Solr简介和使用(一期)
Posted 数据轩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr简介和使用(一期)相关的知识,希望对你有一定的参考价值。
一
Solr全文检索简介
1.1 什么是Solr?
Solr 是Apache下的一个高性能的全文搜索引擎,采用Java开发,它是基于Lucene(Lucene:可以实现站内搜索。需要大量的开发工作。索引库的维护及优化。查询的优化等问题都需要我们自己来解决。)的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
1.2 为什么要选用Solr?
(1)高效、灵活的缓存功能
(2)高亮显示搜索结果,通过索引复制来提高可用性
(3)Solr是一个基于Lucene的Java搜索引擎服务器。包装并扩展了 Lucene,Solr 创建的索引与 Lucene 搜索引擎库完全兼容。
(4)solr可以部署到单独的服务器上(WEB服务),它可以提供服务,我们的业务系统就只要发送请求,接收响应即可,降低了业务系统的负载
(5)solr支持分布式集群
二
全文检索的基本原理
全文检索的原理,可以归结为两个过程:1.索引创建2. 搜索索引。
2.1 Solr反向索引
Solr采用的是一种反向索引,所谓反向索引:就是从关键字到文档的映射过程,保存这种映射这种信息的索引称为反向索引。
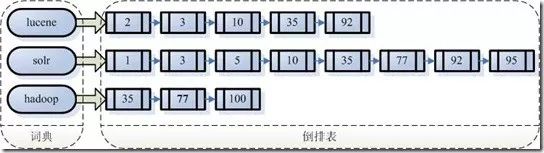
左边保存的是字符串序列
右边是字符串的文档(Document)编号链表,称为倒排表(Posting List)字段串列表和文档编号链表两者构成了一个字典。现在想搜索”lucene”,那么索引直接告诉我们,包含有”lucene”的文档有:2,3,10,35,92,而无需在整个文档库中逐个查找。如果是想搜既包含”lucene”又包含”solr”的文档,那么与之对应的两个倒排表去交集即可获得:3、10、35、92。
2.2 索引创建
假设有如下两个原始文档:
文档一:Students should be allowed to go out with their friends, but not allowed to drink beer.
文档二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
(1) 把原始文档交给分词组件(Tokenizer)
分词组件(Tokenizer)会做以下几件事情(这个过程称为:Tokenize),处理得到的结果是词汇单元(Token)
1. 将文档分成一个一个单独的单词
2. 去除标点符号
3. 去除停词(stop word)
所谓停词(Stop word)就是一种语言中没有具体含义,因而大多数情况下不会作为搜索的关键词,这样一来创建索引时能减少索引的大小。英语中停词(Stop word)如:”the”、”a”、”this”,中文有:”的,得”等。不同语种的分词组件(Tokenizer),都有自己的停词(stop word)集合。经过分词(Tokenizer)后得到的结果称为词汇单元(Token)。上例子中,便得到以下词汇单元(Token):
"Students","allowed","go","their","friends","allowed","drink","beer","My","friend","Jerry","went","school","see","his","students","found","them","drunk","allowed"
(2) 词汇单元(Token)传给语言处理组件(Linguistic Processor)
语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些语言相关的处理。对于英语,语言处理组件(Linguistic Processor)一般做以下几点:
1. 变为小写(Lowercase)。
2. 将单词缩减为词根形式,如”cars”到”car”等。
3. 将单词转变为词根形式,如”drove”到”drive”等。
语言处理组件(linguistic processor)处理得到的结果称为词(Term),例子中经过语言处理后得到的词(Term)如下:
"student","allow","go","their","friend","allow","drink","beer","my","friend","jerry","go","school","see","his","student","find","them","drink","allow"。
经过语言处理后,搜索drive时drove也能被搜索出来。Stemming 和 lemmatization的异同:
相同之处:
Stemming和lemmatization都要使词汇成为词根形式。
两者的方式不同:
1. Stemming采用的是”缩减”的方式:
"cars”到”car”,”driving”到”drive”。
2. Lemmatization采用的是”转变”的方式:”drove”到”drove”,”driving”到”drive”。
(3) 得到的词(Term)传递给索引组件(Indexer)
A :利用得到的词(Term)创建一个字典
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2
jerry 2
go 2
school 2
see 2
his 2
student 2
find 2
them 2
drink 2
allow 2
B:对字典按字母顺序排序:
Term Document ID
allow 1
allow 1
allow 2
beer 1
drink 1
drink 2
find 2
friend 1
friend 2
go 1
go 2
his 2
jerry 2
my 2
school 2
see 2
student 1
student 2
their 1
them 2
C 合并相同的词(Term)成为文档倒排(Posting List)链表
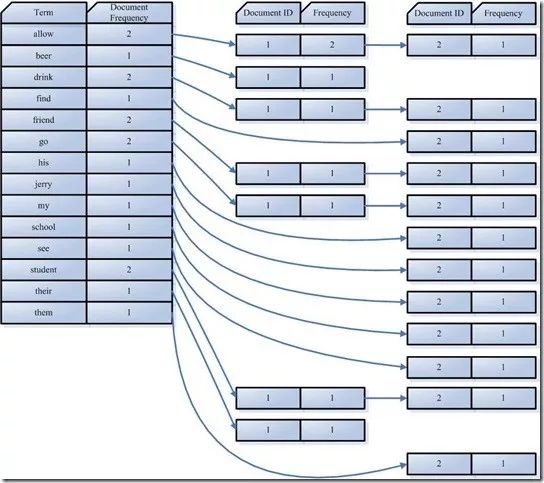
Document Frequency:文档频次,表示多少文档出现过此词(Term)
Frequency:词频,表示某个文档中该词(Term)出现过几次
对词(Term) “allow”来讲,总共有两篇文档包含此词(Term),词(Term)后面的文档链表总共有两个,第一个表示包含”allow”的第一篇文档,即1号文档,此文档中,”allow”出现了2次,第二个表示包含”allow”的第二个文档,是2号文档,此文档中,”allow”出现了1次
至此索引创建完成,搜索”drive”时,”driving”,”drove”,”driven”也能够被搜到。因为在索引中,”driving”,”drove”,”driven”都会经过语言处理而变成”drive”,在搜索时,如果您输入”driving”,输入的查询语句同样经过分词组件和语言处理组件处理的步骤,变为查询”drive”,从而可以搜索到想要的文档
2.3 搜索步骤
搜索”microsoft job”,用户的目的是希望在微软找一份工作,如果搜出来的结果
是:”Microsoft does a good job at software industry…”,这就与用户的期望
偏离太远了。如何进行合理有效的搜索,搜索出用户最想要得结果呢?
搜索主要有如下步骤:
(1) 对查询内容进行词法分析、语法分析、语言处理
A :词法分析:区分查询内容中单词和关键字,比如:english and janpan,”and”就是关键字,”english”和”janpan”是普通单词。
B:根据查询语法的语法规则形成一棵树
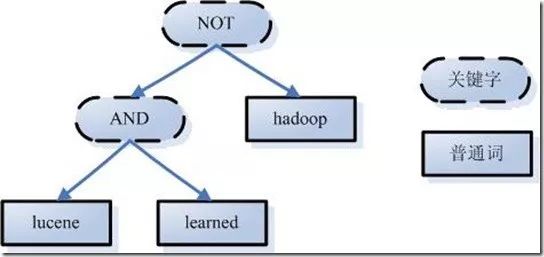
C:语言处理,和创建索引时处理方式是一样的。比如:leaned–>lean,driven–>drive
(2) 对查询内容进行词法分析、语法分析、语言处理
(3) 根据查询语句与文档的相关性,对结果进行排序
我们把查询语句也看作是一个文档,对文档与文档之间的相关性(relevance)进行打分(scoring),分数高比较越相关,排名就越靠前。这就引申出权重(Term weight)的概念。权重表示该词在文档中的重要程度,越重要的词当然权重越高,因此在计算文档相关性时影响力就更大。通过词之间的权重得到文档相关性的过程叫做空间向量模型算法(Vector Space Model)

END
数据轩
关于大数据的“术、道、势”
科技|应用|趋势
以上是关于Solr简介和使用(一期)的主要内容,如果未能解决你的问题,请参考以下文章