正则表达式的隐藏陷阱,你都了解么?
Posted 算法与数学之美
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式的隐藏陷阱,你都了解么?相关的知识,希望对你有一定的参考价值。
几天前,一个在线项目的监控系统突然报告了一个异常。在检查了相关资源的使用率后,我们发现 CPU 利用率接近 100%。然后,我们用 Java 附带的线程转储工具导出了这个异常相关的堆栈信息。
我们发现,所有堆栈信息都指向一个名为 “validateUrl” 的方法,它在堆栈上有超过 100 个错误消息。通过检查代码,我们发现该方法的主要功能是验证 URL 的合法性。
一个正则表达式是如何导致如此高的 CPU 利用率的呢?为了重现这个错误,我们提取了关键代码,并进行了简单的单元测试。
Java
1 2 3 4 5 6 7 8 9 |
public static void main(String[] args) { String badRegex = "^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\\\/])+$"; String bugUrl = "http://www.fapiao.com/dddp-web/pdf/download?request=6e7JGxxxxx4ILd-kExxxxxxxqJ4-CHLmqVnenXC692m74H38sdfdsazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf"; if (bugUrl.matches(badRegex)) { System.out.println("match!!"); } else { System.out.println("no match!!"); } } |
当我们运行上面的示例时,资源监视器显示,一个名为 Java 的进程 CPU 利用率已经飙升到 91.4%。
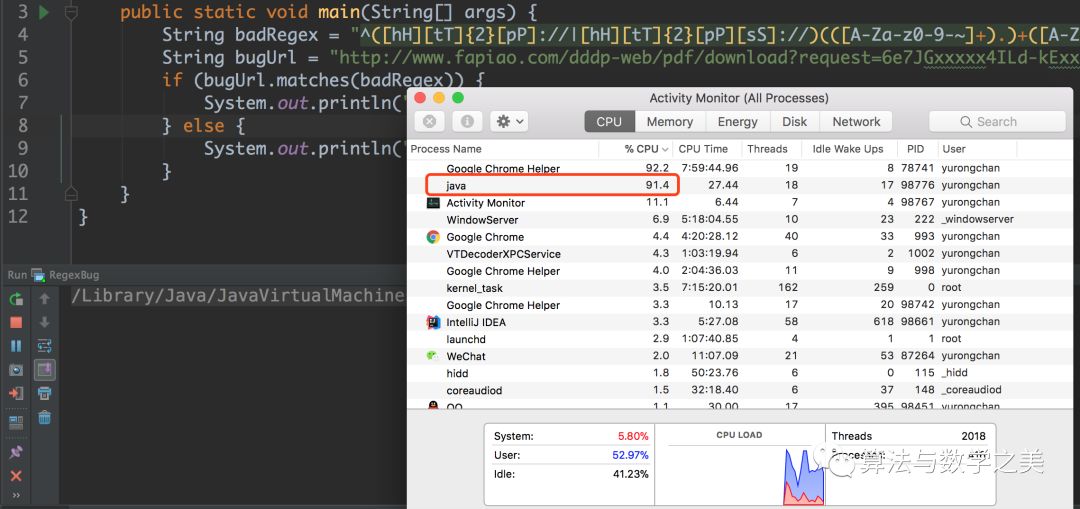
现在我们几乎可以判断,正则表达式是导致 CPU 利用率飙升的原因。
所以,让我们聚焦于正则表达式:
1 2 |
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\/])+$
|
这个正则表达式看起来并没有什么异常。它可以分为三部分:
第一部分用于匹配 http 和 https 协议。 第二部分用于匹配 www. 字符。第三部分用于匹配剩余字符。我盯着这个正则表达式看了很久,也没发现什么大问题。
事实上,Java 用来处理正则表达式所用的 NFA 引擎是引起高 CPU 利用率的关键。当进行字符匹配时, NFA 会使用一种称为“回朔法”(backtracking)的方法。一旦发生回溯,所花费的时间将变得非常长。可能是几分钟,也可能长达数小时。所需时间的长短取决于发生回溯的次数和回溯的复杂度。
也许有些人还不太清楚回溯是什么。没关系,让我们从正则表达式的原理开始。
正则表达式引擎
正则表达式是一组便于匹配的符号。为了实现如此复杂且强大的匹配语法,我们必须有一组算法,算法的实现称为正则表达式引擎。简而言之,正则表达式的实现引擎有两种:一种是 DFA (有穷确定自动机 Deterministic Final Automata),另一种是 NFA (有穷非确定自动机 Non deterministic Finite Automaton).
这是两种不同的自动机。在这里,我们不会深入讨论它们的原理。简单地说,DFA 的时间复杂度是线性的。它更稳定,但功能有限。NFA 的时间复杂度相对不稳定。 根据正则表达式的不同,时间有时长,有时短。NFA 的优点是它的功能更强大,所以被 Java、.NET、Perl、Python、Ruby 和 php 用来处理正则表达式。
NFA 是怎样进行匹配的呢?我们用下面的字符串和表达式作为例子。
Java
1 2 |
text="Today is a nice day." regex="day" |
记住,NFA 匹配是基于正则表达式的。也就是说,NFA 将依次读取正则表达式的匹配符,并将其与目标字符串进行匹配。如果匹配成功,它将转到正则表达式的下一个匹配符。否则,它将继续与目标字符串的下一个字符进行比较。
让我们一步一步地来看一下上面的例子。
首先,提取正则表达式的第一个匹配符:
d。然后,将它与字符串的第一个字符T进行比较。不匹配,所以转到下一个。第二个字符是o,也不匹配。继续转到下一个,也就是d。匹配成功。于是,读取正则表达式的第二个字符:a。正则表达式的第二个匹配符是:
a。将它与字符串的第四个字符a进行比较。又匹配了。于是继续读取正则表达式的第三个字符y。正则表达式的第三个匹配符是
y。让我们继续与字符串的第五个字符比较。匹配成功。接着,尝试读取正则表达式的下一个字符,发现没有字符了,因此匹配结束。
以上是 NFA 的匹配过程。实际的匹配过程要复杂得多。不过,匹配的原理都是一样的。
NFA 回溯法
现在,你已经了解了 NFA 是如何进行字符串匹配的。下面,让我们来看一下本文的重点:回溯法。我们将使用下面的例子,以便更好的解释回朔法。
Java
1 2 |
text="abbc" regex="ab{1,3}c" |
这是一个比较简单的例子。正则表达式以 a 开始,以 c 结束。它们之间有以 1-3 个 b 组成的字符串。NFA 的匹配过程如下:
首先,读取正则表达式的第一个匹配符
a,并将其与字符串的第一个字符a进行比较。两者匹配,所以,移动到正则表达式的第二个字符。读取正则表达式的第二个匹配符
b{1,3},将它与字符串的第二个字符b进行比较。它们又匹配了。b{1,3}代表 1-3 个b,基于NFA的贪婪特性(即,尽可能地进行匹配),此时它不会读取正则表达式的下一个匹配符,而是仍然使用b{1,3}与字符串的第三个字符b进行比较。它们匹配了。于是继续用b{1,3}与字符串的第四个字符c进行比较。它们不匹配。 回溯 就出现在这里回溯是如何进行的?回溯后,字符串中已被读取的第四个字符
c将被放弃。指针将返回到字符串的第三个字符。接着,正则表达式的下一个匹配符c会被用来与待匹配字符串当前指针的下一个字符c进行对比。两者是匹配的。这时,字符串最后一个字符已经被读取。匹配结束。
让我们回过头来看看用于验证 URL 的正则表达式。
Java
1 |
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\/])+$ |
出现问题的 URL 如下:
Java
1 |
http://www.fapiao.com/dzfp-web/pdf/download?request=6e7JGm38jfjghVrv4ILd-kEn64HcUX4qL4a4qJ4-CHLmqVnenXC692m74H5oxkjgdsYazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf |
我们将正则表达式分为三个部分:
第1部分:验证协议。
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)。第2部分:验证域。
(([A-Za-z0-9-~]+).)+。第3部分:验证参数。
([A-Za-z0-9-~\\/])+$。
可以发现,验证 http:// 协议这部分的正则表达式没有什么问题。但是,当用 xxxx. 验证 www.fabiao.com 时,匹配过程如下:
匹配
www。匹配
fapiao。匹配
com/dzfp-web/pdf/download?request=6e7JGm38jf.....。由于“贪婪”的性质,程序会一直试图读取下一个字符进行匹配,直至上述一长串字符串读取完毕,发现找不到点号。此时,程序开始一个字符一个字符进行回溯。
这是正则表达式中的第一个问题。
另一个问题出现在正则表达式的第三部分。可以看到,有问题的 URL 具有下划线(_)和百分号(%),但是与第三部分对应的正则表达式中则没有。因此,只有在匹配完一长串字符之后,程序才发现两者不匹配,然后进行回溯。
这是这个正则表达式中的第二个问题。
解决方案
你已经知道回溯是导致问题的原因。所以,解决问题的方法就是减少回溯。事实上,你会发现,如果把下划线和百分比符号添加到第三部分,程序就会变得正常。
Java
1 2 3 4 5 6 7 8 9 |
public static void main(String[] args) { String badRegex = "^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~_%\\\\/])+$"; String bugUrl = "http://www.fapiao.com/dddp-web/pdf/download?request=6e7JGxxxxx4ILd-kExxxxxxxqJ4-CHLmqVnenXC692m74H38sdfdsazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf"; if (bugUrl.matches(badRegex)) { System.out.println("match!!"); } else { System.out.println("no match!!"); } } |
运行上面的程序,它会打印出“ match!! ”。
如果未来其他的 URL 中含有别的混乱字符怎么办? 再次修正代码? 当然不现实!
事实上,正则表达式有三种模式:贪婪模式 ,勉强模式和独占模式。
如果你在正则表达式中添加一个 ? 标志,贪婪模式将变成勉强模式。此时,它将尽可能少地匹配。然而,勉强模式下回溯仍可能出现。例如:
Java
1 2 |
text="abbc" regex="ab{1,3}?c" |
正则表达式的第一个字符 a 与字符串的第一个字符 a 相匹配。正则表达式的第二个运算符 b{1,3}? 匹配了字符串的第二个字符 b 。由于最小匹配的原则,正则表达式将读取第三个运算符 c,并与字符串第三个字符 b 进行比较。两者不匹配。因此,程序进行回溯并将正则表达式的第二个运算符 b{1,3}? 与字符串的第三个字符 b 进行比较。现在匹配成功了。之后,正则表达式的第三个匹配符 c 与字符串的第四个字符 c 正相匹配。匹配结束。
如果添加 +标志,则原来的贪婪模式将变成独占模式。也就是说,它将匹配尽可能多的字符,但不会回溯。
因此,如果你想将这个问题完全解决。你必须保证表达式能正确的行使它的功能,同时确保没有回溯发生。我在上述验证 URL 的正则表达式的第二部分增添了一个加号:
Java
1 2 3 |
^([hH][tT]{2}[pP]:\/\/|[hH][tT]{2}[pP][sS]:\/\/) (([A-Za-z0-9-~]+).)++ --->>> (added + here)(“+”添加在这里) ([A-Za-z0-9-~_%\\\/])+$ |
现在,程序运行没有问题了。
最后,我推荐一个网站。它可以检查你写的正则表达式以及相应的匹配字符串是否存在问题。
例如,本文中存在问题的 URL 在使用上述网站检测后,会弹出如下提示:灾难性的回溯。
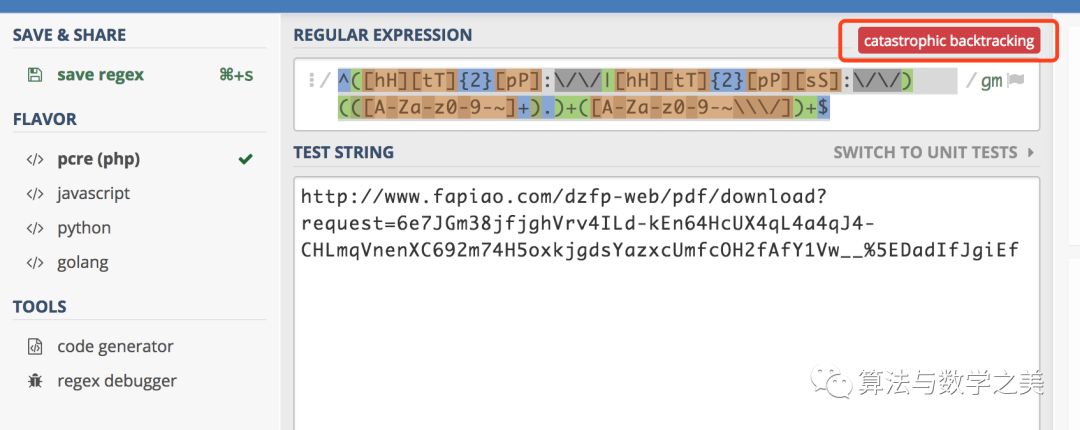
当你单击左下角的 “regex debugger” 时,它将告诉你已经进行了多少步匹配,列出所有的匹配步骤,并指出发生回溯的地方。
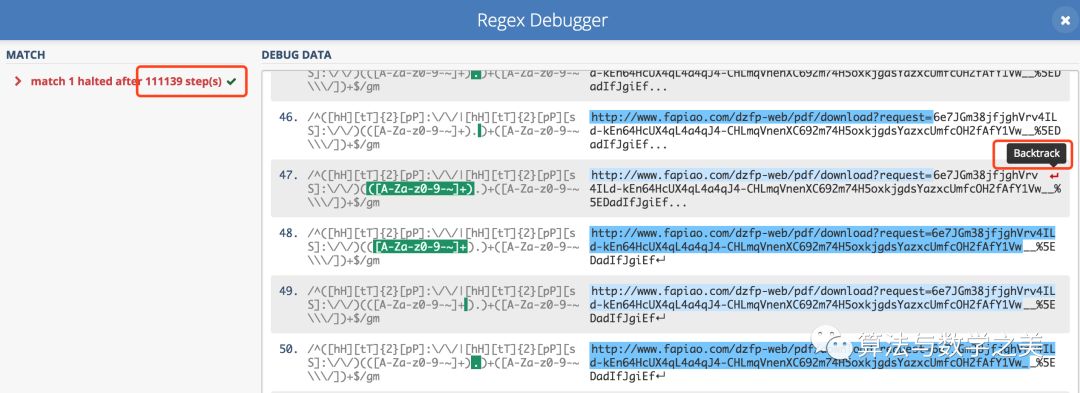
本文中的正则表达式在 110,000 次尝试之后自动停止。这表明,正则表达式存在一定的问题并需要改进。
但是,当我用如下修改后的正则表达式测试时:
Java
1 |
^([hH][tT]{2}[pP]:\/\/|[hH][tT]{2}[pP][sS]:\/\/)(([A-Za-z0-9-~]+).)++([A-Za-z0-9-~\\\/])+$ |
网站提示,仅用了 58 步就完成了匹配。
一个字符的差异导致了巨大的性能差距。
一些补充
一个小小的正则表达式也能神奇的让 CPU 卡死。这给我们提了一个醒。当遇到正则表达式的时候,一定要注意“贪婪模式”以及回溯问题。
END
∑编辑 | Gemini
来源 | 伯乐在线
更多精彩:
☞
☞
☞
☞
☞
☞
☞
☞
☞
☞
☞
☞
☞
☞
稿件涉及数学、物理、算法、计算机、编程等相关领域,经采用我们将奉上稿酬。
投稿邮箱:math_alg@163.com
以上是关于正则表达式的隐藏陷阱,你都了解么?的主要内容,如果未能解决你的问题,请参考以下文章