solrcloud Recovery原理及无法选举分片leader
Posted 程序源
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了solrcloud Recovery原理及无法选举分片leader相关的知识,希望对你有一定的参考价值。
来源: 将将将博客
https://my.oschina.net/u/172871/blog/709631
摘要: solrcloud Recovery原理及无法选举分片leader
我们在使用SolrCloud中会经常发现会有备份的shard出现状态Recoverying,这就表明SolrCloud的数据存在着不一致性,需要进行Recovery,这个时候的SolrCloud建索引是不会写入索引文件中的(每个shard接受到update后写入自己的ulog中)。
1、solrcloud Recovery原理
1.1、Recovery原因
SolrCloud启动的时候,主要由于在建索引的时候发生意外关闭,导致一些replicat的数据与leader不一致,那么在启动的时候刚起的replicat就会从leader那里同步数据。
SolrCloud在进行leader选举中出现错误,一般出现在leader宕机引起replicat进行选举成leader过程中。
SolrCloud在进行update时候,由于某种原因leader转发update至replicat没有成功,会迫使replicat进行recoverying进行数据同步。
1.2、Recovery原理
着重介绍第三种情况的recovery
在solrcloud接受写入的过程中,不管update请求发送到哪个shard 分片中,最后在solrcloud里面进行分发的顺序都是从Leader发往Replica。Leader接受到update请求后先将document放入自己的索引文件以及update写入ulog中,然后将update同时转发给各个Replica分片。这就流程在就是之前讲到的add的索引链过程。
在索引链的add过程完毕后,SolrCloud会再依次调用finish()函数用来接受每一个Replica的响应,检查Replica的update操作是否成功。如果一旦有一个Replica没有成功,就会向update失败的Replica发送RequestRecovering命令强迫该分片进行Recoverying。
Recovery分为Peer sync和Replication两种方式
Peer sync:如果中断的时间较短,recovering node只是丢失少量update请求,那么它可以从leader的update log中获取。这个临界值是100个update请求,如果大于100,就会从leader进行完整的索引快照恢复。
Replication:如果节点下线太久以至于不能从leader那进行同步,它就会使用solr的基于http进行索引的快照恢复。
2、无法选举分片leader
无法选举分片leader有各种原因,例如分片的每个replicat都挂了(包括leader),再例如replicat均无法与zk保持联系等等,这些情况属于非常极端,不容易出现,且通过重启机器能解决问题。下面,讨论一种在实践中遇到的情况
2.1、场景描述
三台机器,各8GB内存,每台各部署一个实例,测试collection分成两片,每片2个复制集(一个leader,一个replicat)
以每秒2万左右的速度向该集群数据,写入到300多万记录时,出现查询缓慢(http请求延时),replicat出现recovering 状态;接着重启leader,这时候出现分片不可用,选举不出leader

2.2、问题分析
通过查看日志发现,leader与replicat与之间出现大量的http请求超时的情况
也就是是说在写入数据时候,leader向replicat发出的update在leader的finish里会收不到success(根据第三种Recovery情况),从而使得replicat进入recovery状态
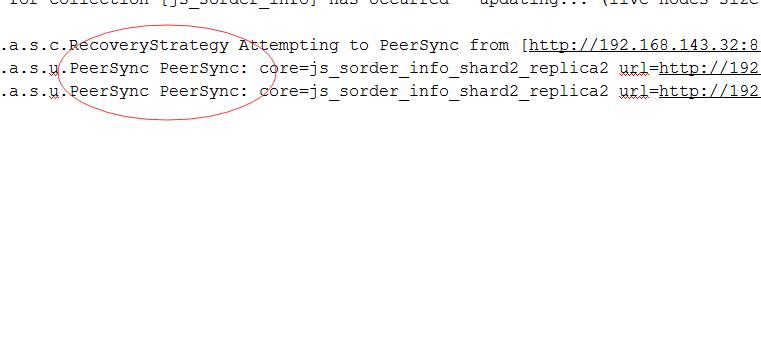
如果replicat在recovery的时候出现leader宕机
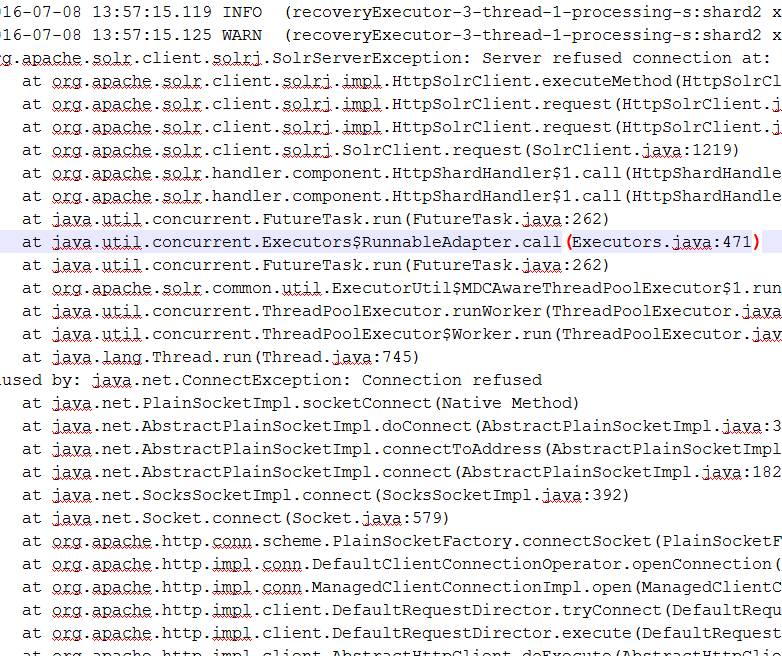
replicat会试图成为leader,而此时replicat真是recovery状态,势必选举成leader失败(片再无其它可用replicat,只有一个leader和一个replicat)
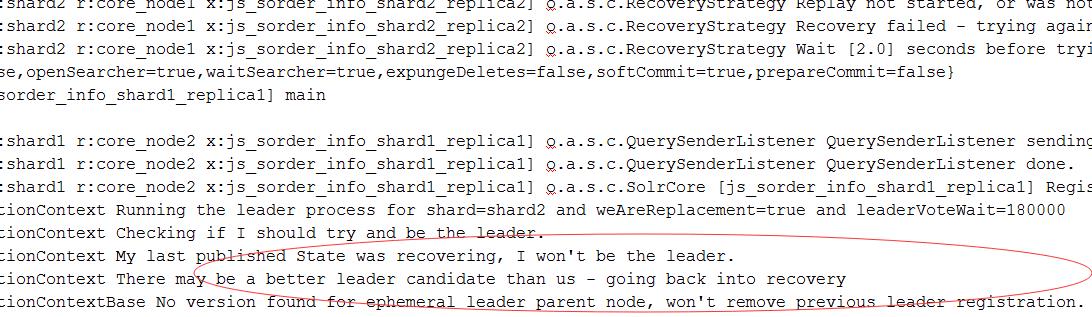
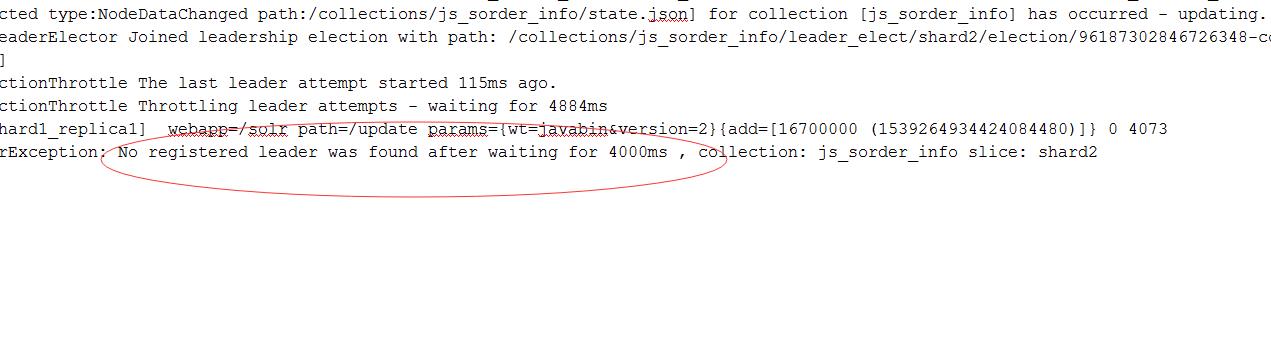
接下来 接下来,分片进入无leader状态,从而导致collection不可用
2.3、解决办法
a、因为solr是http请求方式,写入只会在leader上,然后通过leader DistributedUpdate到各个replicat,评估leader的写入量,结合业务场景是否有这么大的写入量,增加collection的分片来分摊写入
b、增加分片的replicat,上述情况是一个leader,一个replicat,当leader与某一个replicat出现某种原因,导致replicat进入recovery状态,而恰好leader宕机,只能选择该recovery状态的replicat成为leader,必然会失败,如果有多个replicat,就会降低出现这种情况的几率,从而可以从其它replicat中选择一个leader。
c、如果多个replicat同时出现recovery状态,而且leader宕机(这是极端例子),只能stop所有机器,然后重启
2.4、注意
a、在增加replicat的同时,也会降低片的写入的速度(因为写入会DistributedUpdate到各个replicat),可以考虑先停掉所以的replicat,等leader写入完成以后,再启动replicat,不过这只适用于离线场景,在实时场景,往往有大量的查询业务需要replicat分担,写入与查询是并行量大
b、在数据dataimport阶段,写入量大,即使查询超时也不要去强行stop leader
丨往期精选丨
请添加小编微信:2518988391(备注岗位)
以上是关于solrcloud Recovery原理及无法选举分片leader的主要内容,如果未能解决你的问题,请参考以下文章