solr使用教程二面试+工作
Posted Java帮帮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了solr使用教程二面试+工作相关的知识,希望对你有一定的参考价值。
6.3高亮显示
我们经常使用搜索引擎,比如在baidu 搜索 java ,会出现如下结果,结果中与关键字匹配的地方是红色显示与其他内容区别开来。
solr 默认已经配置了highlight 组件(详见 SOLR_HOME/conf/sorlconfig.xml)。通常我出只需要这样请求http://localhost:8983/solr/ collection1 /select? q=%E4%B8%AD%E5%9B%BD&start=0&rows=1&fl=content+path+&wt=xml&indent=true&hl=true&hl.fl=content
可以看到与比一般的请求多了两个参数 "hl=true" 和 "hl.fl= content " 。
"hl=true" 是开启高亮,"hl.fl= content " 是告诉solr 对 name 字段进行高亮(如果你想对多个字段进行高亮,可以继续添加字段,字段间用逗号隔开,如 "hl.fl=name,name2,name3")。 高亮内容与关键匹配的地方,默认将会被 "<em>" 和 "</em>" 包围。还可以使用hl.simple.pre" 和 "hl.simple.post"参数设置前后标签.
查询结果如下:

<?xml version="1.0" encoding="UTF-8"?> <response> <lst name="responseHeader"> <int name="status">0</int> <int name="QTime">2</int> <lst name="params"> <str name="fl">content path</str> <str name="indent">true</str> <str name="start">0</str> <str name="q">中国</str> <str name="hl.simple.pre"><em></str> <str name="hl.simple.post"></em></str> <str name="hl.fl">content</str> <str name="wt">xml</str> <str name="hl">true</str> <str name="rows">1</str> </lst> </lst> <result name="response" numFound="6799" start="0"> <doc> <str name="path">E:\Reduced\IT\630.txt</str> <str name="content"> 本报讯 中国银联股份有限公司和中国电信集团日前在北京签署全面战略合作协议。 这标志着中国银联和中国电信将在通信服务、信息增值服务、新型支付产品合作开发等领域建立全面合作伙伴关系。 据悉,双方签署的全面战略合作协议主要内容是:中国银联将选择中国电信作为通信信息服务的主要提供商, 双方围绕提高中国银联内部通信的水平和销售网络的服务水平开展全面、深入的合作; 中国电信选择中国银联作为银行卡转接支付服务的主要提供商,并围绕开发、推广新型支付终端产品和增值服务开展全面合作。(辛华) </str> </doc> </result> <lst name="highlighting"> <lst name="7D919C61-03B3-4B6F-2D10-9E3CC92D2852"> <arr name="content"> <str> 本报讯 <em> 中国 </em> 银联股份有限公司和 <em> 中国 </em> 电信集团日前在北京签署全面战略合作协议。这标志着 <em> 中国 </em> 银联和 <em> 中国 </em> 电信将在通信服务、信息增值服务、新型支付产品合作开发等领域建立全面合作伙伴关系。 据悉,双方签署 </str> </arr> </lst> </lst> </response> |
使用SolrJ方法基本一样也是设置这些个参数,只不过是SolrJ封装起来了,代码如下:
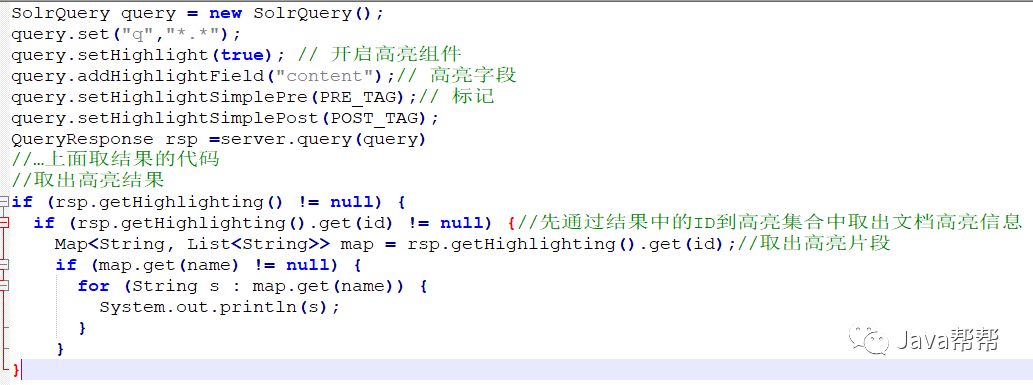
SolrQuery query = new SolrQuery(); query.set("q","*.*"); query.setHighlight(true); // 开启高亮组件 query.addHighlightField("content");// 高亮字段 query.setHighlightSimplePre(PRE_TAG);// 标记 query.setHighlightSimplePost(POST_TAG); QueryResponse rsp =server.query(query) //…上面取结果的代码 //取出高亮结果 if (rsp.getHighlighting() != null) { if (rsp.getHighlighting().get(id) != null) {//先通过结果中的ID到高亮集合中取出文档高亮信息 Map<String, List<String>> map = rsp.getHighlighting().get(id);//取出高亮片段 if (map.get(name) != null) { for (String s : map.get(name)) { System.out.println(s); } } } |
6.4拼写检查
首先配置 solrconfig.xml,文件可能已经有这两个元素(如果没有添加即可),需要根据我们自己的系统环境做些适当的修改。
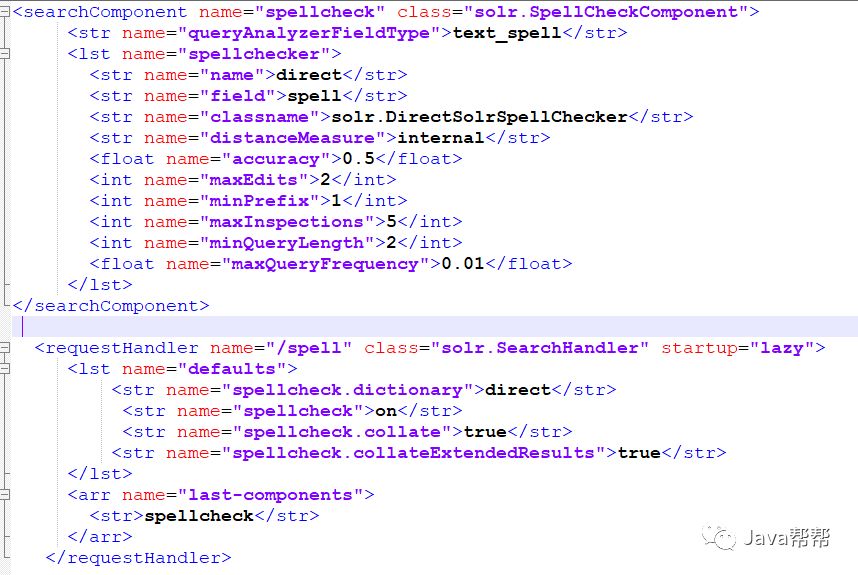
<searchComponent name="spellcheck" class="solr.SpellCheckComponent"> <str name="queryAnalyzerFieldType">text_spell</str><lst name="spellchecker"> <str name="name">direct</str> <str name="field">spell</str> <str name="classname">solr.DirectSolrSpellChecker</str> <str name="distanceMeasure">internal</str> <float name="accuracy">0.5</float> <int name="maxEdits">2</int> <int name="minPrefix">1</int> <int name="maxInspections">5</int> <int name="minQueryLength">2</int> <float name="maxQueryFrequency">0.01</float> </lst> </searchComponent> <requestHandler name="/spell" class="solr.SearchHandler" startup="lazy"> <lst name="defaults"> <str name="spellcheck.dictionary">direct</str> <str name="spellcheck">on</str> <str name="spellcheck.collate">true</str> <str name="spellcheck.collateExtendedResults">true</str> </lst> <arr name="last-components"> <str>spellcheck</str> </arr> </requestHandler> |
配置完成之后,我们进行一下测试,重启Solr后,访问如下链接
http://localhost:8983/solr/ collection1/spell?wt=xml&indent=true&spellcheck=true&spellcheck.q=%E4%B8%AD%E5%9B%BD
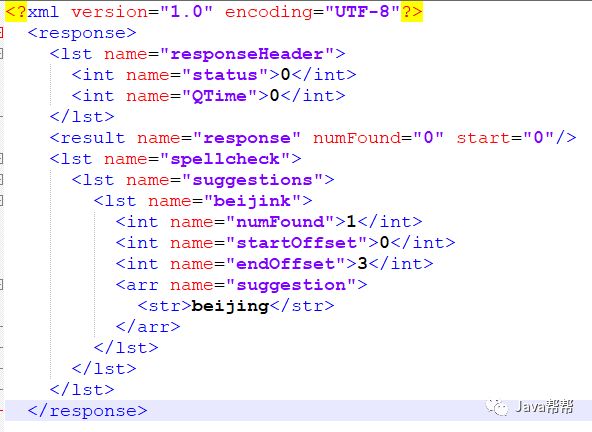
<?xml version="1.0" encoding="UTF-8"?> <response><lst name="responseHeader"> <int name="status">0</int> <int name="QTime">0</int> </lst> <result name="response" numFound="0" start="0"/> <lst name="spellcheck"> <lst name="suggestions"> <lst name="beijink"> <int name="numFound">1</int> <int name="startOffset">0</int> <int name="endOffset">3</int> <arr name="suggestion"> <str>beijing</str> </arr> </lst> </lst> </lst> </response> |
使用SolrJ时也同样加入参数就可以

SolrQuery query = new SolrQuery(); query.set("q","*.*"); query.set("qt", "/spell"); QueryResponse rsp =server.query(query) //…上面取结果的代码 SpellCheckResponse spellCheckResponse = rsp.getSpellCheckResponse(); if (spellCheckResponse != null) { String collation = spellCheckResponse.getCollatedResult(); } |
使用SolrJ时也同样加入参数就可以
6.5检索建议
检索建议目前是各大搜索的标配应用,主要作用是避免用户输入错误的搜索词,同时将用户引导到相应的关键词搜索上。Solr内置了检索建议功能,它在Solr里叫做Suggest模块.该模块可选择基于提示词文本做检索建议,还支持通过针对索引的某个字段建立索引词库做检索建议。在诸多文档中都推荐使用基于索引来做检索建议,因此我们目前的实现也是采取该方案。
现在我们开始配置Suggest模块,首先在solrconfig.xml文件中配置Suggest依赖的SpellChecker模块,然后再配置Suggest模块,所以这两个都需要配置。
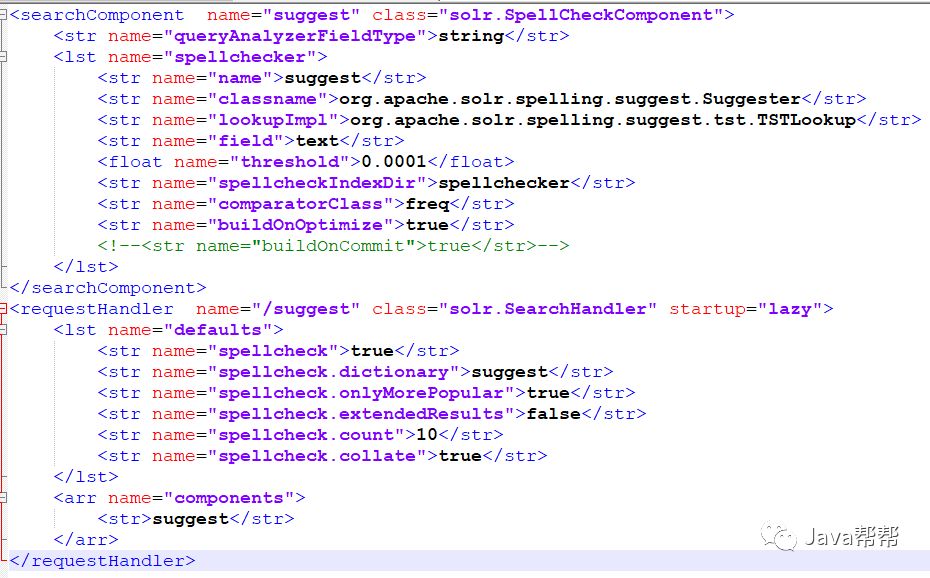
<searchComponent name="suggest" class="solr.SpellCheckComponent"> <str name="queryAnalyzerFieldType">string</str> <lst name="spellchecker"> <str name="name">suggest</str> <str name="classname">org.apache.solr.spelling.suggest.Suggester</str> <str name="lookupImpl">org.apache.solr.spelling.suggest.tst.TSTLookup</str> <str name="field">text</str> <float name="threshold">0.0001</float> <str name="spellcheckIndexDir">spellchecker</str> <str name="comparatorClass">freq</str> <str name="buildOnOptimize">true</str> <!--<str name="buildOnCommit">true</str>--> </lst> </searchComponent> <requestHandler name="/suggest" class="solr.SearchHandler" startup="lazy"> <lst name="defaults"> <str name="spellcheck">true</str> <str name="spellcheck.dictionary">suggest</str> <str name="spellcheck.onlyMorePopular">true</str> <str name="spellcheck.extendedResults">false</str> <str name="spellcheck.count">10</str> <str name="spellcheck.collate">true</str> </lst> <arr name="components"> <str>suggest</str> </arr> </requestHandler> |
配置完成之后,我们进行一下测试,重启Solr后,访问如下链接
http://localhost:8983/solr/ collection1/suggest?wt=xml&indent=true&spellcheck=true&spellcheck.q=%E4%B8%AD%E5%9B%BD

<?xml version="1.0" encoding="UTF-8"?> <response> <lst name="responseHeader"> <int name="status">0</int> <int name="QTime">4</int> </lst> <lst name="spellcheck"> <lst name="suggestions"> <lst name="中国"> <int name="numFound">4</int> <int name="startOffset">0</int> <int name="endOffset">2</int> <arr name="suggestion"> <str> 中国队 </str> <str> 中国证监会 </str> <str> 中国足协 </str> <str> 中国银行 </str> </arr> </lst> </lst> </lst> </response> |
使用SolrJ时也同样加入参数就可以
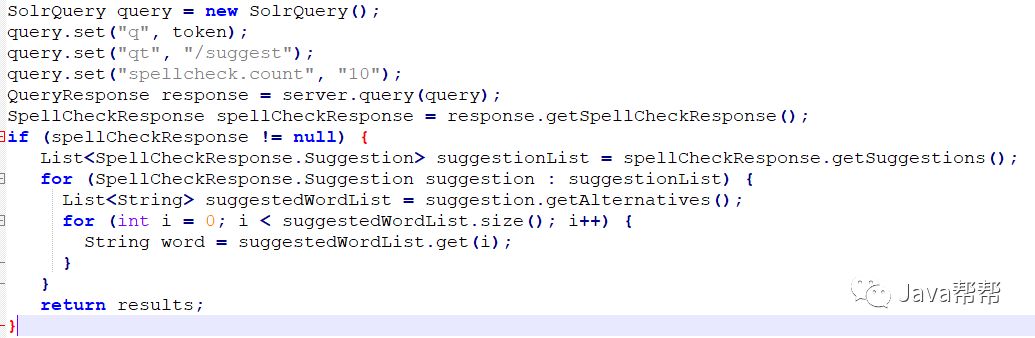
SolrQuery query = new SolrQuery(); query.set("q", token); query.set("qt", "/suggest"); query.set("spellcheck.count", "10"); QueryResponse response = server.query(query); SpellCheckResponse spellCheckResponse = response.getSpellCheckResponse(); if (spellCheckResponse != null) { List<SpellCheckResponse.Suggestion> suggestionList = spellCheckResponse.getSuggestions(); for (SpellCheckResponse.Suggestion suggestion : suggestionList) { List<String> suggestedWordList = suggestion.getAlternatives(); for (int i = 0; i < suggestedWordList.size(); i++) { String word = suggestedWordList.get(i); } } return results; } |
通过threshold参数来限制一些不常用的词不出现在智能提示列表中,当这个值设置过大时,可能导致结果太少,需要引起注意。目前主要存在的问题是使用freq排序算法,返回的结果完全基于索引中字符的出现次数,没有兼顾用户搜索词语的频率,因此无法将一些热门词排在更靠前的位置。这块可定制SuggestWordScoreComparator来实现,目前还没有着手做这件事情。
6.6分组统计
我这里实现分组统计的方法是使用了Solr的Facet组件, Facet组件是Solr默认集成的一个组件.
6.6.1 Facet简介
Facet是solr的高级搜索功能之一,可以给用户提供更友好的搜索体验.在搜索关键字的同时,能够按照Facet的字段进行分组并统计
6.6.2 Facet字段
1.适宜被Facet的字段
一般代表了实体的某种公共属性,如商品的分类,商品的制造厂家,书籍的出版商等等.
2.Facet字段的要求
Facet的字段必须被索引.一般来说该字段无需分词,无需存储.
无需分词是因为该字段的值代表了一个整体概念,如电脑的品牌”联想”代表了一个整 体概念,如果拆成”联”,”想”两个字都不具有实际意义.另外该字段的值无需进行大小 写转换等处理,保持其原貌即可.
无需存储是因为一般而言用户所关心的并不是该字段的具体值,而是作为对查询结果进 行分组的一种手段,用户一般会沿着这个分组进一步深入搜索.
3.特殊情况
对于一般查询而言,分词和存储都是必要的.比如CPU类型”Intel 酷睿2双核 P7570”, 拆分成”Intel”,”酷睿”,”P7570”这样一些关键字并分别索引,可能提供更好的搜索 体验.但是如果将CPU作为Facet字段,最好不进行分词.这样就造成了矛盾,解决方法为, 将CPU字段设置为不分词不存储,然后建立另外一个字段为它的COPY,对这个COPY的 字段进行分词和存储.
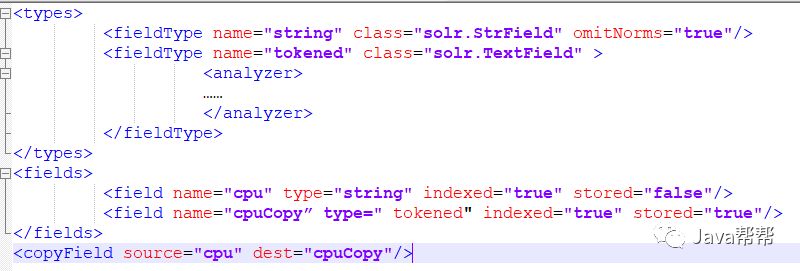
<types> <fieldType name="string" class="solr.StrField" omitNorms="true"/> <fieldType name="tokened" class="solr.TextField" > <analyzer> …… </analyzer> </fieldType> </types> <fields> <field name="cpu" type="string" indexed="true" stored="false"/> <field name="cpuCopy” type=" tokened" indexed="true" stored="true"/> </fields> <copyField source="cpu" dest="cpuCopy"/> |
6.6.2 Facet组件
Solr的默认requestHandler已经包含了Facet组件(solr.FacetComponent).如果自定义requestHandler或者对默认的requestHandler自定义组件列表,那么需要将Facet加入到组件列表中去.
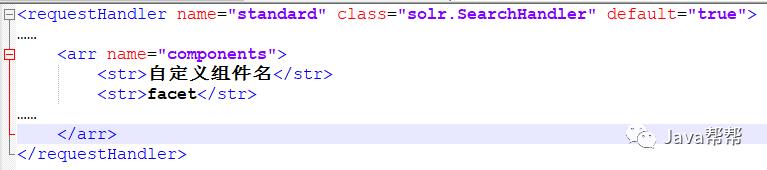
<requestHandler name="standard" class="solr.SearchHandler" default="true"> …… <arr name="components"> <str>自定义组件名</str> <str>facet</str> …… </arr> </requestHandler> |
6.6.2 Facet查询
进行Facet查询需要在请求参数中加入facet=on或者facet=true只有这样Facet组件才起作用.
1.Field Facet
Facet字段通过在请求中加入facet.field参数加以声明,如果需要对多个字段进行Facet查询,那么将该参数声明多次.例如:
http://localhost:8983/solr/ collection1/select?q=*%3A*&start=0&rows=1&wt=xml&indent=true&facet=true&facet.field=category_s&facet.field=modified_l
返回结果:

<?xml version="1.0" encoding="UTF-8"?> <response> <lst name="responseHeader"> <int name="status">0</int> <int name="QTime">1</int> <lst name="params"> <str name="facet">true</str> <str name="indent">true</str> <str name="start">0</str> <str name="q">*:*</str> <arr name="facet.field"> <str>category_s</str> <str>modified_l</str> </arr> <str name="wt">xml</str> <str name="rows">0</str> </lst> </lst> <result name="response" numFound="17971" start="0"></result> <lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"> <lst name="category_s"> <int name="0">5991</int> <int name="1">5990</int> <int name="2">5990</int> </lst> <lst name="modified_l"> <int name="1162438554000">951</int> <int name="1162438556000">917</int> <int name="1162438548000">902</int> <int name="1162438546000">674</int> </lst> </lst> <lst name="facet_dates"/> <lst name="facet_ranges"/> </lst> </response> |
各个Facet字段互不影响,且可以针对每个Facet字段设置查询参数.以下介绍的参数既可以应用于所有的Facet字段,也可以应用于每个单独的Facet字段.应用于单独的字段时通过
f.字段名.参数名=参数值 |
这种方式调用.比如facet.prefix参数应用于cpu字段,可以采用如下形式
f.cpu.facet.prefix=Intel |
1.1facet.prefix
表示Facet字段值的前缀.比如facet.field=cpu&facet.prefix=Intel,那么对cpu字段进行Facet查询,返回的cpu都是以Intel开头的, AMD开头的cpu型号将不会被统计在内.
1.2facet.sort
表示Facet字段值以哪种顺序返回.可接受的值为true(count)|false(index,lex). true(count)表示按照count值从大到小排列. false(index,lex)表示按照字段值的自然顺序(字母,数字的顺序)排列.默认情况下为true(count).当facet.limit值为负数时,默认facet.sort= false(index,lex).
1.3facet.limit
限制Facet字段返回的结果条数.默认值为100.如果此值为负数,表示不限制.
1.4facet.offset
返回结果集的偏移量,默认为0.它与facet.limit配合使用可以达到分页的效果.
1.5facet.mincount
限制了Facet字段值的最小count,默认为0.合理设置该参数可以将用户的关注点集中在少数比较热门的领域.
1.6facet.missing
默认为””,如果设置为true或者on,那么将统计那些该Facet字段值为null的记录.
1.7facet.method
取值为enum或fc,默认为fc.该字段表示了两种Facet的算法,与执行效率相关.
enum适用于字段值比较少的情况,比如字段类型为布尔型,或者字段表示中国的所有省份.Solr会遍历该字段的所有取值,并从filterCache里为每个值分配一个filter(这里要求solrconfig.xml里对filterCache的设置足够大).然后计算每个filter与主查询的交集.
fc(表示Field Cache)适用于字段取值比较多,但在每个文档里出现次数比较少的情况.Solr会遍历所有的文档,在每个文档内搜索Cache内的值,如果找到就将Cache内该值的count加1.
1.8facet.enum.cache.minDf
当facet.method=enum时,此参数其作用,minDf表示minimum document frequency.也就是文档内出现某个关键字的最少次数.该参数默认值为0.设置该参数可以减少filterCache的内存消耗,但会增加总的查询时间(计算交集的时间增加了).如果设置该值的话,官方文档建议优先尝试25-50内的值.
6.6.3 Date Facet
日期类型的字段在文档中很常见,如商品上市时间,货物出仓时间,书籍上架时间等等.某些情况下需要针对这些字段进行Facet.不过时间字段的取值有无限性,用户往往关心的不是某个时间点而是某个时间段内的查询统计结果. Solr为日期字段提供了更为方便的查询统计方式.当然,字段的类型必须是DateField(或其子类型).
需要注意的是,使用Date Facet时,字段名,起始时间,结束时间,时间间隔这4个参数都必须提供.与Field Facet类似,Date Facet也可以对多个字段进行Facet.并且针对每个字段都可以单独设置参数.
facet.date:该参数表示需要进行Date Facet的字段名,与facet.field一样,该参数可以被设置多次,表示对多个字段进行Date Facet.
facet.date.start:起始时间,时间的一般格式为1995-12-31T23:59:59Z,另外可以使用NOW\YEAR\ MONTH等等,具体格式可以参考DateField的java doc.
facet.date.end:结束时间.
facet.date.gap:时间间隔.如果start为2009-1-1,end为2010-1-1.gap设置为+1MONTH表示间隔1个月,那么将会把这段时间划分为12个间隔段.
注意+因为是特殊字符所以应该用%2B代替.
facet.date.hardend:取值可以为true|false,默认为false.它表示gap迭代到end处采用何种处理.举例说明start为2009-1-1,end为2009-12-25,gap为+1MONTH,
hardend为false的话最后一个时间段为2009-12-1至2010-1-1;
hardend为true的话最后一个时间段为2009-12-1至2009-12-25.
facet.date.other:取值范围为before|after|between|none|all,默认为none.before会对start之前的值做统计.after会对end之后的值做统计.between会对start至end之间所有值做统计.如果hardend为true的话,那么该值就是各个时间段统计值的和.none表示该项禁用.all表示before,after,all都会统计.
举例:
&facet=on &facet.date=date &facet.date.start=2009-1-1T0:0:0Z &facet.date.end=2010-1-1T0:0:0Z &facet.date.gap=%2B1MONTH &facet.date.other=all |
返回结果:
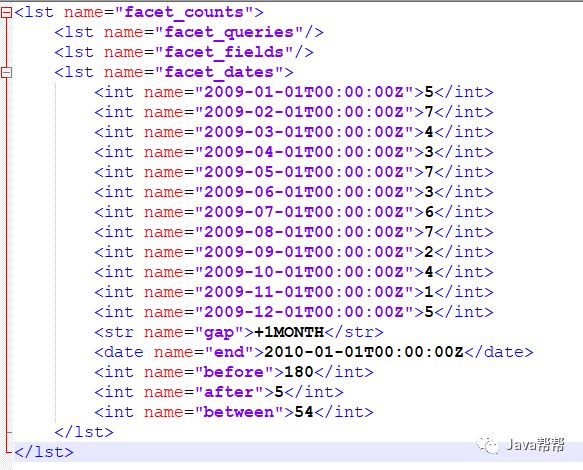
<lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"/> <lst name="facet_dates"> <int name="2009-01-01T00:00:00Z">5</int> <int name="2009-02-01T00:00:00Z">7</int> <int name="2009-03-01T00:00:00Z">4</int> <int name="2009-04-01T00:00:00Z">3</int> <int name="2009-05-01T00:00:00Z">7</int> <int name="2009-06-01T00:00:00Z">3</int> <int name="2009-07-01T00:00:00Z">6</int> <int name="2009-08-01T00:00:00Z">7</int> <int name="2009-09-01T00:00:00Z">2</int> <int name="2009-10-01T00:00:00Z">4</int> <int name="2009-11-01T00:00:00Z">1</int> <int name="2009-12-01T00:00:00Z">5</int> <str name="gap">+1MONTH</str> <date name="end">2010-01-01T00:00:00Z</date> <int name="before">180</int> <int name="after">5</int> <int name="between">54</int> </lst> </lst> |
6.6.4 Facet Query
Facet Query利用类似于filter query的语法提供了更为灵活的Facet.通过facet.query参数,可以对任意字段进行筛选.
例1:
&facet=on &facet.query=date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z] &facet.query=date:[2009-4-1T0:0:0Z TO 2009-5-1T0:0:0Z] |
返回结果:
<lst name="facet_counts"> <lst name="facet_queries"> <int name="date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]">5</int> <int name="date:[2009-4-1T0:0:0Z TO 2009-5-1T0:0:0Z]">3</int> </lst> <lst name="facet_fields"/> <lst name="facet_dates"/> </lst> |
例2:
&facet=on &facet.query=date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z] &facet.query=price:[* TO 5000] |
返回结果:
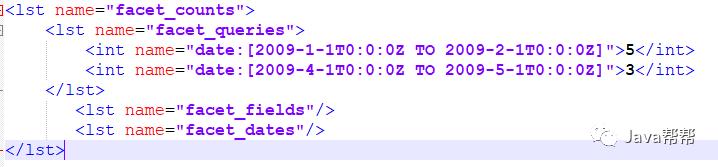
<lst name="facet_counts"> <lst name="facet_queries"> <int name="date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]">5</int> <int name="date:[2009-4-1T0:0:0Z TO 2009-5-1T0:0:0Z]">3</int> </lst> <lst name="facet_fields"/> <lst name="facet_dates"/> </lst> |
例3:
&facet=on &facet.query=cpu:[A TO G] |
返回结果:
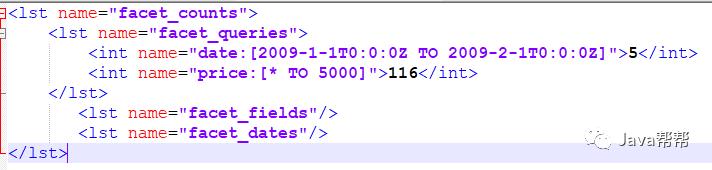
<lst name="facet_counts"> <lst name="facet_queries"> <int name="cpu:[A TO G]">11</int> </lst> <lst name="facet_fields"/> <lst name="facet_dates"/> </lst> |
6.6.5 key操作符
可以用key操作符为Facet字段取一个别名.
例:
&facet=on &facet.field={!key=中央处理器}cpu &facet.field={!key=显卡}videoCard |
返回结果:
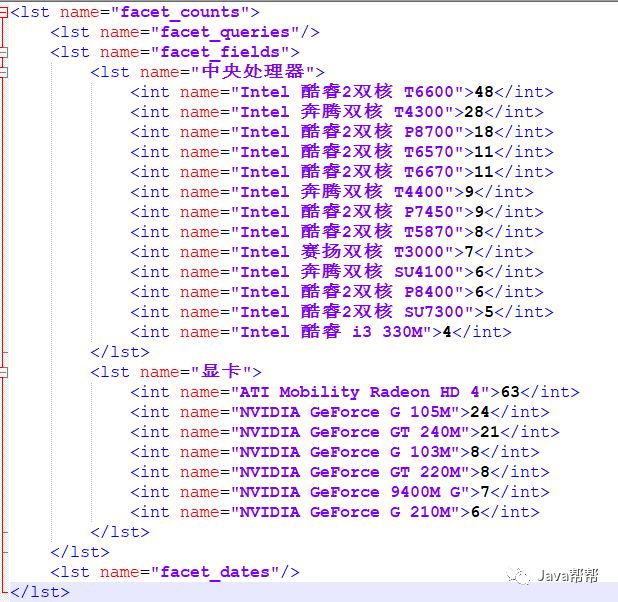
<lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"> <lst name="中央处理器"> <int name="Intel 酷睿2双核 T6600">48</int> <int name="Intel 奔腾双核 T4300">28</int> <int name="Intel 酷睿2双核 P8700">18</int> <int name="Intel 酷睿2双核 T6570">11</int> <int name="Intel 酷睿2双核 T6670">11</int> <int name="Intel 奔腾双核 T4400">9</int> <int name="Intel 酷睿2双核 P7450">9</int> <int name="Intel 酷睿2双核 T5870">8</int> <int name="Intel 赛扬双核 T3000">7</int> <int name="Intel 奔腾双核 SU4100">6</int> <int name="Intel 酷睿2双核 P8400">6</int> <int name="Intel 酷睿2双核 SU7300">5</int> <int name="Intel 酷睿 i3 330M">4</int> </lst> <lst name="显卡"> <int name="ATI Mobility Radeon HD 4">63</int> <int name="NVIDIA GeForce G 105M">24</int> <int name="NVIDIA GeForce GT 240M">21</int> <int name="NVIDIA GeForce G 103M">8</int> <int name="NVIDIA GeForce GT 220M">8</int> <int name="NVIDIA GeForce 9400M G">7</int> <int name="NVIDIA GeForce G 210M">6</int> </lst> </lst> <lst name="facet_dates"/> </lst> |
6.6.6 tag操作符和ex操作符
当查询使用filter query的时候,如果filter query的字段正好是Facet字段,那么查询结果往往被限制在某一个值内.
例:
&fq=screenSize:14 &facet=on &facet.field=screenSize |
返回结果:
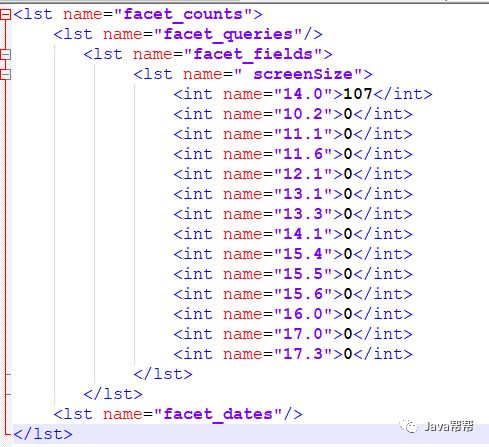
<lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"> <lst name=" screenSize"> <int name="14.0">107</int> <int name="10.2">0</int> <int name="11.1">0</int> <int name="11.6">0</int> <int name="12.1">0</int> <int name="13.1">0</int> <int name="13.3">0</int> <int name="14.1">0</int> <int name="15.4">0</int> <int name="15.5">0</int> <int name="15.6">0</int> <int name="16.0">0</int> <int name="17.0">0</int> <int name="17.3">0</int> </lst> </lst> <lst name="facet_dates"/> </lst> |
可以看到,屏幕尺寸(screenSize)为14寸的产品共有107件,其它尺寸的产品的数目都是0,这是因为在filter里已经限制了screenSize:14.这样,查询结果中,除了screenSize=14的这一项之外,其它项目没有实际的意义.有些时候,用户希望把结果限制在某一范围内,又希望查看该范围外的概况.比如上述情况,既要把查询结果限制在14寸屏的笔记本,又想查看一下其它屏幕尺寸的笔记本有多少产品.这个时候需要用到tag和ex操作符.tag就是把一个filter标记起来,ex(exclude)是在Facet的时候把标记过的filter排除在外.
例:
&fq={!tag=aa}screenSize:14 &facet=on &facet.field={!ex=aa}screenSize |
返回结果:
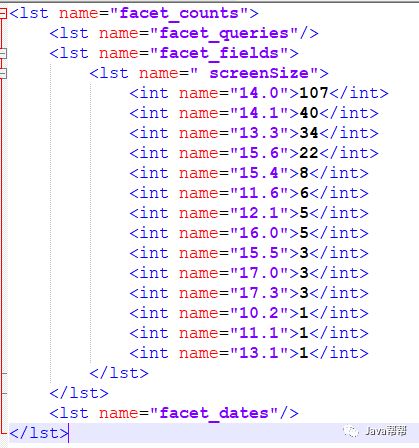
<lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"> <lst name=" screenSize"> <int name="14.0">107</int> <int name="14.1">40</int> <int name="13.3">34</int> <int name="15.6">22</int> <int name="15.4">8</int> <int name="11.6">6</int> <int name="12.1">5</int> <int name="16.0">5</int> <int name="15.5">3</int> <int name="17.0">3</int> <int name="17.3">3</int> <int name="10.2">1</int> <int name="11.1">1</int> <int name="13.1">1</int> </lst> </lst> <lst name="facet_dates"/> </lst> |
这样其它屏幕尺寸的统计信息就有意义了.
6.6.7 SolrJ对Facet的支持
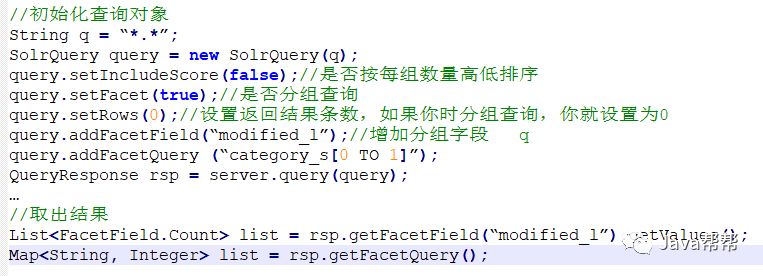
//初始化查询对象 String q = “*.*”; SolrQuery query = new SolrQuery(q); query.setIncludeScore(false);//是否按每组数量高低排序 query.setFacet(true);//是否分组查询 query.setRows(0);//设置返回结果条数,如果你时分组查询,你就设置为0 query.addFacetField(“modified_l”);//增加分组字段 q query.addFacetQuery (“category_s[0 TO 1]”); QueryResponse rsp = server.query(query); … //取出结果 List<FacetField.Count> list = rsp.getFacetField(“modified_l”).getValues(); Map<String, Integer> list = rsp.getFacetQuery(); |
6.7自动聚类
Solr 使用Carrot2完成了聚类功能,能够把检索到的内容自动分类, Carrot2聚类示例:
要想Solr支持聚类功能,首选要把Solr发行包的中的dist/ solr-clustering-4.2.0.jar, 复制到\solr\contrib\analysis-extras\lib下.然后打开solrconfig.xml进行添加配置:

<searchComponent name="clustering" enable="${solr.clustering.enabled:true}" class="solr.clustering.ClusteringComponent" > <lst name="engine"> <str name="name">default</str> <str name="carrot.algorithm">org.carrot2.clustering.lingo.LingoClusteringAlgorithm</str> <str name="LingoClusteringAlgorithm.desiredClusterCountBase">20</str> </lst> </searchComponent> |
配好了聚类组件后,下面配置requestHandler:
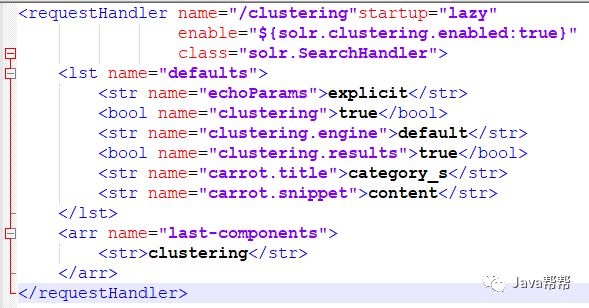
<requestHandler name="/clustering"startup="lazy" enable="${solr.clustering.enabled:true}" class="solr.SearchHandler"> <lst name="defaults"> <str name="echoParams">explicit</str> <bool name="clustering">true</bool> <str name="clustering.engine">default</str> <bool name="clustering.results">true</bool> <str name="carrot.title">category_s</str> <str name="carrot.snippet">content</str> </lst> <arr name="last-components"> <str>clustering</str> </arr> </requestHandler> |
有两个参数要注意carrot.title, carrot.snippet是聚类的比较计算字段,这两个参数必须是stored="true".carrot.title的权重要高于carrot.snippet,如果只有一个做计算的字段carrot.snippet可以去掉(是去掉不是值为空).设完了用下面的URL就可以查询了
http://localhost:8983/skyCore/clustering?q=*%3A*&wt=xml&indent=true
6.8相似匹配
在我们使用网页搜索时,会注意到每一个结果都包含一个“相似页面” 链接,单击该链接,就会发布另一个搜索请求,查找出与起初结果类似的文档。Solr 使用 MoreLikeThisComponent(MLT)和 MoreLikeThisHandler 实现了一样的功能。如上所述,MLT 是与标准 SolrRequestHandler 集成在一起的;MoreLikeThisHandler 与 MLT 结合在一起,并添加了一些其他选项,但它要求发布一个单一的请求。我将着重讲述 MLT,因为使用它的可能性更大一些。幸运的是,不需要任何设置就可以查询它,所以您现在就可以开始查询。
MLT 要求字段被储存或使用检索词向量,检索词向量以一种以文档为中心的方式储存信息。MLT 通过文档的内容来计算文档中关键词语,然后使用原始查询词语和这些新词语创建一个新的查询。提交新查询就会返回其他查询结果。所有这些都可以用检索词向量来完成:只需将 termVectors="true" 添加到 schema.xml 中的 <field> 声明。
MoreLikeThisComponent 参数:
参数 |
说明 |
值域 |
mlt |
在查询时,打开/关闭 MoreLikeThisComponent 的布尔值。 |
true|false |
mlt.count |
可选。每一个结果要检索的相似文档数。 |
> 0 |
mlt.fl |
用于创建 MLT 查询的字段。 |
任何被储存的或含有检索词向量的字段。 |
mlt.maxqt |
可选。查询词语的最大数量。由于长文档可能会有很多关键词语,这样 MLT 查询可能会很大,从而导致反应缓慢或可怕的 TooManyClausesException,该参数只保留关键的词语。 |
> 0 |
要想使用匹配相似首先在 solrconfig.xml 中配置 MoreLikeThisHandler

<requestHandler name="/mlt" class="solr.MoreLikeThisHandler"></requestHandler> |
然后我就可以请求
http://localhost:8983/skyCore/mlt?q=id%3A6F398CCD-2DE0-D3B1-9DD6-D4E532FFC531&mlt.true&mlt.fl=content&wt=xml&indent=true
上面请求的意思查找 id 为 6F398CCD-2DE0-D3B1-9DD6-D4E532FFC531 的 document ,然后返回与此 document 在 name 字段上相似的其他 document。需要注意的是 mlt.fl 中的 field 的 termVector=true 才有效果
<field name="content" type="text_smartcn" indexed="false" stored="true" multiValued="false" termVector="true"/> |
使用SolrJ时也同样加入参数就可以
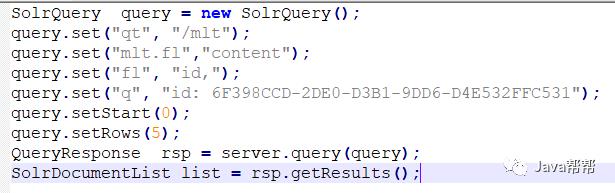
SolrQuery query = new SolrQuery(); query.set("qt", "/mlt"); query.set("mlt.fl","content"); query.set("fl", "id,"); query.set("q", "id: 6F398CCD-2DE0-D3B1-9DD6-D4E532FFC531"); query.setStart(0); query.setRows(5); QueryResponse rsp = server.query(query); SolrDocumentList list = rsp.getResults(); |
6.9拼音检索
拼音检索中国人的专用检索,例如:中文内容为 中国 的输入zhongguo、zg、zhonggu 全拼、简拼、拼音的相邻的一部份都应该能检索出 中国 来。
想要实现拼音检索第一个就是拼音转换我这里用的是pinyin4j进行拼音转换。第二个就是N-Gram的题目,推敲到用户可能输入的既不是前缀也不是后缀,所以此处选择的是N-Gram技巧,但不同于常用的N-Gram,我应用的从一边开端的单向的N-Gram,Solr里的实现叫EdgeNGramTokenFilter,但是分的分的太细了,不需要这么复杂EdgeNGramTokenFilter,也就是说我们用的N-Gram不同于传统的N-Gram。
同样的例子使用EdgeNGramTokenFilter从前往后取2-Gram的结果是zh, 一般是取min–max之间的所有gram,所以使用EdgeNGramTokenFilter取2-20的gram结果就是zh,zho, zhon, zhong, zhongg, zhonggu, zhongguo, 从这个例子也不难理解为什么我要选择使用EdgeNGramTokenFilter而非一般意义上的N-Gram, 考虑到用户可能输入的不是前缀而是后缀,所以为了照顾这些用户,我选择了从前往后和从后往前使用了两次EdgeNGramTokenFilter,这样不只是前缀、后缀,二十任意的字串都考虑进去了,所以大幅度的提高了搜索体验.
现在思路明确了我们把它结合到Solr中,为了方便使用现在写了两个Filter进行处理拼音分词问题一个是拼音转换Filter(PinyinTransformTokenFilter)一个是拼音N-Gram的Filter(PinyinNGramTokenFilter),这样一来使用时就不用在添加索引前做拦音的转换了。而且PinyinTransformTokenFilter还有个好处就是它只使用中文分词器分过的词,也就是说做转换的词都是有用的不重复的,不会对没用的停词类的做拼音转换和重复拼音转换,这样大大的提高了拼音转换速度。
想要Solr支持拼音检索就要先把拼音分词(PinyinAnalyzer)的jar复制到\solr\contrib\analysis-extras\lib下,然后在schema.xml中配置一个拼音字段类型:
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/> <filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/> <filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" /> <filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" /> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/> <filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/> <filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" /> <filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" /> </analyzer> </fieldType> |
minTermLenght:最小中文词长度,意思是小于这个值的中文词不会做拼音转换。
minGram:最小拼音切分长度。
如果想使用简拼的话在拼音转换Filter 使用这个参数isFirstChar="true"就可以了
在这个拼音类型中我们使用了smartcn的中言语分词器,如果想使用其它的自己换掉就行了。现在我们在原来索引中加入一个拼音字段,因为只做索引,我们可以这样配置:
<field name ="pinyin" type ="text_pinyin" indexed ="true" stored ="false" multiValued ="false"/> |
加完后我们重新启动Solr测试一下看看
由于上面minTermLenght和minGram设置的值,现在出现了人没有进行拼音转换并且最小拼音切分是从1个开始的。
到这里我们的配置还有没完成呢,还要加几个copyFiled,这样就不用单独处理我们新加的拼音字段了。方便呀~~~
<copyField source="content" dest="pinyin"/> <copyField source="text" dest="spell"/> |
到现在就可以使用拼音检索了。
拼音分词器jar 点击并复制就可以粘出去了.
6.10 SolrCloud
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,是正在开发中的Solr4.0的核心组件之一,它的主要思想是使用Zookeeper作为集群的配置信息中心。它有几个特色功能,集中式的配置信息、自动容错 、近实时搜索 、查询时自动负载均衡。
基本可以用上面这幅图来概述,这是一个拥有4个Solr节点的集群,索引分布在两个Shard里面,每个Shard包含两个Solr节点,一个是Leader节点,一个是Replica节点,此外集群中有一个负责维护集群状态信息的Overseer节点,它是一个总控制器。集群的所有状态信息都放在Zookeeper集群中统一维护。从图中还可以看到,任何一个节点都可以接收索引更新的请求,然后再将这个请求转发到文档所应该属于的那个Shard的Leader节点,Leader节点更新结束完成,最后将版本号和文档转发给同属于一个Shard的replicas节点。这里就不多说SolrCloud了,等研究明白后再单写一个文档
以上是关于solr使用教程二面试+工作的主要内容,如果未能解决你的问题,请参考以下文章