文本函数和正则表达式, 文本分析事无巨细
Posted 计量经济圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本函数和正则表达式, 文本分析事无巨细相关的知识,希望对你有一定的参考价值。
凡是搞计量经济的,都关注这个号了
邮箱:econometrics666@sina.cn
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.

下面主要引荐主要的文本函数和正则表达式,用来分析和处理文本文件,而这也成为社科研究中的新趋势。欢迎到社群交流文本分析在实证研究中的应用。
文本缩写到n位

文本的单数(1)和复数(2)

若n不为正负1,那文本2会替换或改变文本1的单复数形式

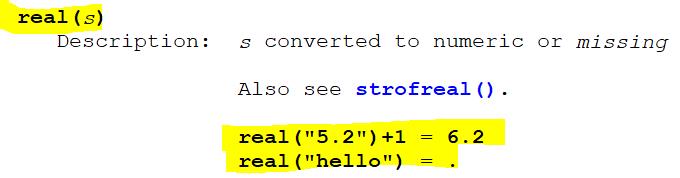
文本转换数字
Regular表达式





https://www.stata.com/support/faqs/data-management/regular-expressions/
http://soc596.blogspot.com/
正则表达式re是否出现在文本中(0-1)

用文本2替换出现在文本1中的第一个正则表达式re

用文本2替换出现在文本1中的所有正则表达式re

计数子文本重复出现次数

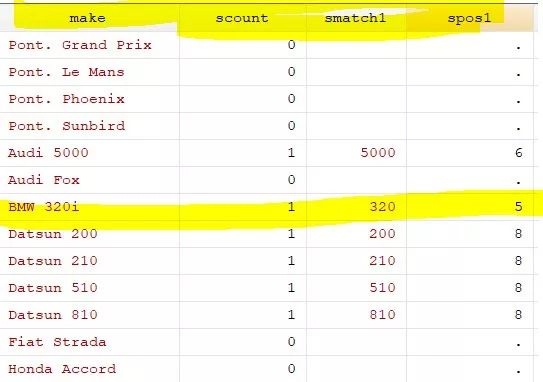
moss make, match("([0-9]+)") regex prefix(s)
文本合并
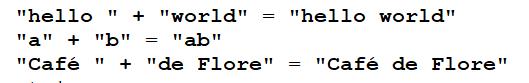
文本乘积

文本转数字
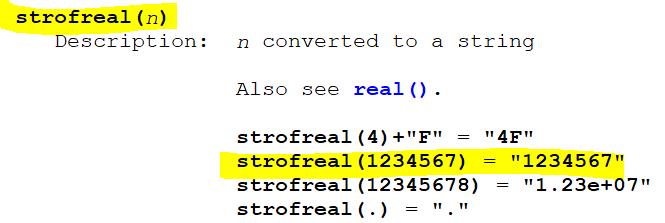
文本转数字,按照一定格式
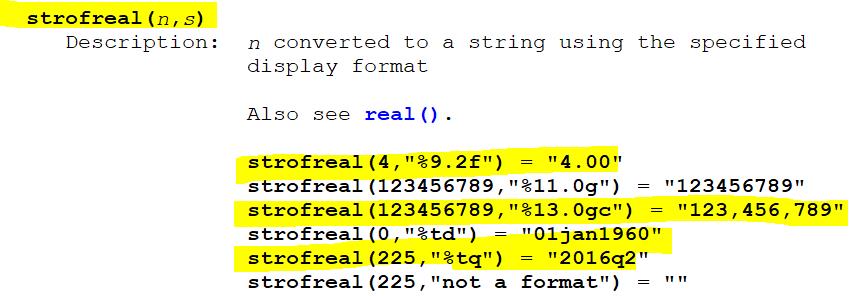
空格缩短成1个

文本的长度ASCII

三者差别:ASCII,Unicode

大写改小写

把文本首的空白符去除

两个文本模式匹配

文本2在文本1中首次出现的地方

与上一样,但从文本1的第n位开始

让文本更恰当,首字母是ASCII

首字母大写, 其他小写

把文本反过来

文本2在文本1中最后出现的位置

把白字符和空格去除掉

把文本改造成可以作变量名的

去掉文本前后的空格

全部大写文本

用文本3替换掉出现在文本1中的文本2部分
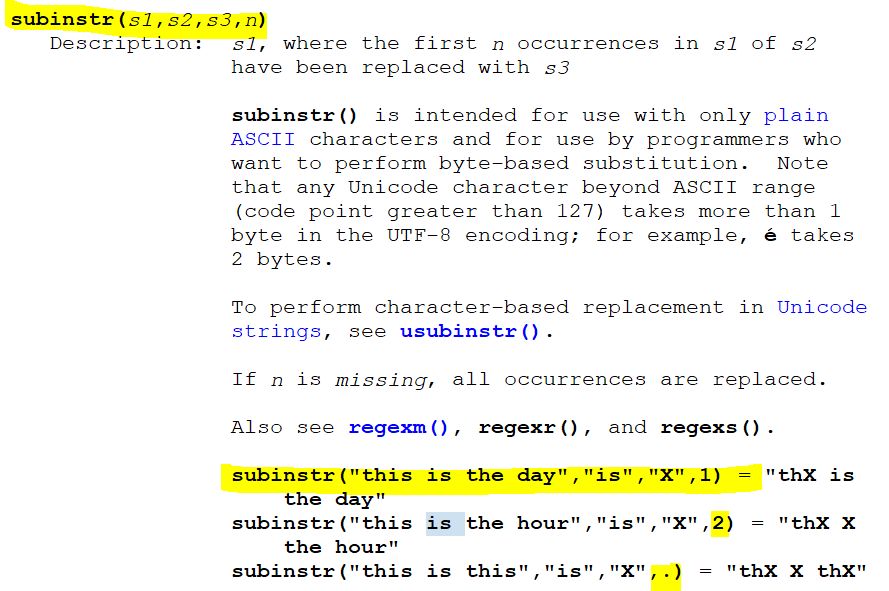
用文本3替换掉出现在文本1中的文本2部分,条件是文本2作为单独的文字

从n1开始截取n2长度的文本
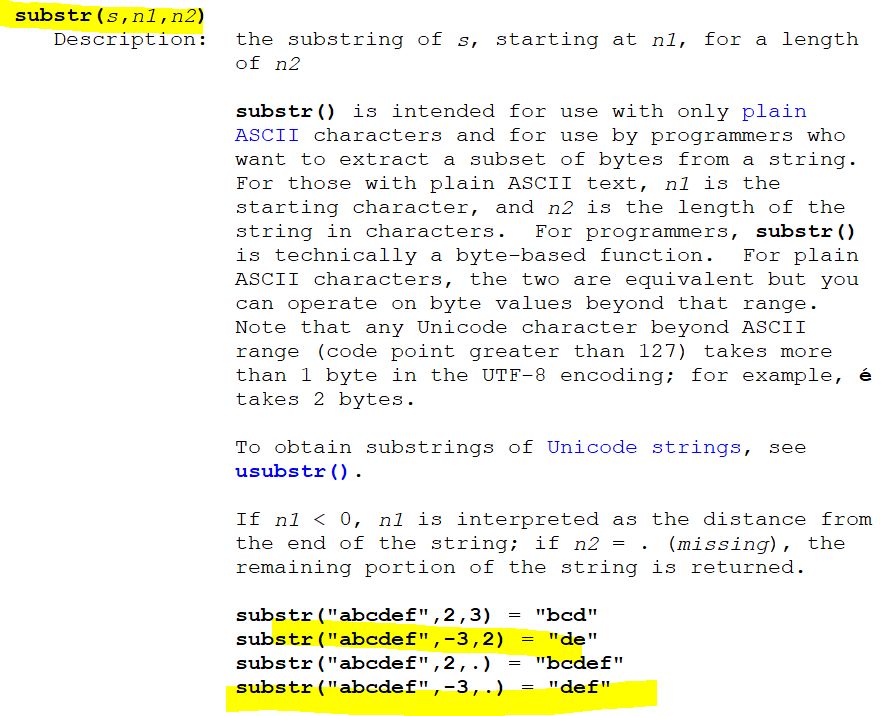

比较两个Unicode文本大小

文本的前n位

文本后n位

文本中的第n个字

文本中多少个字

以上部分由计量经济圈整理和编辑。

下面这些常用正则表达式,也可以看看:
https://blog.csdn.net/wangjia55/article/details/7877915
正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些常用的表达式收集于此,以备不时之需。
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
匹配html标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]\d{5}(?!\d)
评注:中国邮政编码为6位数字
匹配身份证:\d{15}|\d{18}
评注:中国的身份证为15位或18位
匹配特定数字:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
欢迎到计量社群交流探讨文本分析相关研究。
推荐阅读:
1.工企
2.
3.
4.
5.
6.
5.
可以到计量经济圈社群进一步访问交流各种学术问题,这年头,我们不能强调一个人的英雄主义,需要多多汲取他人的经验教训来让自己少走弯路。
以上是关于文本函数和正则表达式, 文本分析事无巨细的主要内容,如果未能解决你的问题,请参考以下文章