果一个正则表达式要用多次,那么出于效率考虑,我们可以预先编译正则表达式,然后调用的一系列函数时复用。如果直接使用re.match、re.search等函数,则需要每一次都对正则表达式进行编译,效率就会降低。因此在这种情况下推荐使用第一种方式。
三、贪恋匹配
正则表达式匹配时默认的是贪恋匹配,也就是会尽可能多的匹配更多字符。如果想使用非贪恋匹配,可以在正则表达式中加上'?'。
下面,我们来看1个实例:

四、分组
如果你想要提取子串或是想要重复提取多个字符,那么你可以选择用定义分组的形式。用()就可以表示要提取的分组(group),接下来用几个实例来理解一下分组的使用方式:
例子1:
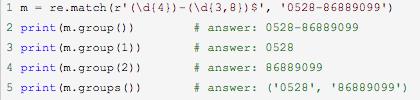
正则表达式'(\d{4})-(\d{3, 8})$'表示匹配两个分组,第一个分组(\d{4})是一个有4个数字的子串,第二个分组(\d{3,8})表示匹配一个数字子串,子串长度为3到8之间。
例子2:

正则表达式'(\d{1,3}\.){3}\d{1,3}‘的匹配过程分为两个部分,'(\d{1,3}\.){3}'表示匹配一个长度为1到3之间的数字子串加上一个英文句号的字符串,重复匹配 3 次该字符串,'\d{1,3}'表示匹配一个1到3位的数字子串,所以最后得到结果123.456.78.90。
例子3:

(.*)第一个分组,.* 代表匹配除换行符之外的所有字符。(.*?) 第二个匹配分组,.*? 后面加了个问号,代表非贪婪模式,只匹配符合条件的最少字符。后面的一个 .* 没有括号包围,所以不是分组,匹配效果和第一个一样,但是不计入匹配结果中。
group() 等同于group(0),表示匹配到的完整文本字符;
group(1) 得到第一组匹配结果,也就是(.*)匹配到的;
group(2) 得到第二组匹配结果,也就是(.*?)匹配到的;
因为只有匹配结果中只有两组,所以如果填 3 时会报错。
扩展:其他组操作如:命名组的使用、定义无捕获组、使用反向引用等,这部分内容还未弄懂,想了解的同学可以查看以下链接http://wiki.jikexueyuan.com/project/the-python-study-notes-second-edition/string.html
五、正则表达式修饰符


六、正则表达式模式
下面列出了正则表达式模式语法中的特殊元素。
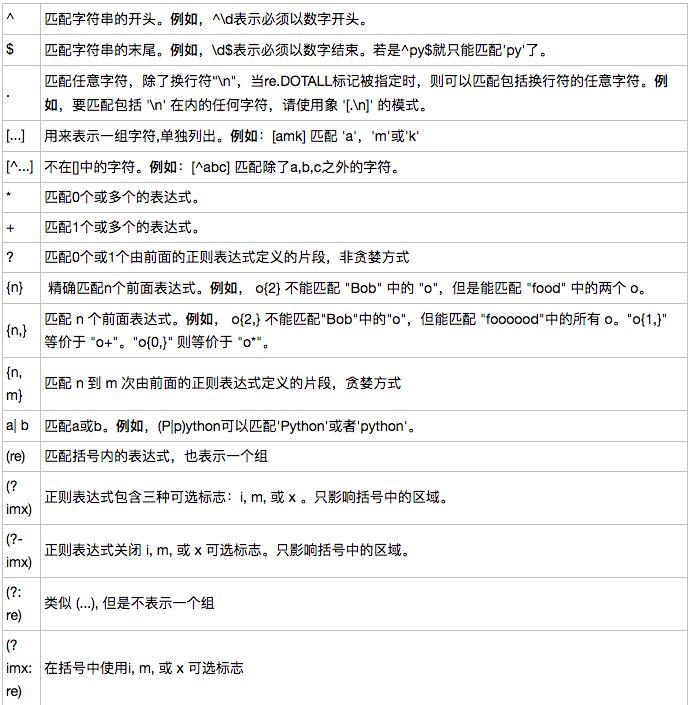
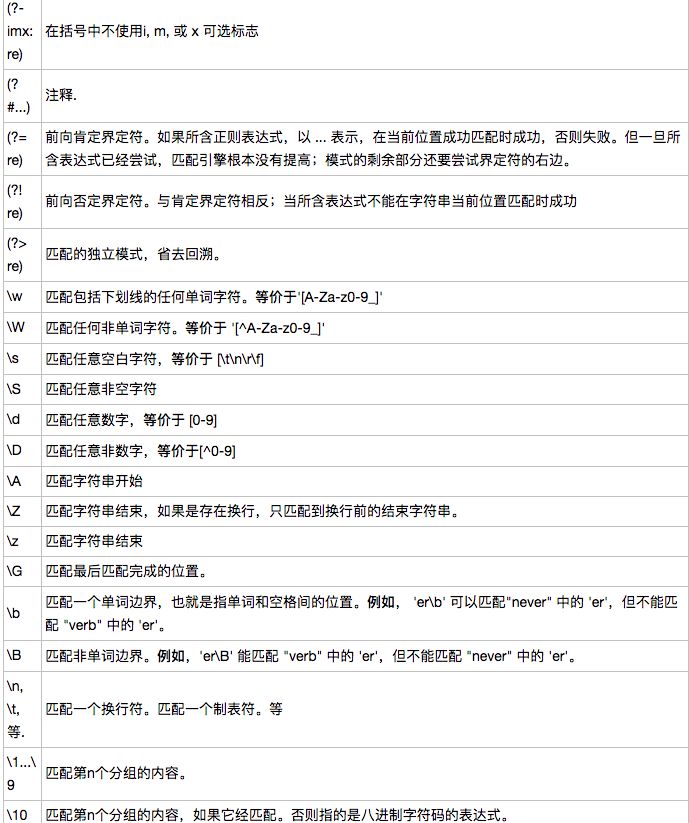
七、常见的正则表达式
通常情况下,通过实例学习是一个高效的途径。接下来我将整理一些常见的正则表达式应用实例,大家可以试着将前面学的理论知识应用于实践啦。
(1)匹配国内13、15、18开头的手机号码的正则表达式
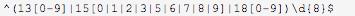
(2)匹配中文的正则表达式
中文的unicode编码范围主要在 [\u4e00-\u9fa5],这个范围之中不包括全角(中文)标点。当我们想要把文本中的中文汉字提取出来时可以使用如下方式:

(3)匹配由数字、26个英文字母或下划线组成的字符串的正则表达式
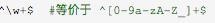
(4)匹配金额,精确到 2 位小数
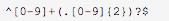
(5)提取文本中的URL链接
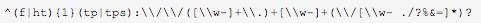
(6)匹配身份证号码

(7)匹配整数

一丢丢话
注:由于平时正则用的太少,所以没有太多实用经验,本文内容只是研读了多个博客文章之后的整理笔记,对正则的解读很浅显。正则的相关知识太多,这里只是整理了我理解的部分内容,后续还会补充。
更多正则的相关内容可以参考以下文章:
极客学院的学习笔记:
1. python之旅 http://wiki.jikexueyuan.com/project/explore-python/Regular-Expressions/README.html
2. python网络爬虫 http://wiki.jikexueyuan.com/project/python-crawler/regular-expression.html
3. 轻松学习正则表达式 http://wiki.jikexueyuan.com/project/regex/introduction.html
4. python正则表达式指南
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
最后,推荐一个更强大的正则表达式引擎-python的regex模块。
IELTS a bit
reluctance n.[电磁]磁阻;勉强;不情愿
righteous adj. 正义的;正直的;公开的
victimise vt.使受害;使牺牲;欺骗
viscous adj.粘性的;黏的
gadget n.小玩意;小器具;小配件;诡计
推荐阅读:


以上是关于珍藏版长文详解python正则表达式的主要内容,如果未能解决你的问题,请参考以下文章