Solr在医疗大数据检索中的应用
Posted 中国数字医学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr在医疗大数据检索中的应用相关的知识,希望对你有一定的参考价值。
1 引言
大数据时代的到来,信息数据呈爆炸性增长,如何存储并利用这些数据信息便成为一个课题。而基于传统关系型数据库的检索系统因为先天不足,对以下三个问题显得束手无策:一是数据量巨大时的检索速度,传统关系型数据库在数据量小于1000万条时,查询响应时间可调优至几秒至数十秒,而当数据量超过千万级时,无论如何调优或改变索引机制,都无法满足秒级并发查询要求。二是全文检索速度,数据量超过百万千万条时,由于数据库索引不是为全文索引设计,数据库索引有时是不起作用的,使用传统关系型数据库中的like语句进行模糊全文查询时,查询效率会急剧下降,检索过程变成全扫描(full scan)模式,极大占用CPU与内存资源,对含有模糊全文查询的传统关系型数据库服务来说,基于LIKE语句的模糊全文检索对性能的危害是巨大的。三是非结构化数据的检索,传统关系型数据库很难检索处理非结构化数据,而Solr相比传统关系型数据库检索系统性能的优点已成为业内一种共识,使用Solr搭建检索引擎能轻松解决以上三个问题。
2 Solr简介
2.1 Solr概念 Solr是一款基于Java企业级开源检索平台,能作为一个独立完整的检索服务器,提供基于REST的XML和JSON的索引和检索API,以Web Service的形式集成到任意编程语言中使用。Solr的主要功能包括高效灵活的缓存、高速的检索速度、强大的全文检索、提供分布式的检索、索引复制和基于Web的管理界面。
2.2 Solr与医疗大数据 随着大规模的投资涌入移动医疗和医疗大数据行业,医疗卫生信息化不断深入,区域医疗卫生信息一体化建设的概念也逐渐形成。目前各种医疗卫生机构的海量医疗数据以不同格式存放于HIS、PACS、LIS等系统中,使用者需从不同系统中检索提取数据,严重影响操作速度、降低工作效率。当面对不同机构不同系统中海量大数据时,基于传统关系型数据库的BI等系统工具由于其局限性,检索处理速度严重变慢,甚至无法处理,而Solr作为一款性能优异的开源检索引擎,已被广泛运用于大量的网络搜索,使用Solr同样能高效的为这些海量医疗数据建立索引并提供高速的检索异构数据。
3 系统设计
3.1开发环境 操作系统:Center OS6,Solr 版本:apache-solr-4.5.0,运行Web容器:Jetty8。
3.2 系统结构 具体见图1。
图1 基于solr的医疗大数据检索平台
3.2.1 存储模块 存放源数据及与其对应的meta数据的存储设备,本验证采用日立存储HCP。
3.2.2 数据爬取模块 定时爬取存储中的最新meta数据,通过Solr(高速检索引擎模块)的REST API将其上传到Solr中。
3.2.3 检索引擎模块(Solr) 基于文件的高速检索引擎模块,负责为各meta数据文件建立索引并提供高速检索服务。
3.3 系统工作原理 源数据与meta数据以配对形式存放在存储模块中。由数据爬取模块定时爬取存储中的最新meta数据,并将其上传到高速检索引擎模块中,检索引擎模块(Solr)负责为各meta数据文件建立索引并提供高速检索服务。
3.4 医疗数据模型
3.4.1 数据类型 为验证检索引擎Solr的有效性,从HIS数据库中抽取检验报告(html格式),从PACS中抽取dicom文件转换为jpeg格式,从EMR中抽取病程记录(html格式)并建立对应的meta数据,并把这些源数据与meta数据存放到存储模块中,最终由数据爬取模块爬取meta数据并通过Solr的REST API将其上传到Solr中。
3.4.2 索引模型 下面以病程记录为例,说明meta数据格式及如何在Solr中建立索引。
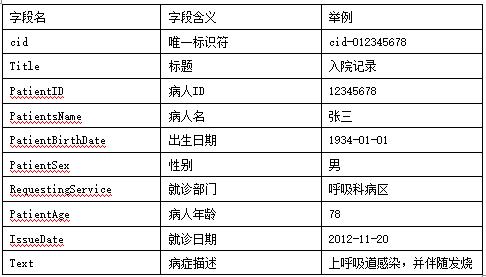
3.4.2.1 meta数据格式 本系统采用xml格式,以下表格为一个病程记录所包含的部分meta数据,将其转化为xml格式并调用Solr的REST API的update方法,便可把此meta数据上传至Solr上,如表1所示。
表1 meta数据格式
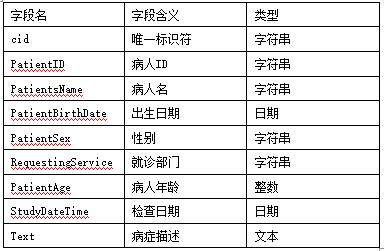
3.4.2.2 建立索引 在Solr的schema.xml中为如下信息添加属性并做设置,便可简单的为这些属性添加索引,如表2所示。并将schema.xml中的uniqueKey标签设置为cid,defaultSearchField标签设置成text。其中field标签的indexed属性为"true" 代表对这一栏建立索引,stored属性为"true" 代表存储这部分数据,待查询后可直接查看这部分数据。schema.xml中defaultSearchField为默认检索的域,solrQueryParserdefaultOperator代表当采用多个查询参数时使用OR来进行连接,如查询“糖尿病、高血压”系统会按照“糖尿病OR高血压”进行查找。
表2 建立索引
4 应用效果
4.1 实验方法 为验证Solr检索的有效性,在医疗大数据平台上构建一个医疗大数据web检索展示系统,使其能通过Solr检索并展示出每个病人的检查、检验报告与病程记录。
4.2 医疗大数据web检索展示系统架构 具体见图2。
图2 web检索展示系统
4.3 医疗大数据检索展示系统原理 如图2所示,我们把分散在HIS、PACS、EMR中的医疗数据整合到同一平台中,把其meta数据上传至Solr并建立索引,在此平台上开发出一个检索展示系统,能通过Solr提供的Java开发库Solrj简单的开发与调用Solr的检索服务。最后在同一界面上展示同一病人在不同系统中的各种医疗数据,并能实现对检查、检验报告、病程记录的全文检索。
4.4 对比分析 对上述系统的性能与传统关系型数据库mysql作为对比,测试用数据量1000万条。Solr采用Java开发库SolrJ中的API,读取查询时间response.getQTime(),数据库采用SQL查询方式。经100次统计测试,Solr平均查询时间为2.93ms,数据库平均查询时间为3150.1ms。由此可见,使用Solr查询的时间是Mysql查询的千分之一量级。
5 结语
企业级开源检索平台Solr功能强大,获取成本低,二次开发效率高,可扩展性强。将Solr强大功能特性应用于医疗大数据平台的建设中具有明显优势,应用前景广阔。设计了基于Solr的医疗大数据检索系统,实现了对海量医疗数据的快速检索,并在最后与传统数据库模式进行比较,Solr作为检索引擎优势是显而易见的,可以进一步提高医疗行业数据搜索工作效率,提升工作效力,带动整体医疗信息检索上一个新平台。
《中国数字医学》微店,点击阅读原文进入。
以上是关于Solr在医疗大数据检索中的应用的主要内容,如果未能解决你的问题,请参考以下文章