solr安装,配置和后台管理
Posted 我好困啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了solr安装,配置和后台管理相关的知识,希望对你有一定的参考价值。
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
1.solr的安装
a.解压solr压缩包,将在dist中的solr的war文件夹拷贝到本地tomcat的webapps中,启动tomcat进行解压。
解压成功后,停掉tomcat
b. 将解压后的solr包,将solr中的example/lib/ext中的jar包拷贝到刚刚解压好的tomcat中的solr的WEB-INF中的lib中
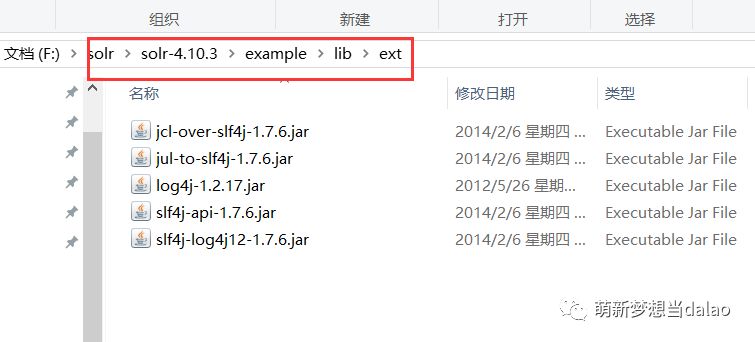
以下目录中
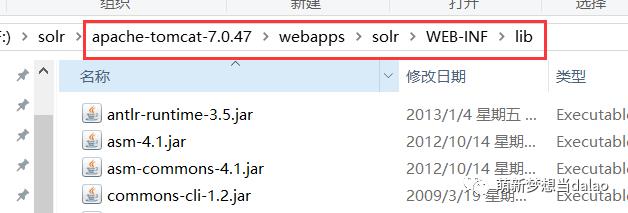
c .配置solrhome
随便在一个文件夹中创建solrhome文件夹,这里我放到tomcat的同一目录的
再将solr中的example/solr中的内核(以下文件)
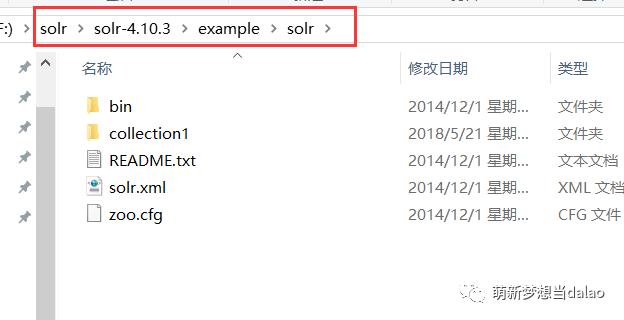
拷贝到刚刚创建的文件夹中
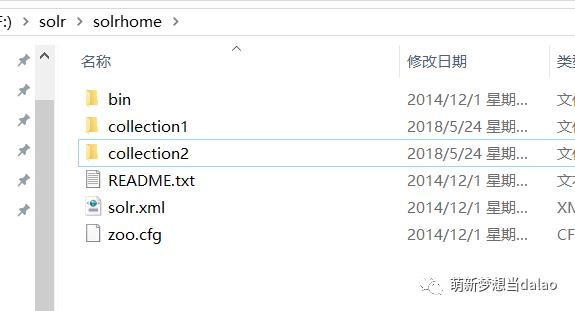
在tomcat中的solr中的WEB-INF下的web.xml中修改如下,进行solrhome的配置
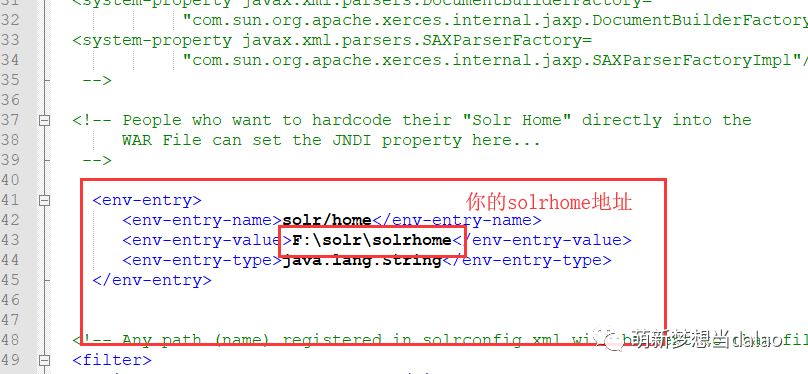
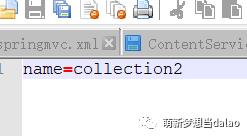
注:这里需要配置多个内核的话,请将collection拷贝一份,改名核二,然后修改collection中的core.properties文件的name为你改名的核名
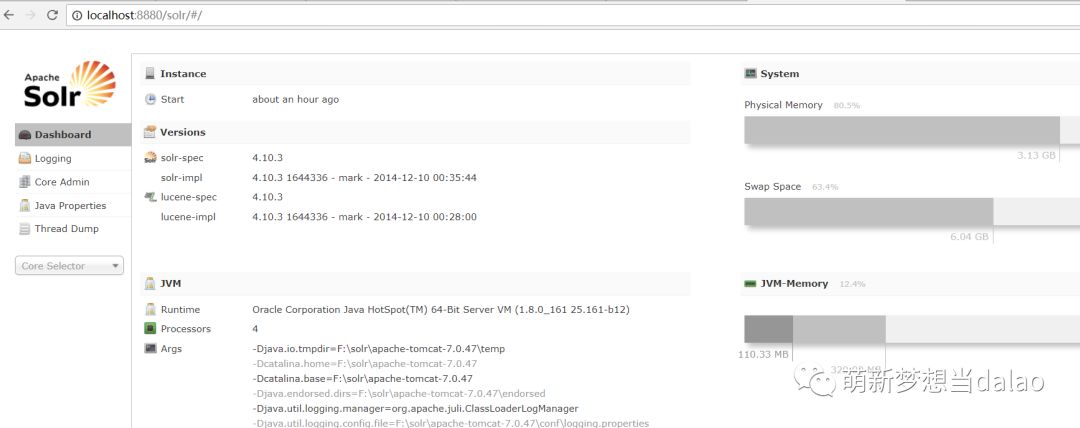
重启tomcat,打开浏览器,输入localhost:8080/solr就可以进入solr的控制界面
2.中文分词器,solr配置IK分词器
下载IK分词器,解压,如下:
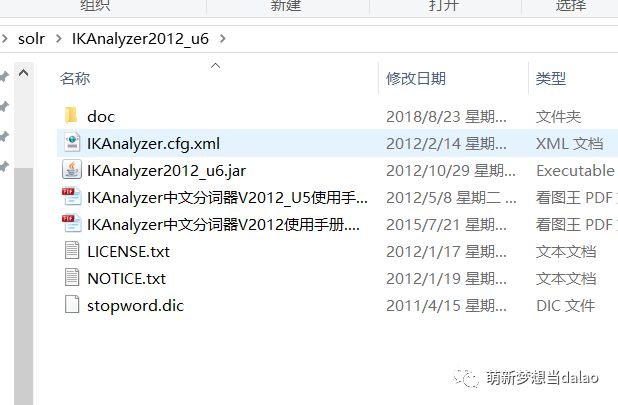
将其中的IKAnalyzer2012_u6.jar包,拷贝到tomcat中的solr项目中的lib中
再将如图的两个文件
拷贝到如图目录下(即项目的classpath下),并创建文件ext.dic
注:这里的核心配置文件是IKAnalyzer.cfg.xml,打开该文件,(ps:解开ext.dic的注解)可以看到
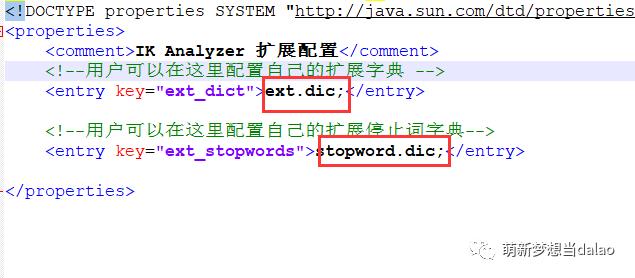 该配置表示可以通过ext.dic和stopword.dic进行自定义中文词汇的加入。
该配置表示可以通过ext.dic和stopword.dic进行自定义中文词汇的加入。
比如在ext.dic中添加词汇:高富帅,那么他就会将高富帅看此一个词汇,不会再将其分割。
stopword.dic:停止扩展名,一般放入:是 词汇,
比如:添加是
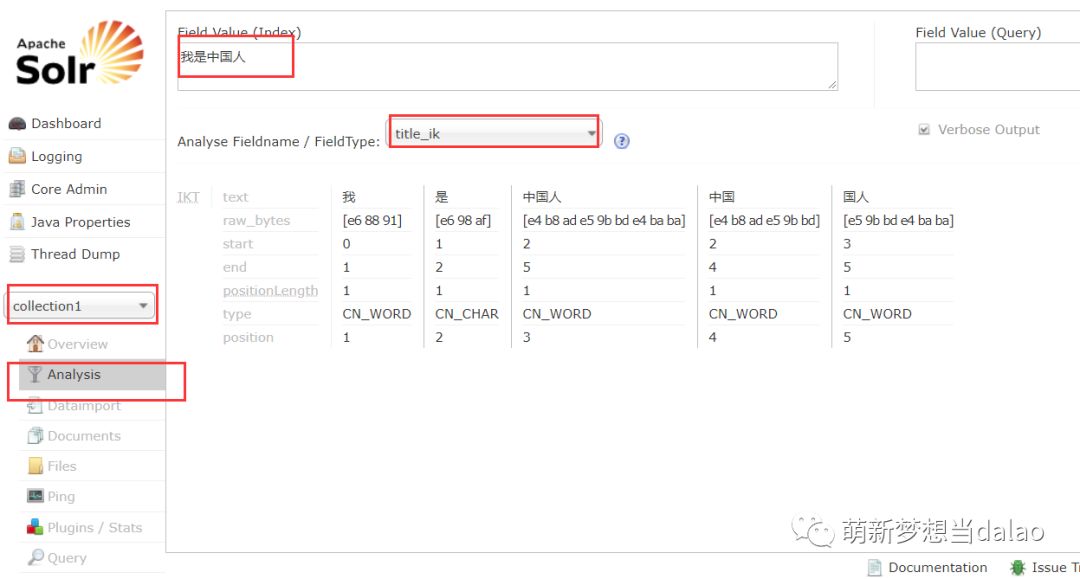
分词:我是中国人
结果:我 中国人 中国 国人
是会被剔除词汇
最后,找到核一,在如图目录下,修改schema.xml文件,将该分词器添加进去
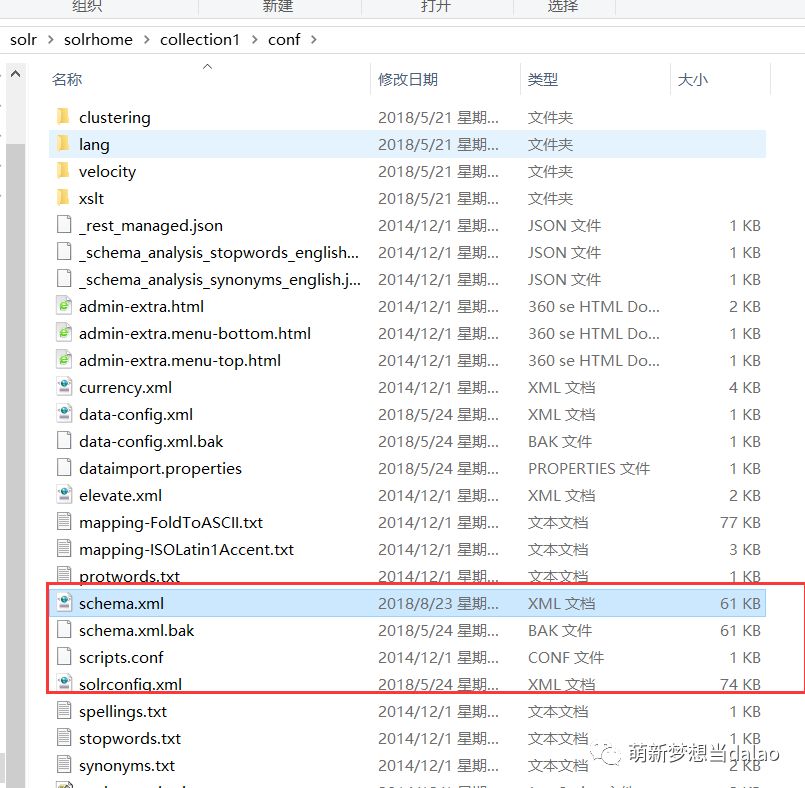
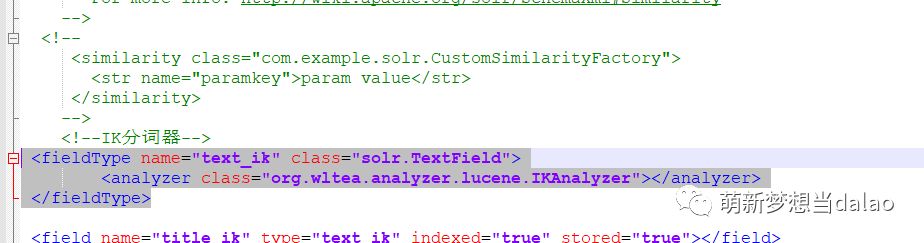
在其中添加上该配置
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"></analyzer>
</fieldType>
重启tomcat,打开浏览器,来看看效果,选择配置的ik分词器,text_ik字段
分词:我是中国人:
3.solr中的配置域的某些字段解释
我们要配置一个域,首先需要在schema.xml文件中进行配置
比如配置一个简单字段,将数据库中的anime_name字段进行域的配置,
基本域
<field name="anime_name" type="text_ik" indexed="true" stored="true"></field>
简单说明一下,域,相当于数据库中的一个字段,name表示域名,type表示类别,此类型必须是在该文件下配置过才能使用,比如,上面配置的IK分词器,就是配置了text_ik这个类型字段。其中默认的配置了我们常用的类型字段

这些常用字段都已经配置好了的
indexed:是否索引,设置为true,那么用户可以通过域名:field进行搜索出该字段,设置为false,那么不可以根据anime_name进行搜索,只能通过其他方法查找出来。
stored,是否储存,比如复制域,只处理逻辑,不储存
required,是否必须,相当于数据库中的非空字段
multiValued:是否多值
复制域:
即组合域,将几个域合并起来,成为一个逻辑域
比如;需求查询一个字段又要在anime_name和anime_title中分别进匹配,那么我们可以将配置的anime_name和anime_title域进行合并成一个复制域(逻辑域)
这里有两个基本域:
<field name="anime_name" type="text_ik" indexed="true" stored="true"></field>
<field name="anime_title" type="text_ik" indexed="true" stored="true"></field>
那么将这两个域组合成一个逻辑域
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true" />
<copyField source="anime_name" dest="item_keywords"></copyField>
<copyField source="anime_title" dest="item_keywords"></copyField>
动态域
配置动态生成某个字段,比如某些字段不能固定式,可以动态生成,如:anime_name,anime_title,查询字段不固定时,你也不知道会生成哪一个,就可以根据前缀+_*进行匹配
<dynamicField name="anime_*" type="string" indexed="true" stored="true"/>
这个配置就是动态生成anime开头的字段
4.solr后台数据的增删改查操作
添加
如图:
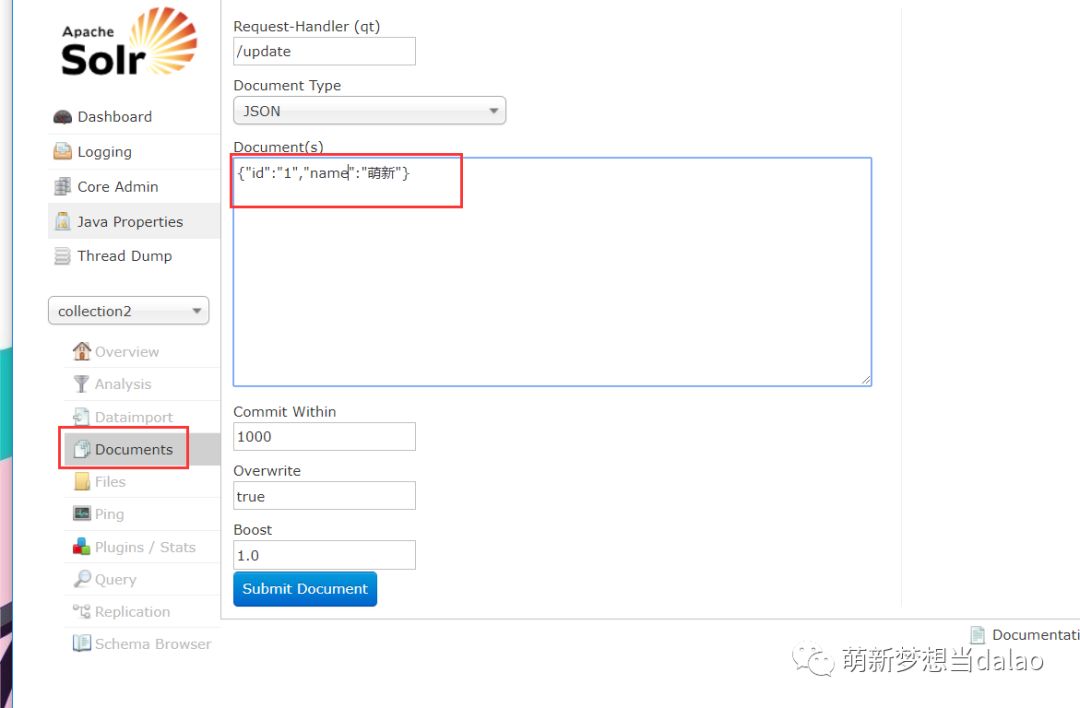
查询结果
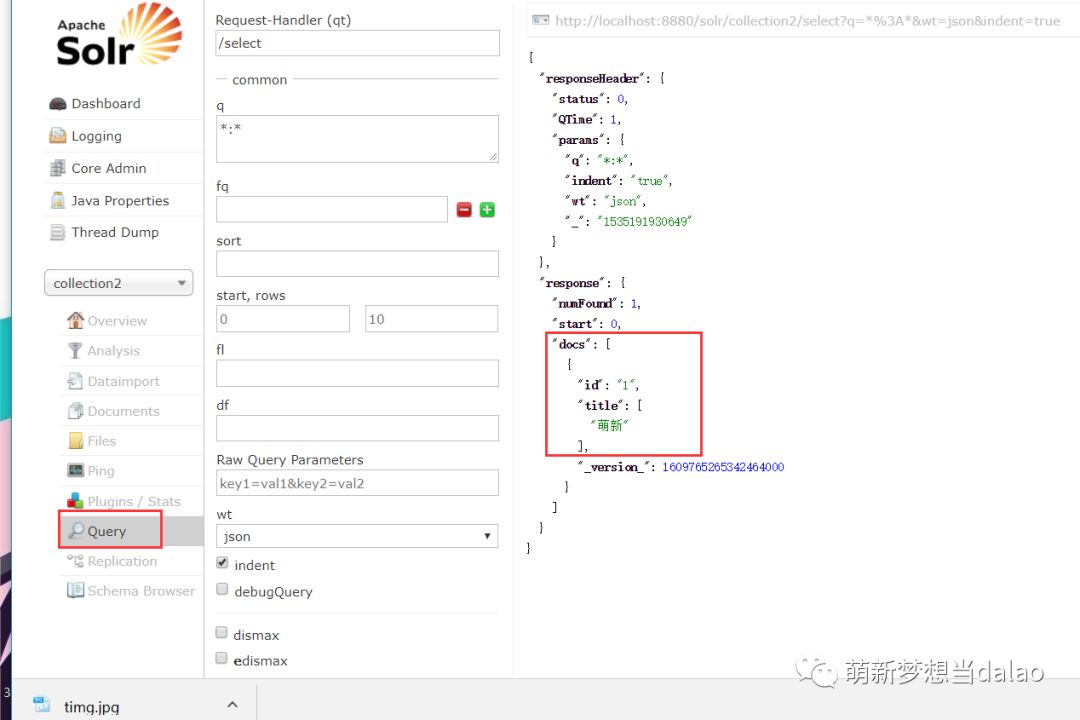
可以看到数据插入进去了
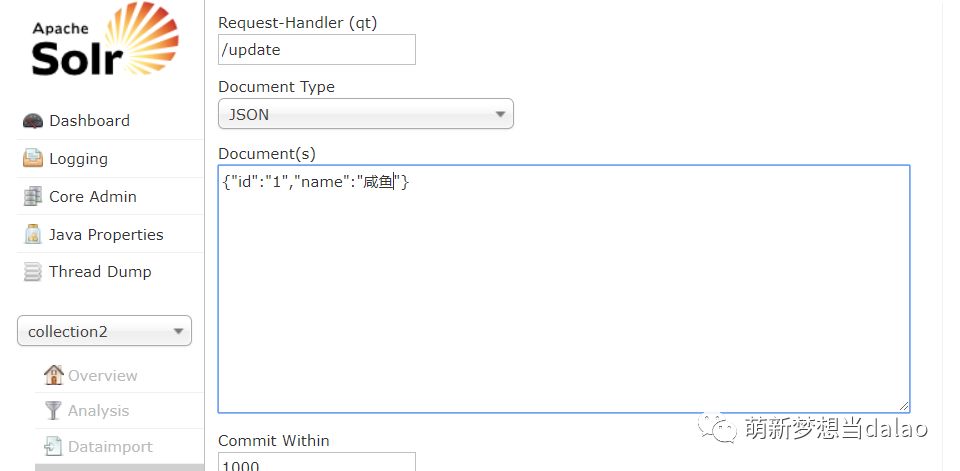
修改:(由于solr的底层为Lucene,修改操作为先删除再添加)
修改和添加一样,只需要将id为要修改文档的id进行添加即可
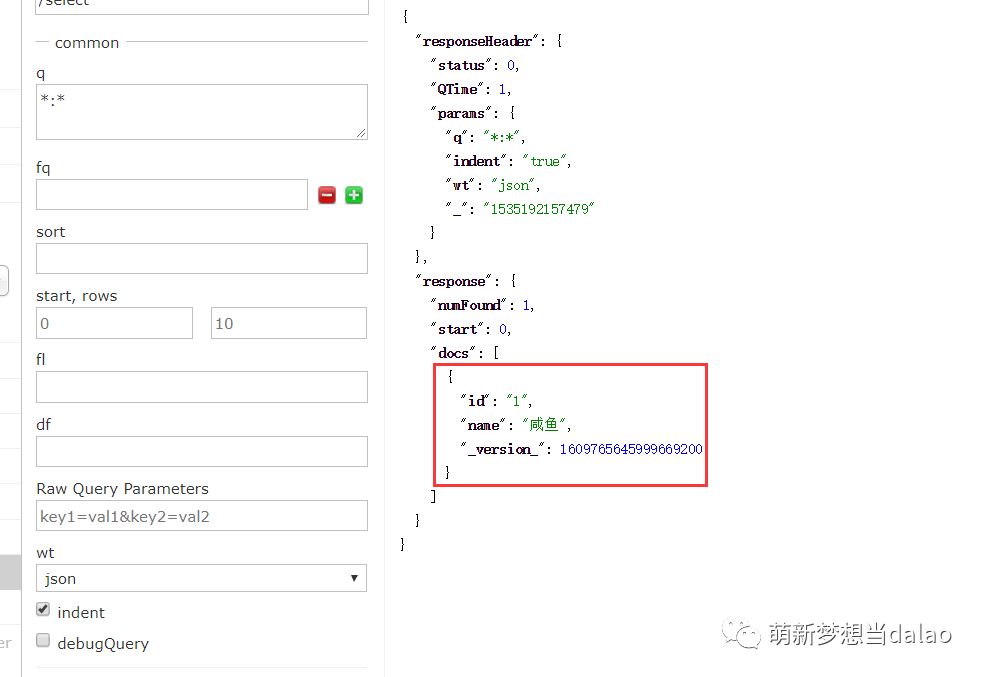
结果:
删除:
删除id为1的
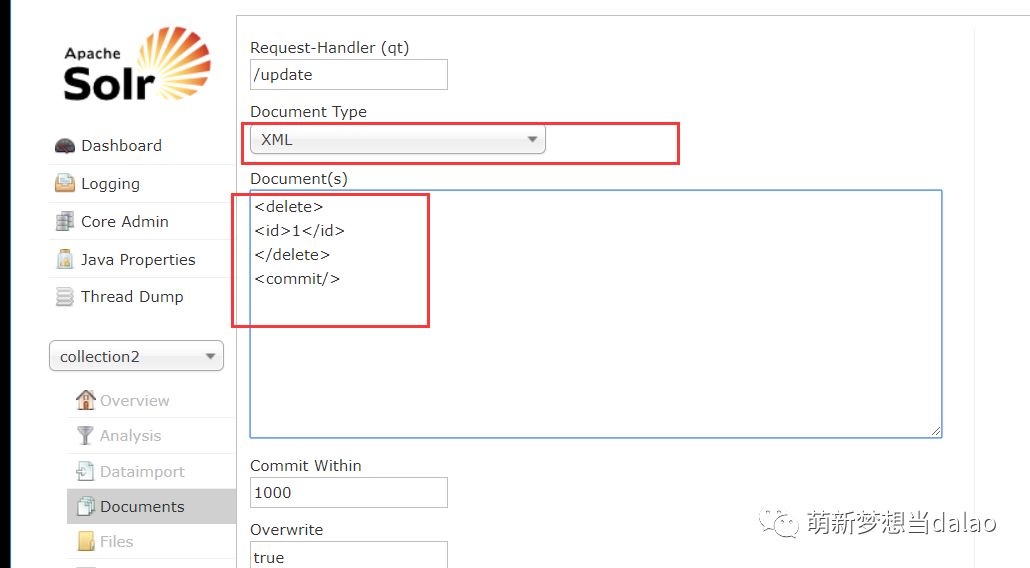
语法删除:
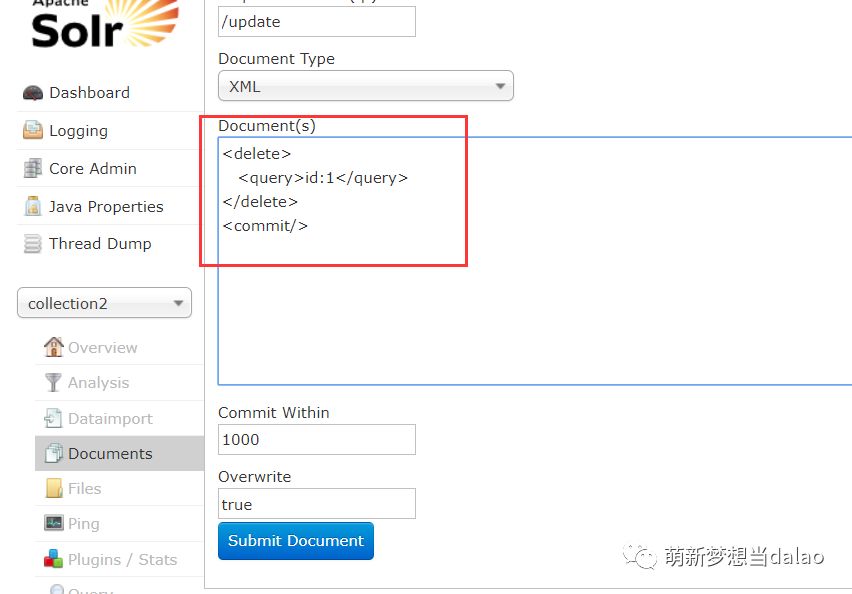
这种删除方法可以自定义语法,如删除所有*:*
查询:
(1).查询所有(这是默认的)
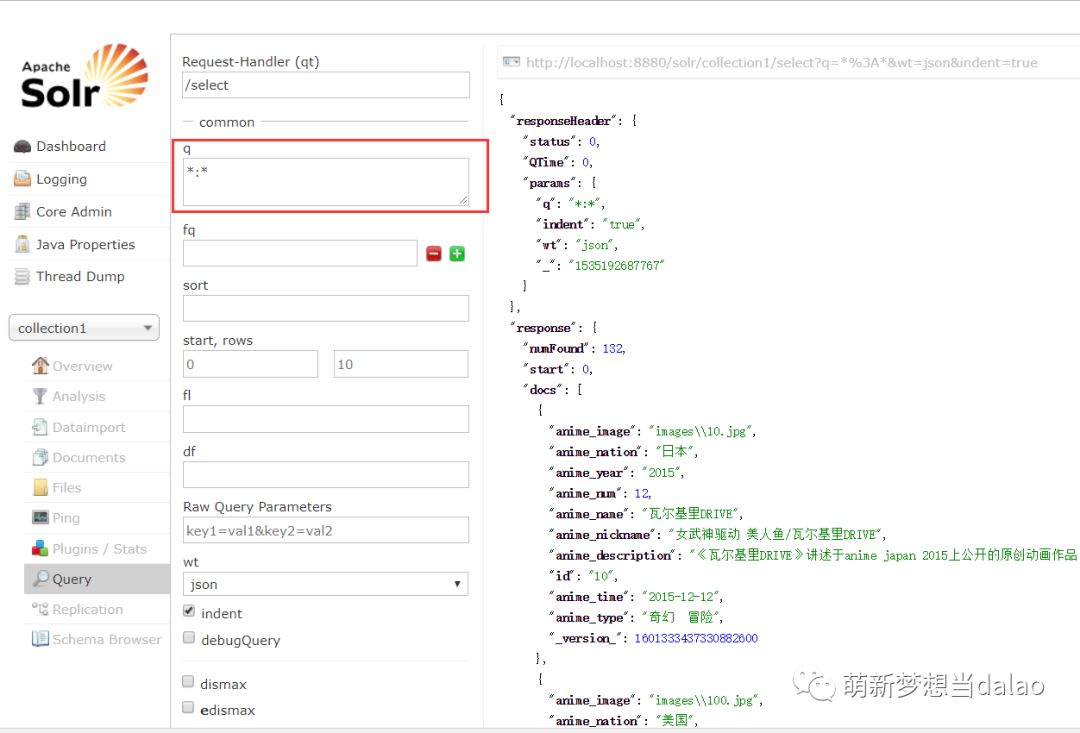
(2).指定字段查询
如:查询anime_description中的含有 伙伴 字段的,查询到10条
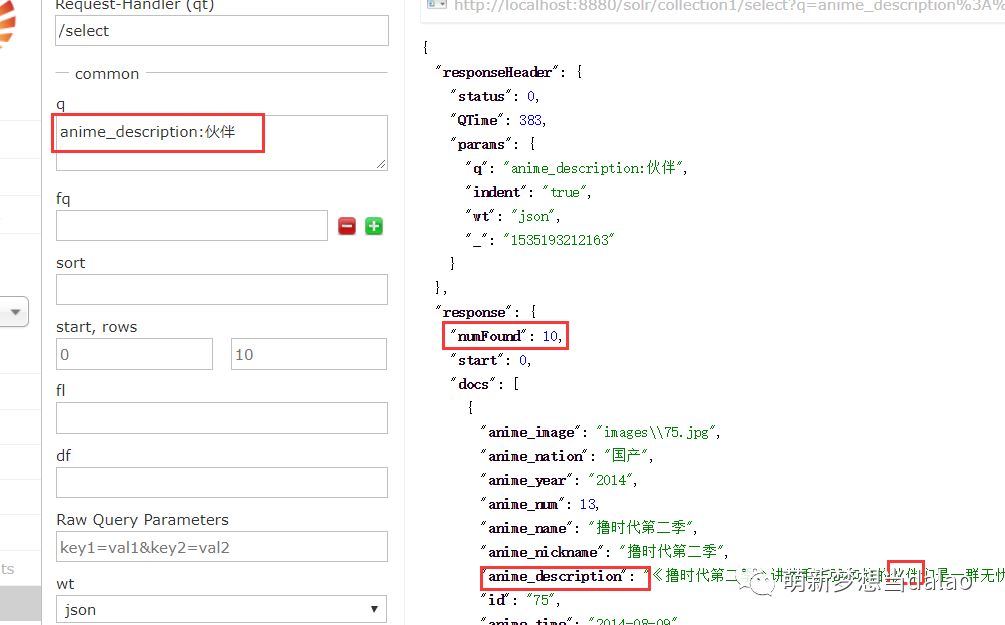
(3)过滤条件查询
如:将anime_description包含伙伴和anime_nation为日本的查出来
添加过滤条件anime_nation:日本,可以看到数据为5条了
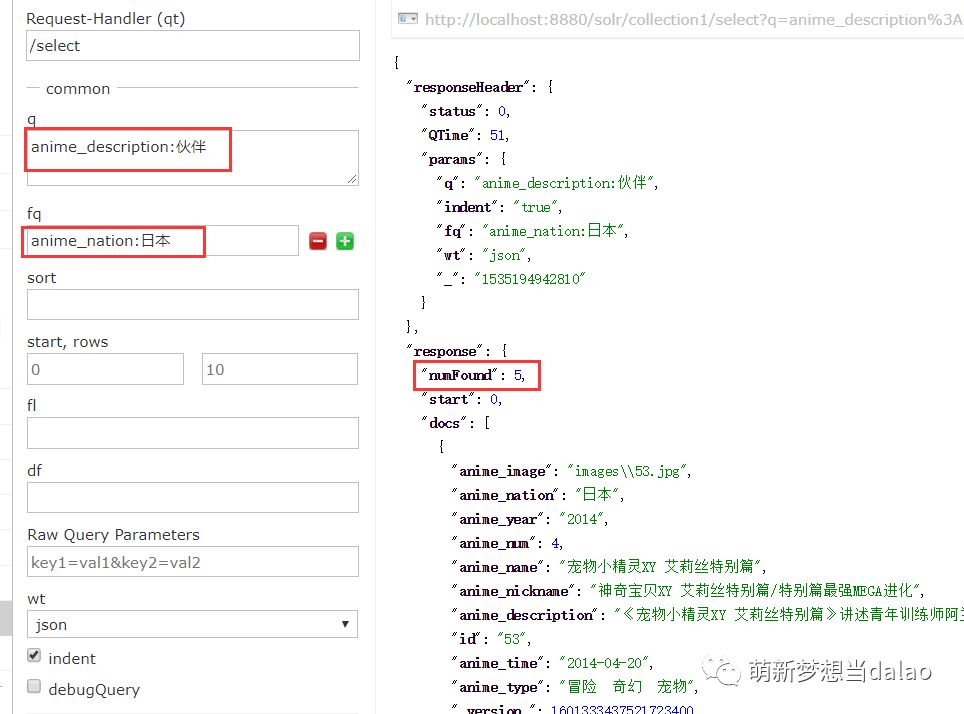
(4).范围查询
查询anime_num为[12-24]的字段
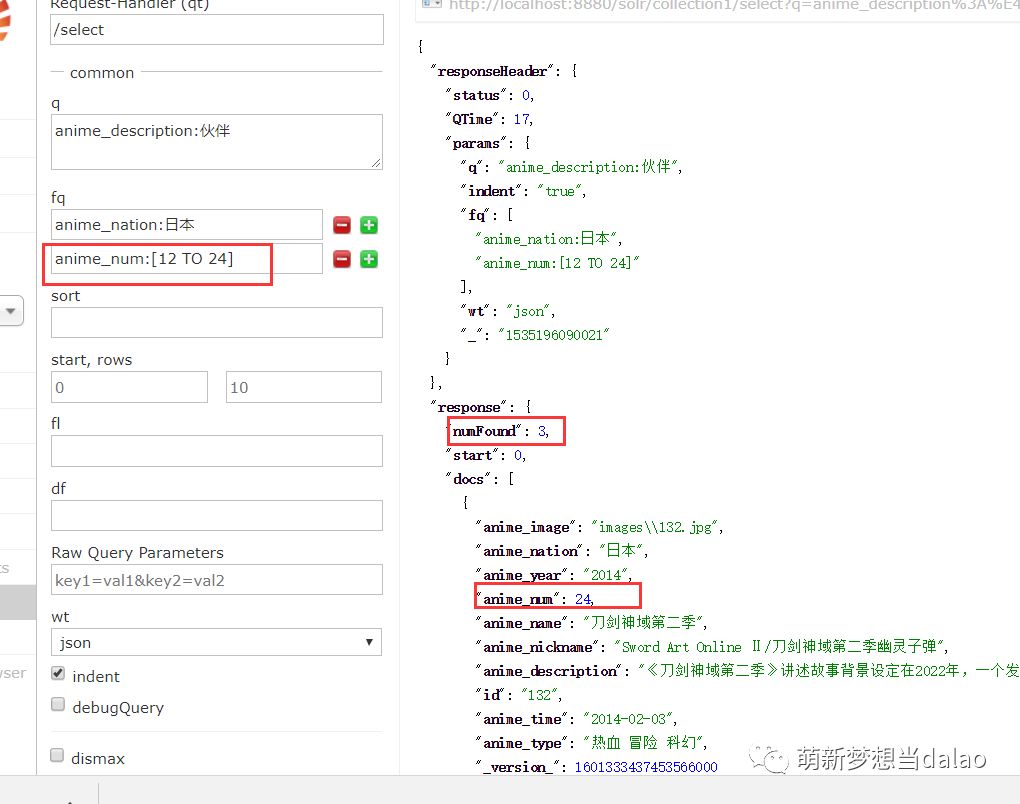
可以看到数据变为3条,集数在12-24的查出来了
(5).排序
按照anime_num进行倒序排序
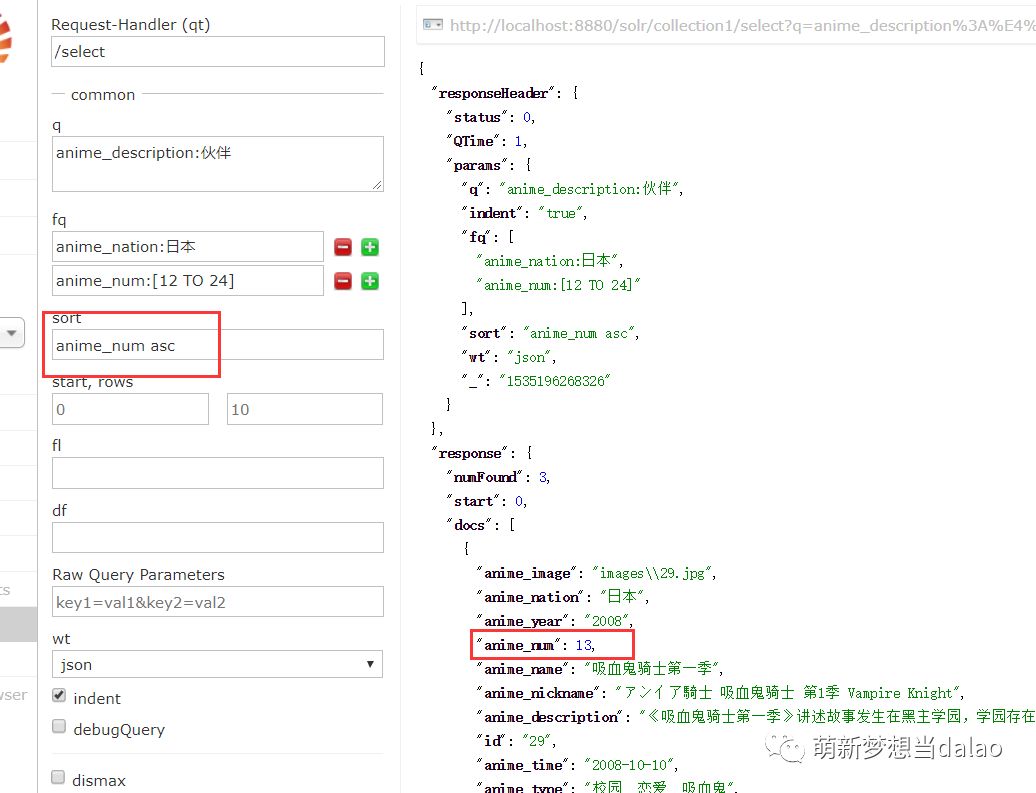
(6).指定结果数

第一个参数为开始下标,第二个表示查询条数
(7).指定搜索字段查询
如:只查询id和anime_name

结果:

(8).高亮
如下,开启高亮,将anime_description域,查询的字段用高亮显示
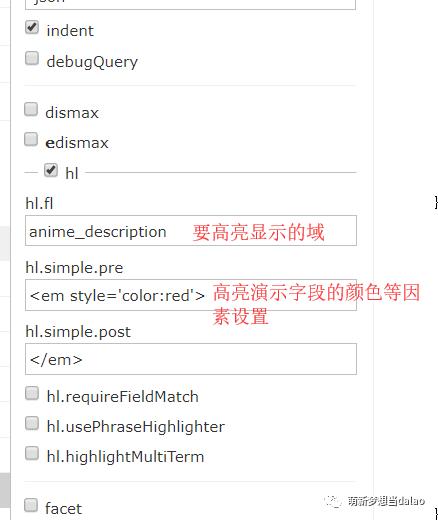
高亮显示:伙伴,查询结果

以上是solr后台数据操作的一些基本操作.
5.批量数据导入
首先将导入数据依赖的jar包放入到核一中
在解压的solr文件中的如图的两个jar包,copy
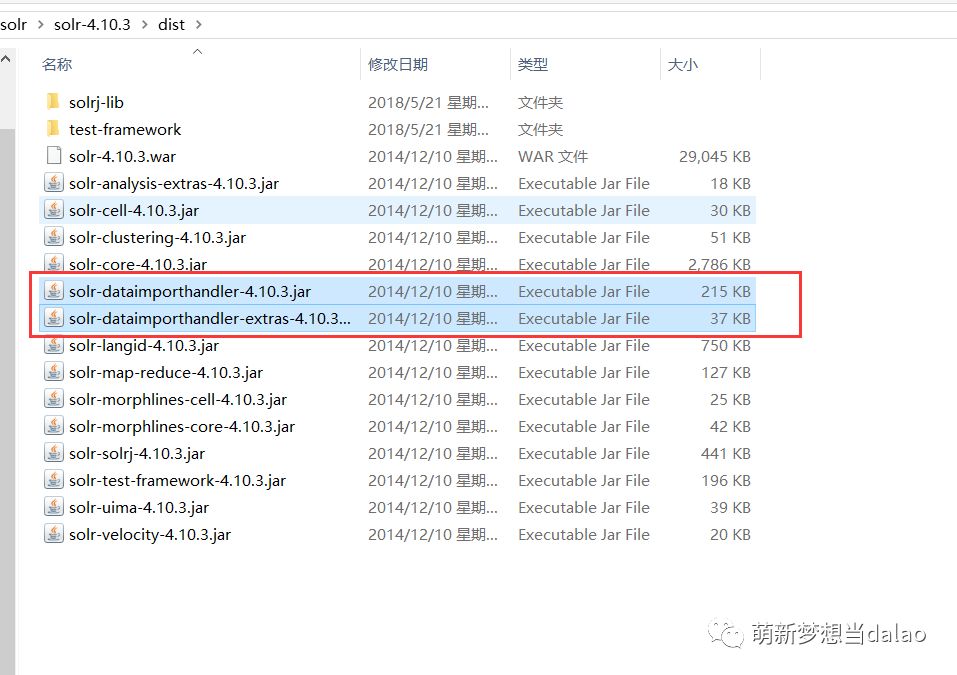
到solrhome/collection/lib,再将mysql数据库连接的驱动放入进去
修改核一中的solrconfig.xml
添加导入数据的requestHandler:dataimport,如下代码

接下来配置data-config.xml(注:如果只写data-config.xml路径,则只能放在同级目录下)
在同级目录下创建data-config.xml
解释如图,连接数据库,进行表匹配进行导入
重启tomcat,打开浏览器进行如下导入
这样数据就导入到数据库中了
5.springDataSolr的使用
以上是关于solr安装,配置和后台管理的主要内容,如果未能解决你的问题,请参考以下文章