正则表达式很难吗?其实也就那样!
Posted Python进击者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式很难吗?其实也就那样!相关的知识,希望对你有一定的参考价值。
 / 写在前面的话 /
/ 写在前面的话 /
Hello,元宵节过了,这个年也算是过完了,接下来就得看我们2019年的奋斗了,2019年JAP君会一直陪着大家一起学习!今天我们来学习一下号称最难学的正则表达式,正则表达式在我们写爬虫的时候确实是一个很好的帮手,因为有一些网站的数据可能并不是那么的规整或者数据太多,我们只需要部分数据的时候,此时我们就可以通过一些表达式来进行提取,正则表达式就是其中一种进行数据筛选的表达式。
/ 正则表达式之“原子” /
常见的原子类型有哪些?
1.普通字符作原子
2.非打印字符作原子
3.通用字符作为原子
4.原子表
1.普通字符作原子:
普通字符是编写正则表达式时最常见的原子了,包括所有的大写和小写字母字符、所有数字等。例如,a—z、A—Z、0—9。
说明:search函数是re模块里面的,第一个参数就是原子,第二个参数是需要解析的字符串。
s = "JAVAandPython"
# 普通字符作为原子
pattern = "and"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(4, 7), match='and'>说明:re.research返回的是一个match对象
2.非打印字符作为原子:
非打印字符,是一些在字符串中的格式控制符号,例如空格、回车及制表符号等。例如下表所示列出了正则表达式中常用的非打印字符及其含义。
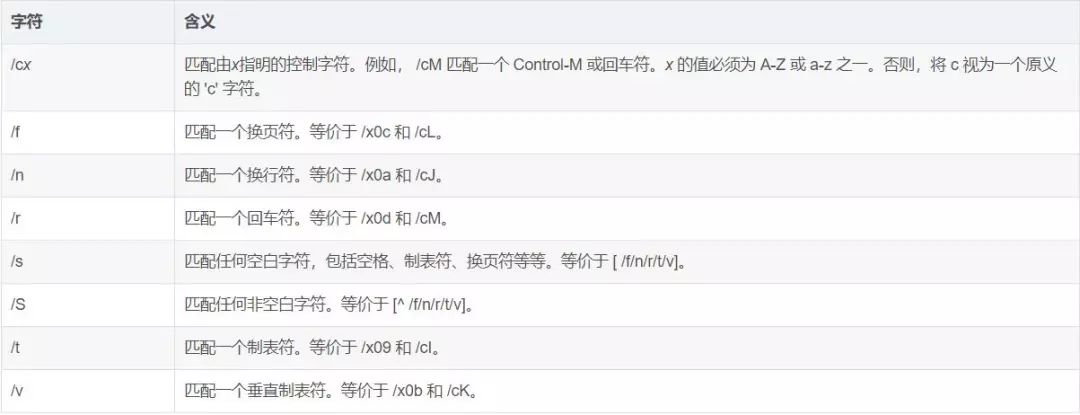
# 非打印字符作为原子
s = '''JAVAand
Python
'''
pattern = "\n"
m = re.search(pattern, s)
print(m)说明:这里我们使用了三引号来进行换行书写,s中是存在一个\n的
输出结果:
<_sre.SRE_Match object; span=(7, 8), match='\n'>3.通用字符作为原子
上面我们说的普通字符和非打印字符都是一个原子匹配一个字符,而通用字符是匹配一类字符,例如我们匹配数字时,不是匹配一个而是匹配这一类。
下面我给大家列举出一些:
\w:包含字母,数字,下划线
\W:除了字母,数字,下划线之外的
\d:十进制的数字
\D:除十进制的数字
\s:空白字符
\S:除空白字符
# 通用字符作为原子
s = 'JAVAand666python'
pattern = "\d\d\d\w"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(7, 11), match='666p'>4.原子表:
使用原子表“[]”就可以定义一组彼此地位平等的原子,且从原子表中仅选择一个原子进行匹配。
# 原子表
s = 'JAVAand666python'
pattern = "and[1234567]"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(4, 8), match='and6'>其实质就是从[]中选取符合原字符串的元素来进行匹配。
/ 正则表达式之“元字符”/
what is 元字符?所谓的元字符就是正则表达式中一些含有特殊意义的字符,如下表:

是不是看了之后还是有点懵逼?接下来,我给大家用代码一一实现一下
1. “ . ” 除了换行符外的任意一个字符
# 元字符 . 除了换行外任意一个字符
s = 'JAVAand666python'
pattern = "JAVA."
m = re.search(pattern, s)
print(m)
pattern = "JAVA..."
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 5), match='JAVAa'>
<_sre.SRE_Match object; span=(0, 7), match='JAVAand'>2. ^ 匹配输入字符串的开始位置
s = 'JAVAand666python'
pattern = "^JAVA."
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 5), match='JAVAa'>3. $ 输入字符串的结束位置
s = 'JAVAand666python'
pattern = ".python$"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(9, 16), match='6python'>4. * 匹配前子表达式的任意次
+ 匹配前子表达式的1次或者多次
? 匹配前子表达式的0次或者1次
s = 'JAVAand666python'
pattern = "JAVA.*"
m = re.search(pattern, s)
print(m)
s = 'JAVAand666python'
pattern = "JAVA.+"
m = re.search(pattern, s)
print(m)
s = 'JAVAand666python'
pattern = "JAVA.?"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 16), match='JAVAand666python'>
<_sre.SRE_Match object; span=(0, 16), match='JAVAand666python'>
<_sre.SRE_Match object; span=(0, 5), match='JAVAa'>5.{n} 匹配前子表达式恰好出现n次
{n,} 匹配前子表达式至少出现n次
{n,m} 匹配前子表达式至少出现n次,至多出现m次
s = 'JAVAanddddddd666python'
pattern = "JAVAand{3}"
m = re.search(pattern, s)
print(m)
s = 'JAVAanddddddd666python'
pattern = "JAVAand{3,}"
m = re.search(pattern, s)
print(m)
s = 'JAVAanddddddd666python'
pattern = "JAVAand{3,5}"
m = re.search(pattern, s)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 9), match='JAVAanddd'>
<_sre.SRE_Match object; span=(0, 13), match='JAVAanddddddd'>
<_sre.SRE_Match object; span=(0, 11), match='JAVAanddddd'>OK,上面几个是比较常见的元字符。
/ 正则表达式之“模式修正符” /
虽然都说正则很难,其实基础上也不是特别难,只是大部分的东西需要死记硬背,接下来我们来扯一下模式修正符,这个非常简单,就几个简单的字母标点,但是也是需要我们记住的。
首先还是跟大家讲下模式修正符是个啥,它就是通过一些特定的符号去改正正则表达式的含义,从而达到一些特定的效果而且我没进行模式修正是不要去改变正则表达式的。
下表就是一些模式修正符:
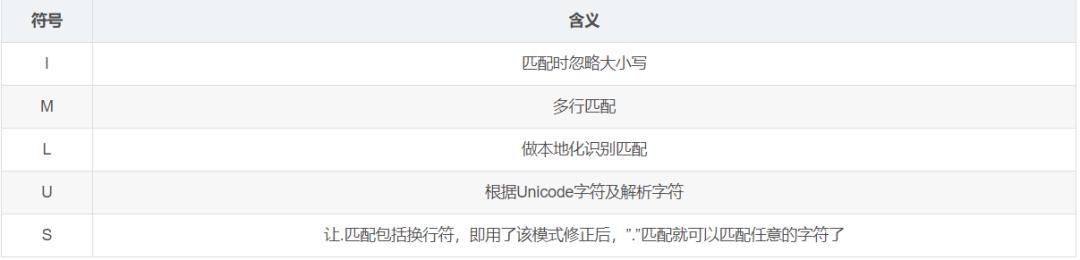
这里面比较重要的就是 I M S ,下面我就简单给大家用代码展示一个:
import re
s = "JAVAandPython666666"
pattern = 'java'
# 这里的第三个参数就是调用了我们的模式修正符,其他的也是一样的使用
m = re.search(pattern, s, re.I)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 4), match='JAVA'>从上面的代码和输出结果可以看出我们通过re.I 忽略掉了大小写。
再来看一个:
s = '''123java
asdasd
'''
pattern = '123.+'
# 这里的第三个参数就是调用了我们的模式修正符,其他的也是一样的使用
m = re.search(pattern, s, re.S)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 15), match='123java\nasdasd\n'>从结果中,我们可以看到它把\n也打印出来了。
/ 贪婪模式和懒惰模式 /
其实从字面意思上就可以看出,“贪婪模式”就是尽可能多的匹配,“懒惰模式”就是尽可能少的匹配。可能大家还是不知道这是个啥,还是直接上代码吧。
我们首先看一下贪婪模式:
s = '123JAVAandpypyPython'
pattern = '123.*py'
m = re.search(pattern, s, re.I)
print(m)我们来看看输出结果:
<_sre.SRE_Match object; span=(0, 16), match='123JAVAandpypyPy'>我们从代码和输出结果分析,可以看到它直到最后一个py才停止
我们再来看一下懒惰模式:
s = '123JAVAandpypyPython'
pattern = '123.*?py'
m = re.search(pattern, s, re.I)
print(m)输出结果:
<_sre.SRE_Match object; span=(0, 12), match='123JAVAandpy'>可以看到它匹配到第一个py时就停止了
总结:其实大家都可以发现,懒惰模式和贪婪模式就是一个问号的差别,贪婪模式是“.*”,懒惰模式是“.*?”。贪婪模式就是会一直“吃”到底,懒惰模式就是“吃”到第一个就不吃了,按照这样分析,可以发现贪婪模式所得到的结果是比较模糊的而懒惰模式得到的结果更加的精确。
/ 正则表达式的函数 /
接下来我们来看一下正则中的函数,这个是十分重要的。我就直接上代码。
import re
# 以下正则分成了两个小组,以小括号为单位
s = r'([a-z]+) ([a-z]+) ([a-z]+) ([a-z]+)'
# s.I表示忽略大小写
pattern = re.compile(s, re.I)
# match -从头开始匹配,但是search可以从任意处匹配
m = pattern.match("Hello World Kuls yes qweqwe")
# group(0)表示返回匹配成功的整个子串
s = m.group(0)
print(s)
# span(0)返回的是匹配成功的整个子串的跨度
a = m.span(0)
print(a)
# group(1)表示第一个匹配成功的子串
s = m.group(1)
print(s)
# span(1)表示第一个匹配成功的子串跨度
a = m.span(1)
print(a)
# groups()等价于group(1),group(2)
s = m.groups()
print(s)其实我在代码里面给大家讲解了每一个函数的作用,但是我还是把它扯出来吧,防止大家没看到。
match -从头开始匹配,但是search可以从任意处匹配
group(0)表示返回匹配成功的整个子串
span(0)返回的是匹配成功的整个子串的跨度
group(1)表示第一个匹配成功的子串
span(1)表示第一个匹配成功的子串跨度
groups()等价于group(1),group(2)
整个输出的结果也给大家看看:
Hello World Kuls yes
(0, 20)
Hello
(0, 5)
('Hello', 'World', 'Kuls', 'yes')另外还有两个比较重要的函数findall和finditer,两者相比,findall是最常用的。
import re
s = r'\d+'
# 全局匹配
pattern = re.compile(s)
m = pattern.findall("i am 18 years old and 185 high")
print(m)
# finditer
m = pattern.finditer("i am 18 years old and 185 high")
for i in m:
print(i.group())输出结果:
['18', '185']
18
185可以看到findall返回的是一个list列表
/ 一些常用的正则实例 /
这里给大家准备了一些经常用的正则实例,大家可以收藏收藏。
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
身份证号(15位、18位数字):^\d{15}|\d{18}$
中文字符的正则表达式:[\u4e00-\u9fa5]
• end •
关注我,你能变得更牛逼!
以上是关于正则表达式很难吗?其实也就那样!的主要内容,如果未能解决你的问题,请参考以下文章