《solr in action》-13-solr的分布式与集群
Posted 金沙数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《solr in action》-13-solr的分布式与集群相关的知识,希望对你有一定的参考价值。
在前面的几次分享中,说了solr的很多优点。查询速度快,使用相关性打分,可以对文本进行搜索等等。今天介绍另一个强大的特性--大规模搜索。solr通过线性添加server的方式可以处理千亿级别的文档索引和无限数量的查询请求。本节只阐述为什么我们需要大规模的搜索引擎,更深度的内容在《solr in action》这本书的12章有详细讲述。阅读本文需要4分钟。
本节讨论内容
非结构化数据在solr中的存储方式
solr的分布式
solr的集群
非结构化数据
solr中所有的文档都是非结构化的,这是与关系型数据库最大的区别。
下面是一个关系型数据库和solr是如何存储一个文档的例子。
用例:用户简历的存储
如果用mysql存储,数据库的结构设计可能如下
但在solr中,我们是这么定义存储结构的

我们注意到在关系型数据库的设计准则中,我们要求要减少冗余,减少数据依赖。但solr却恰恰相反,在solr的存储结构中,公司的信息是重复的。
在传统的关系型数据库中,一个查询操作可以通过多个表的join操作来进行组合,尽管solr也支持join操作,但非结构化的数据显然有点难为solr。solr知道一个term和一个document的关系,但是不知道两个document之间的关系。比如要想查找在洛阳的公司工作的人的简历,只有全部的人都工作在魏集团,才能够满足高的召回率。
这种非结构话的数据模式有很多的限制,但是也有很多的好处,最直接的好处就是线性扩容。
solr的分布式介绍
假设每个文档都是完整的,封闭的,与其他文件之间没有任何关系,那么我们就可以把这些文档分开放到不同的server上,也就是说,我们的文档可以经过如下变化
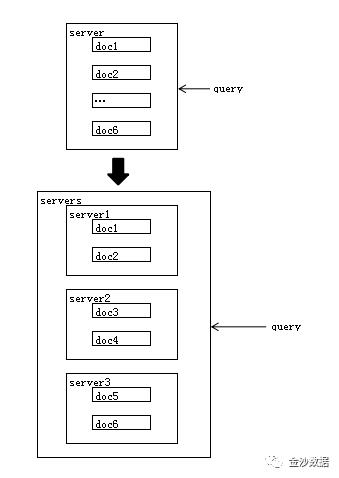
如图,本来我们是用一台server处理6个文档,现在将6个文档分成3份在3个不同的server上并行处理查询请求,解决了大规模的搜索问题的方式就叫做solr的分布式部署方式。
我常常在想,为什么不能用一个server来处理查询请求呢,还要那么麻烦的分开,查找完还得做聚合。我们知道在面对高并发的请求,高的吞吐量的时候,一个server的能力是有上限的,CPU,硬盘,内存都会成为瓶颈,而把数据分开处理,处理完再聚合,秦始皇统一六国就是用的这个策略。
把solr的索引切分成多个部分,每一个部分有都是独立的个体,部署在不同的server上,每次查询请求的时候,请求会发送给所有的server,每个server查询出来的结果,处理组合后,在返回给solr搜索引擎。每一个solr索引(也可以理解为一个solr core)都可以通过一个唯一url来访问。我们将索引切开部署到不同的server上之后,这些solr core可以通过下面的url方式来进行聚合。
NB:
1)shards 这个参数用于指定solr core的位置,一个shard是索引的一部分,因此shards这个参数告诉solr,"Hey,把后面那些core中查询出来的结果给我组合到一起,排个序Bala Bala"
3)这种分布式的搜索需要多个server
4)solr的core不需要分布在不同的server上。同一台server上可以有多个core。比如box2:8983/solr/core2;box2:8983/solr/core3。
因为solr可以使用分片技术,这些分片又可以并行计算,所以solr的分布式搜索是接近于线性的。就是说,理论上,有一个server的时候,处理一个query需要1s,那么分成2个server处理,仅需要0.5秒,分成4片处理,0.25秒就搞定了。但现实还是略微残酷,近线性就是离线性还差那么一点点。这个也很好理解,分片查询之后的聚合也需要时间啊,分的片越多,聚合的时间应该越长。基于此有一个经验公式

使用这个公式可以大致评估在搭建搜索引擎时需要多少个分片。
solr的集群介绍
使用分布式部署的方式解决了大规模数据集的问题,当查询请求增加时,可以使用添加server的方式,平衡响应时间。思想上这是一个质的飞跃,完成了从server 转向servers这种大规模集群策略的转变。
接着上文的分布式部署的例子,按照如下url的方式进行分片部署
http://box1:8983/solr/core1/select?q=*:*&shards=box1:8983/solr/core1;box2:8983/solr/core2
core1在box1上,core2在box2上。如果这个时候box2宕机或者其他原因无法连接,我们访问这个URL时,将会是什么结果呢。

因为这些server是相互依赖的,如果其中一个挂掉,整个的搜索就会失败。当大家正为此事头疼不已的时候,有一个叫做集群的家伙粉墨登场了。
他提出了一个概念,我们可以把每个shard做个备份,这样当其中一个shard挂掉了,就可以使用另外的替补shard。solr集群的概念应运而生。但是多个备份又该如何管理?两个相同的shard存在于servers中的时候,查出来两份一模一样的数据怎么办?
在Apache 家族有一个非常优秀的管理员,叫做zookeeper。solr4以后的版本集成了zookeeper,作为solr的使用者,只需设计好索引的分片,备份其他的都交给zookeeper来管理就好了。这个在《solr in action 》这本书的12章有详细讲解。
今天的内容就这么多了,有没有意犹未尽的感觉呢,如果有就去看看solr in action这本书吧。这本书后面还有一部分内容实说solr的一些缺点的,有兴趣的同学可以找来读一读,不要被他的英文吓到了,Be confident。
预告:solr的配置文件,solrconfig.xml
后记:笔者特别喜欢三国演义开篇的那句话,天下大事,分久必合,合久必分。这句话用来解释solr的shard简直不要特别好。分治策略在很多设计上都有体现,在这里把这句话送给大家。
笔芯
《solr in action》
P74-78
长按二维码
以上是关于《solr in action》-13-solr的分布式与集群的主要内容,如果未能解决你的问题,请参考以下文章