金沙数据-《艳遇SOLR(solr in action)》--2 千呼万唤始出来 犹抱琵琶半遮面
Posted 金沙数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了金沙数据-《艳遇SOLR(solr in action)》--2 千呼万唤始出来 犹抱琵琶半遮面相关的知识,希望对你有一定的参考价值。
solr不是什么
solr不是Google或者必应或者百度这样子的web 搜索引擎
solr对网站的SEO没有任何帮助
solr能做什么
想象我们现在要设计一个房地产网站,便于一些潜在的买房者/租房者找到合适的房子(牢记这个案例,在今后的事例中会不止一次的使用)。我们以这张图为例,说一说solr能做什么。
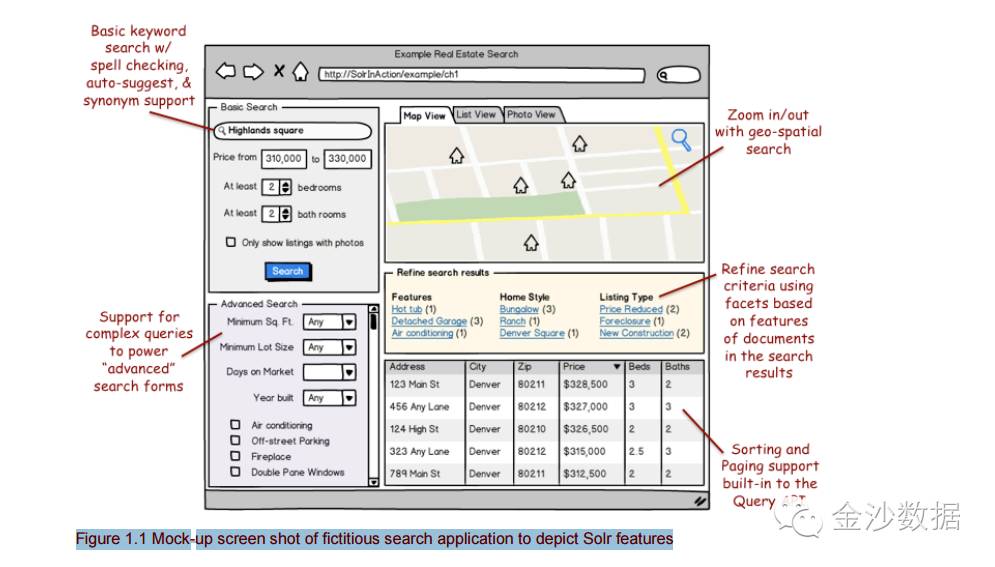
左上角区域是一个简单的搜索框。可以在里面输入关键词进行检索。同时这个搜索框支持拼写检查,拼写建议,同义词转化,拼音搜索(中文还是满需要的)。
右上角区域地图检索。这个使用场景比较多。比如我们走在马路上需要一个自动取款机时,打开手机的地图功能,手机自动定位后,搜索1km以内的自动取款机,还可以按照距离进行排序。
左下角区域是一个复杂查询选项。增加限制条件,缩小查询范围。
右侧中间区域,也是solr最棒的特性。facet:多维度切面搜索。作用:允许用户在搜索结果的基础上,再次进行过滤。
右下角就是查询的结果集了。支持排序,分页功能。
一、solr是一个信息检索引擎
信息检索(Information Retrieval)是指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术。
这种一定的方式就是搜索引擎中最重要的概念-倒排索引(想当年笔者找工作时靠着这个概念忽悠了无数的面试官)。风雨大神在《大话搜索引擎》系列第二篇有讲过倒排索引,我在后面也会拿出一篇文章单独聊聊它。
Google的web搜索也是以倒排索引为基础的,事实上也正是需要去建立一个全网倒排索引(web-scale inverted index)才导致了MapReduce的发明(上文中房产搜索例子,风雨的《大话搜索引擎》中的餐饮搜索都叫做垂直搜索,相比较Google,百度这类搜索叫做全网搜索)。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,概念"Map(映射)"和"Reduce(归约)",是它们的主要思想。Google使用MapReduce给它的巨大的web搜索创建索引,进行查询。
Apache Hadoop 提供了MapReduce的一个开源实现,Apache nutch 使用它去建立lucene的倒排索引为使用solr去做全网检索。
二、自由的schema管理
solr提供了一个xml配置文件(schema.xml),通过这个文件去灵活的配置索引的结构(solr6中managed-schema这个文件)。solr预配置了schema.xml文件,其中还有两个很好用的功能,Copy fields和Dynamic fields。
三,solr是一个Java Web 应用
solr是一个Javaweb应用,可以运行在任何Java servlet(Jetty,Tomcat,JBoos等)引擎上。笔者的公司当年是运行在weblogic上的。
这张图很清晰的表现了solr的工作流程。一定要仔细看(很好看)。手机上看不清的,下载solr in action 这本书来看。
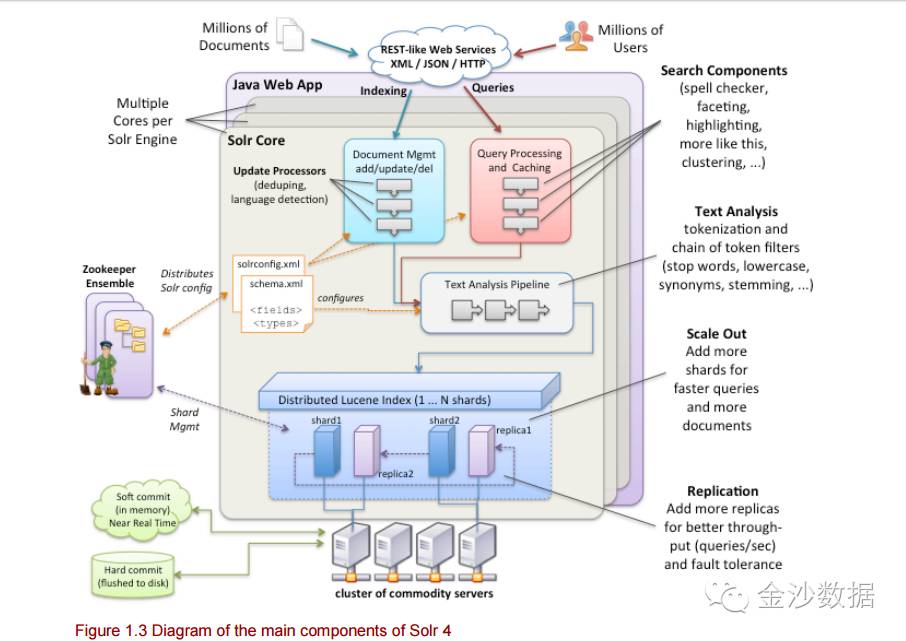
四、一个server上可以有多个core
在一个solr的服务上可以创建多份索引。有了这个功能,就可以实现数据分离。比如一个core做最近的文档索引,一个core做旧的文档索引。又或者,在上文中提到的房地产网站,可以进行房屋买卖,也可以进行土地买卖。房屋和土地是不同的两种东西,拥有不同的属性,创建索引库的时候就可以分开创建(笔者之前是使用solr3.6多core功能生成不同省份的车牌号码索引,保险公司的车险业务需要进行车牌号码的查询。这个功能数据库也可以完成的,引入solr终归是政治目的更多一些)。
五、solr的功能上的扩展
在本文的第二张图,书中对应的图1.3中,solr包含有三个子系统,文档管理系统(document management),查询系统(query processing),文本分析系统(text analysis)。每一个子系统中,都可以添加自己的插件,进行扩展,以满足在使用中不同的需求。
六、solr性能上的扩展
solr在查询速度上继承了lucene的所有优点。但是单个的solr无论有多快,也无法摆脱CPU和磁盘I/O是有限制。所以solr预先配置了一个cache.单机上cache的能力仍是有限的。这个时候使用增加server的方式来进行性能上的扩展。
solr从两维度来做扩容--query throughput 和the number of documents index.
query throughput--搜索引擎能支撑的每秒钟的查询数量。这个显示了单个server能处理的事实请求的数量。solr使用添加replication的方式来处理更多的请求。比如说,一个搜索引擎有3个server,理论上可以处理一个server的3倍请求,事实上会差一些,2.5倍左右。
the number of documents indexed.创建索引的时候,如果一个solr的实例,存的太多,查的时候也会比较慢,索引进行分片(shard)处理.把同一份数据分成多份,每份加起来组成一份完成的数据。
七、自动容灾
solr4版本之后增加了SolrCloud。
SolrCloud的特性:
配置文件集中zk管理
解决了单点故障
自动容灾
自动分配流量
八、solr 你值得拥有
for 架构师:solr 稳定(由社区和组织一大波人在维护),可扩展,高度容错(SolrCloud)
for 系统管理员:平台无关,容易部署,自带管理界面,使用一些监控工具,比如Nagios
for CEO:向下兼容,快速获取原形,有社区支持,使用成本低
for everybody:信息世界,我们都需要懂一点搜索常识,了解搜索引擎的运行原理,可以让我们在信息的海洋中,快速有效的获取我们想要的信息。这个推荐看一下《社会工程,安全体系中的人性漏洞》里面有一个章节专门将如何使用搜索引擎准确获取我们需要的信息的。
预告:下一篇中,将对solr4 ,5, 6 三个大版本的更新做一个说明
写在后面:探索未知的事物需要很多的勇气,既要克服来自于内心的恐惧,又要抵得住周遭世界的诱惑与不解。然而在这里我还是希望大家亲自去看一看原版的英文书。每一个翻译的版本都加入了太多翻译者的主观因素,同时也受限于译者的能力,无法达到作者的层次。我们要学会去获得第一手资料,并在第一手资料中去解读。但愿大家在读完这篇文章之后,能莞尔一笑,拿起solr in action 这本书的对应章节,去感受一下原作者的大气磅礴。
--------------------------------------------------------------------------------------------------------
我们不是砖家,我们只是久战沙场能时刻听得见枪声的一名名互联网老兵。
我们亦不是叫兽,我们只是趟坑无数,踩雷亦无数的互联网技术的工业践行者。
我们谦逊而有激情!我们积极并乐于分享!
我们愿拿自己微不足道的数年积累为您在踏入互联网技术的道路上点燃点点星光。
人海茫茫,遇见即是前世修来的缘分,而我们和你又智趣相投,更奈人生幸事。
我们关注大数据、搜索、推荐、广告、数据挖掘、机器学习、数据仓库技术如何产生商业价值;
我们聚焦探索相关的前沿技术hadoop,spark,hive,lucene,solr,elasticsearch,mahout,sqoop等等。
欢迎大家加入官方社区微信群:
以上是关于金沙数据-《艳遇SOLR(solr in action)》--2 千呼万唤始出来 犹抱琵琶半遮面的主要内容,如果未能解决你的问题,请参考以下文章