正则表达式的常见用法-读取豆瓣图书信息
Posted 怪兽宇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式的常见用法-读取豆瓣图书信息相关的知识,希望对你有一定的参考价值。
上一章说了正则表达式的基本用法,这章我们继续来说正则表达式的常见用法,以及用正则表达式来对网页源代码进行读取。
re.match
语法:re.match(pattern, string, flags=0)
含义:从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功,就会返回none。
常见用法:
import re
count = 'Hello 123 4456 world'
result = re.match('^Hello.* world$',count)
print(result.group())Hello 123 4456 world
贪婪匹配
贪婪模式,总是尝试匹配尽可能多的字符
import re
count = '<a>aaa</a><a>aaaa</a>'
result = re.match('^<a>(.*)</a>$',count)
print(result.group())aaaaaaa
非贪婪匹配
非贪婪模式则相反,总是尝试匹配尽可能少的字符,一旦发现匹配符合要求,立马就匹配成功,而不会继续匹配下去
import re
count = '<a>aaa</a><a>aaaa</a>'
result = re.match('^<a>(.*?)</a>$',count)
print(result.group(1))aaaaaaa
匹配模式
.* 不能匹配换行符。 而我们要匹配换行符, 就需要用到re.S。 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
import re
count = '''Hello 123445
6world'''
result = re.match('Hello.*world$',count)
print(result)None
import re
count = '''Hello 123445
6world'''
result = re.match('Hello.*world$',count, re.S)
print(result.group())Hello 123445
6world
re.findall()
语法:findall(pattern, string, flags=0)
含义: 返回字符串中所有与正则表达式相匹配的内容, 并以列表形式返回
import re
s='1113446777'
p=r'1(.*?)6(.*)7'
m = re.findall(p,s)
m[(‘11344’, ‘77’)]
总结: 在进行正则表达式匹配时, 我们尽可能的使用非贪婪匹配.*?, 要想匹配的内容就加(),有换行符就用re.S。 因为re.match方法需要定义匹配的头部和尾部,而re.search会在找到第一个符合条件之后, 就会停止搜索。我们需要找出全文本中所有符合条件的字符串, 这时,我们就需要用re.findall()
re.sub()
含义:用于替换字符串中的匹配项, 返回被替换后的字符串
语法:re.sub(pattern,repl,string)
pattern:表示正则表达式中的模式字符串;
repl:被替换的字符串(既可以是字符串,也可以是函数);
string:要被处理的,要被替换的字符串;
import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
a = re.sub(r'\s+', '-', text)
a‘JGood-is-a-handsome-boy,-he-is-cool,-clever,-and-so-on…’
re.compile
含义: 将正则字符串编译成正则表达式对象, 以便于可以重复使用该匹配模式
语法:re.compile(strPattern[, flag]
第二个参数flag是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如re.I | re.M
import re
s='1113446777'
p=re.compile('1(.*?)6(.*)7', re.S)
m = re.findall(p,s)
m[(‘11344’, ‘77’)]
实战-读取豆瓣读书中源代码的信息
首先, 我们打开豆瓣读书的页面, 并打开豆瓣读书的源代码页面, 找到含有图书信息的源代码。
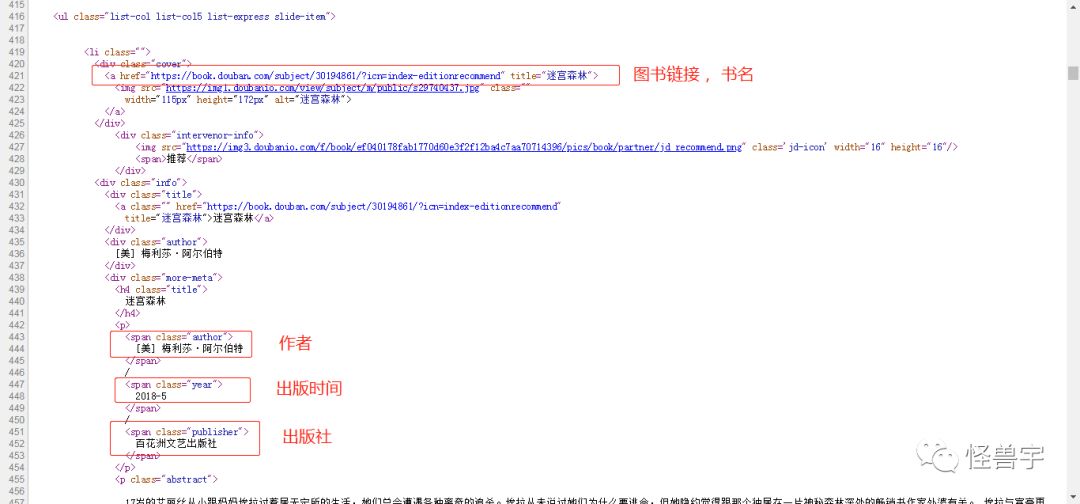
我们根据源代码中的信息来写对应的正则表达式。
首先我们用requests库的get请求来读取出豆瓣读书的源代码
import requests
import re
content = requests.get('https://book.douban.com/').text写要读出想要信息的正则表达式。
patter = re.compile('<li.*?class="cover".*?href="(.*?)" title="(.*?)".*?more-meta.*?author">(.*?)</span>.*?year">(.*?)</span>.*?</li>',re.S)用正则表达式来进行读取,并用for循环来打印出。
results = re.findall(patter,content)
for result in results:
url, name, author, date = result
print(url, name, author, date)这样我们就读取出了想要的图书信息
如果我们不想让显示的结果有这么多行, 我们可以用re.sub()来对换行符进行替换。
results = re.findall(patter,content)
for result in results:
url, name, author, date = result
author = re.sub(r'\s','-',author)
date = re.sub(r'\s','-', date)
print(url, name, author, date)以上就是正则表达式的常见用法
以上是关于正则表达式的常见用法-读取豆瓣图书信息的主要内容,如果未能解决你的问题,请参考以下文章