技术秀Solr搜索引擎及应用: information retrieval
Posted BitTiger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术秀Solr搜索引擎及应用: information retrieval相关的知识,希望对你有一定的参考价值。
Solr是Apache Lucene项目下的一个开源的企业搜索平台。其主要功能包括全文搜索,命中标示,分面搜索,实时索引,动态聚类,数据库集成,NoSQL,以及富文档(如Word,PDF)处理。由于提供了分布式搜索和索引复制,Solr的可扩展性和容错能力都很强。强大的开源社区更是让Solr在诞生十年的历史中快速演进。包括Houzz, Pinterest在内的许多公司都使用solr作为搜索引擎。本次讲座主要结合Solr在Houzz的应用向大家展示Solr的各方面特性。
Houzz,互联网家装平台,兼具网上市场和社交网站的功能,通过连接业主,家装设计师和施工方,提升室内家装效率,用户可以在平台上直接与设计师沟通,联系平台上的施工方,此外,用户还能在平台上分享家装经验和装修后的图片。
https://en.wikipedia.org/wiki/Houzz
如果我想装修一个厨房,并进入houzz主页,在PHOTO的导航栏点击Kitchen的链接,这时候的行为并不是传统意义上的搜索:类似在google搜索框type一个 关键词,然后点击合适的链接。这里我们只点击了链接,并没有type关键词进去。但是从技术上的角度来说、可以理解,这些结果依然是从search的结果 来的。只不过没有关键词,但是有其他的约束条件(这里是kitchen)。
用户需求有两种 一种是浏览,一是搜索。在这里看,浏览就是定向的搜索。当你点击了目录的时候,就相当于把user intent(用户意图)告诉你,那么你基于这个目的呈现的内容其实也是一种搜索。
点开其中一个连接,我们会发现旁边有一个recommander,这里用的是releated search,这也是某种意义上的搜索,是根据通过相关性进行的推荐。当你在回到首页时,主页上的推荐也会有针对你感兴趣的推荐,这里的推荐个性化的约束条件的search。
IR的定义是,各种信息加以整理,存储,并能进行搜索。
在应用的领域,在五十年代之后,主要倾向于text和document的搜索。
这里的document和text有一定区别,document是有一定结构的text,比如说网页,有标题,有表格,有url,但是在在主要的部分正文部分有一大段文字(free text)。
然而文档的搜索比传统的batabase搜索要困难一些,因为database是非常具体的结构化。database上做的query是对每一个column做一定的限制条件。所以文档的retrieval要困难一些。
IR并不只局限于web search ,但是search仍然是IR的核心。
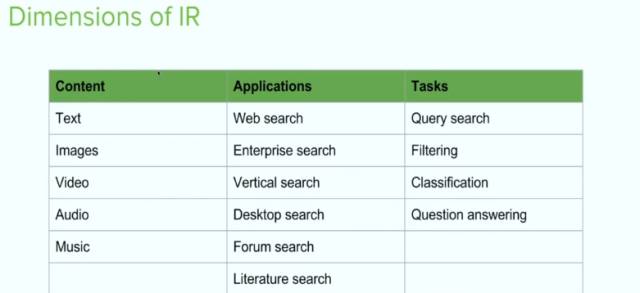
在内容上:text,image,video,audio,music。
在应用上:web search,enterprise search,等
具体到task上的问题:query search,filtering,classification,question answering
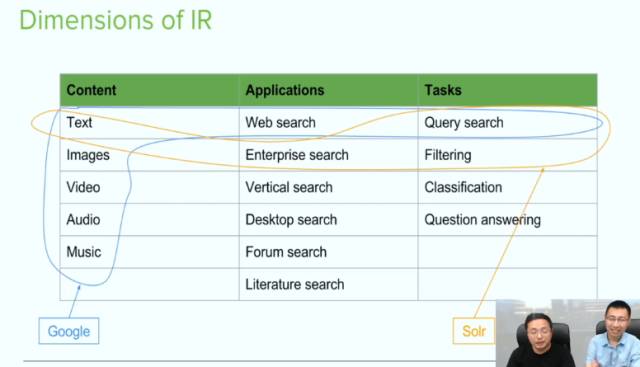
简单来说google的服务主要集中在蓝线的领域,解决web search的问题。那有人就会问了:我在google上搜索obama的生日,google可以给你一个简单明确的回答,这不是question answering吗?
其实question answering不是google的主业,但是google发现 :很多query深入理解其实是用户问的一个问题 ,而提出的问题中很问题可以通过一个short answer回答 ,这个short answer 其实是对query search 结果做一个整合。
再比如,google搜索CA985,google会加些个性化的搜索,通过对你的email做一些整合,以及其他途径。你会得到航班的信息:是否预订航班,航班是否延期。
接下来的就是我们的主角solr了,solr的搜索主要集中在黄线画出的领域。细心的同学可能会发现,solr并没有photo和video的能力。而且 solr也不是一个web search 。因为solr本身没有网页的爬虫。但是由于solr的开源性质,你可以在solr上添加一些模块来扩展功能。
Searching engine architecture
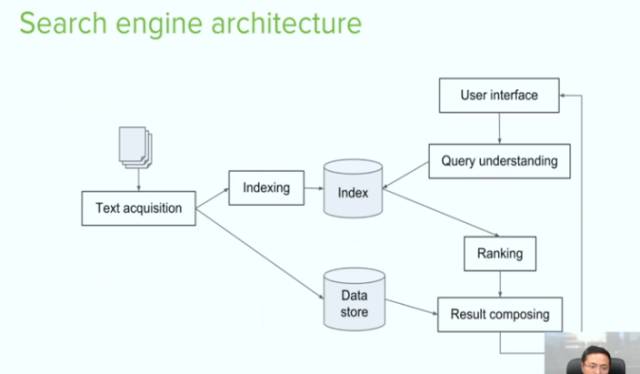
这是一个极为简化的搜索引擎结构图。以index--data store为轴,左边的部分为offline 索引的部分 ,右边是online retrieval,ranking的部分
如果你有一个文档,那么通过 text acquisition 把这些文档爬过来,存储在index里,存储的过程叫indexing,indexing做的是倒排表的工作:把这个文档按照词拆开(而是按照“词”。词的定义在英语等大多数语言中就是空格分割的单词,而在中日韩泰等语言中则需要“句读”,也就是“分词”来确定。),把每个词进行正则 化之后,把词作为关键词 ,做一个倒的排表。这就类似于字典后面的索引。通俗的理解就是拿词在表里匹配。
除了把文档拆开,还要把文档原样存储下来,用于文档重构。
用户通过user interface进来,以谷歌为例:搜索框type关键词。进入query understanding模块进行对关键词的理解 , 这一部分做得非常丰富 :同义词匹配,进行stemming(单复数,时态,如果只剩词干 可以match的更好)。
第一步, 把经过标注和理解的关键词进入index倒排表去,找到需要的所有文档。
第二步, 对文档进行ranking,然后把ranking之后的结果呈现出来。
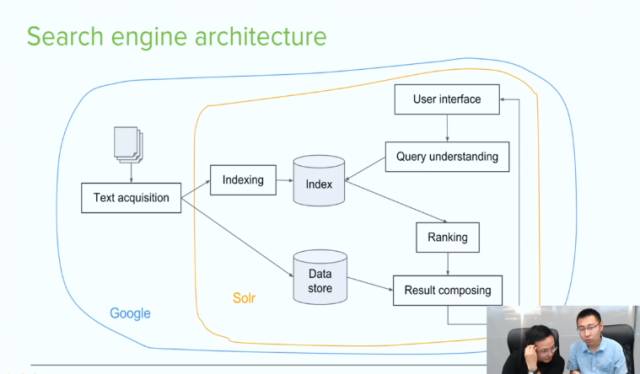
以上是google和solr在搜索引擎架构上的区别。上文提到,solr没有爬虫的功能,所以没有text acqusition。
solr本身具有data store的功能,可以解决数据储存问题。 你可以把任何你想要的东西,以一种神奇的形式index 到solr里,然后通过一个web interface呈现出来 。solr相比于mysql,也有更好的数据接口,更高性能的访问。
很多人对google的搜索感到很神奇,我们可以把google搜索的黑盒子简单的拆成两步~
Step one :retrieval round : binary retrieval ,用关键字到google的所有文档列表去找 ,分出想要的和不想要的文档 (是否 match),把文档集合一分为二。
Step two: scoring round : 计算document的价值,然后按评值呈现出来。因为scoring是一件比较昂贵的事情,在一个比较小的子集会比较好。
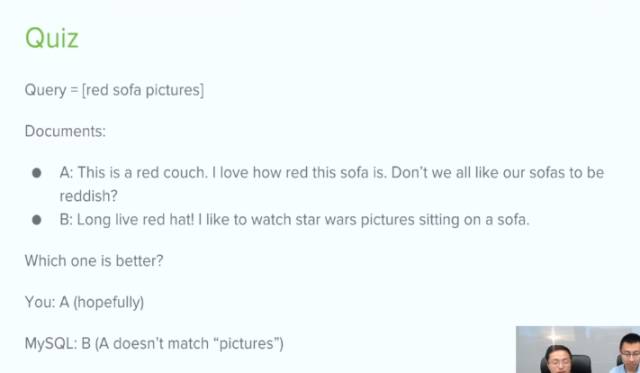
现在有一个query [red sofa picture] , 我想搜索红色沙发的照片。还有两个文档,document A,Document B。那么哪一个文档能更好的match query呢?
如果你能读懂这两个文档,以人类的理解是 A 更符合我们的user intern。但是对于 计算机来说 B match 的更好,因为在B中 red .sofa.picture这三个词都匹配到了。所以 我们要设计算法,来提高计算机的搜索能力。
在这个query中,我们可以人为的理解sofa是topic,red是description ,picture是intern 。所以topic一定要选对,其次是description。并且 intent几乎是没有用的。stopwords, generic words, specific words: 三种词重要性依次递增。
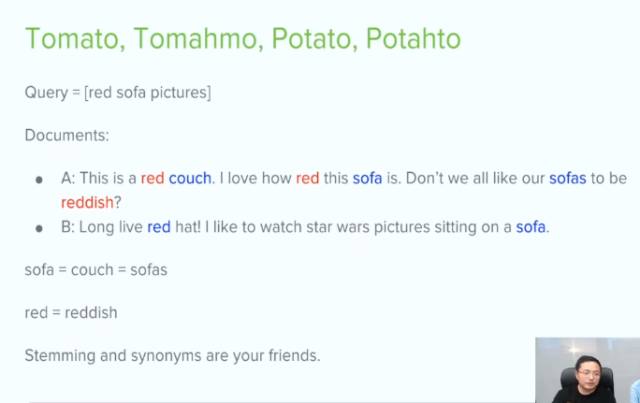
在 Document A 中,red和reddish其实是一个意思,sofa和couch是一个词的两种不同表达方式。
我们还可以发现,在Document A 中red和sofa比较近,而Document B中的距离相对较远远。对于我们的query来说,关键词越近越好 。这里就可以在scoring上进行一定的奖励。
重要的事情我一般不说,说的话就说三遍。。。。。其实我还可能说十遍。。。。。
我们在文章中可以发现,如果作者很想强调一件事情,他会不停地说,说的次数very多的时候,可能会very重要,但是说的次数very very多的时候,可能没有very very那么重要了。十遍比三遍说了三点三倍,但是重要性没有三点三倍。
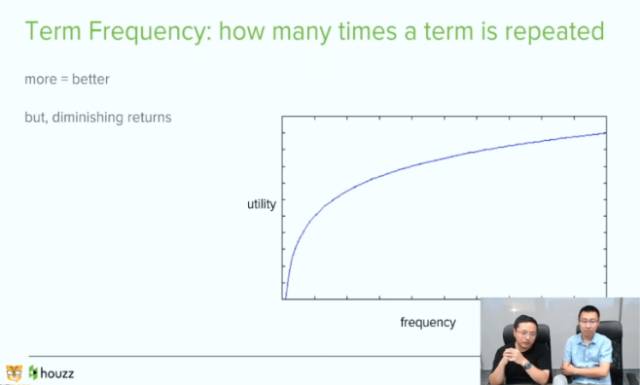
在这件事我们也有数学方法上的衡量。对于搜索引擎关键词命中的次数越多越好,但是命中的次数特别多,函数就会趋于饱和。
模型:边际效应曲线。一开始增长的比较快,但是随着关键词命中的数量增长,曲线增长的就比较缓慢了
小编:这件事情其实叫keyword stuffing: 在网页中大量堆砌关键词,希望提高关键词密度,提高网页针对关键词的相关度。在seo层面是有效的,但是搜索引擎会发现你的恶意填充关键词。。。。甚至影响排名。。。。。所以下次我不会堆那么多了。。。。
可能你觉得没用的关键词其实是有用的,比如stopwords,generic words,specufi words.
还有可能你很难抓取关键词:mis-spelled words,foregn words , different corpus.
现在给出一个query [walmart employee salary] 我想知道沃尔玛雇员的薪资
经过我们的观察Document B 能直接回答我们的问题。但是从数学以及我们上述的角度观察应该是第一个好。 在 A中 ,walmart说了很多遍 ,加分。关键词离得也比较近,加分。那怎样设计scoring来让Document B的评值更高呢?
所以引入一些新的东西 : term balance , 在document中的每个关键词相对于query出现次数差不多最好。
恭喜 现在你已经学完了 IR ,接下来就是对上述的总结~
1 :spelling :correct输入的错词,这项工作不是用一个字典可以解决, 每个国家每年都有都会产生大量的新词 。所以我们在不断的训练过程 把新的语料吸收进来。 就需要增加新的训练集,淘汰旧的训练集。
2 :我们要搜索的内容,最好的搜索结果不一定在文字上呈现。 可能是一本书, 也可能是一个youtube视频。我们可以让搜索引擎垂直的理解了在语料库里最好的内容 。并且水平的交叉进来。
3 :数据量非常大的时候 ,到谷歌那个层次,就需要做多层的ranking来更好的理解query
以上是关于技术秀Solr搜索引擎及应用: information retrieval的主要内容,如果未能解决你的问题,请参考以下文章
Solr&ElasticSearch原理及应用讨论
Solr简述及应用
全文搜索技术——Solr
全文搜索引擎技术详解之Apache Solr的使用
全文搜索引擎技术详解之Apache Solr的使用
Solr搜索引擎