Mysql数据导入SolrCloud
Posted 大数据实战演练
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql数据导入SolrCloud相关的知识,希望对你有一定的参考价值。
Solr主要是做数据搜索的,那么Solr的数据是从哪里来的呢?总不能一条一条的插入吧。Solr也有这方面的考虑,比如配置Dataimport将mysql数据批量导入Solr中。
环境说明:
ambari v2.6.1
SolrCloud 5.5.5
我使用的ambari来自动化安装的Solr
一、创建mysql表,并插入数据
创建 test数据库,并执行下列语句
use test;
DROP TABLE IF EXISTS `solr_test_info`;
CREATE TABLE `solr_test_info` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`address` varchar(40) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of solr_test_info
-- ----------------------------
INSERT INTO `solr_test_info` VALUES ('1', '张三', '广东');
INSERT INTO `solr_test_info` VALUES ('2', '李四', '上海');
INSERT INTO `solr_test_info` VALUES ('3', '赵五', '四川');
INSERT INTO `solr_test_info` VALUES ('4', 'tom', '外国');
二、复制jar包
复制三个jar包到Solr指定位置
# 移动solr-dataimporthandler-5.5.5.jar、solr-dataimporthandler-extras-5.5.5.jar、mysql-connector-java.jar到指定目录
cd /usr/lib/ambari-infra-solr/dist
cp -r solr-dataimporthandler-5.5.5.jar solr-dataimporthandler-extras-5.5.5.jar /usr/lib/ambari-infra-solr/server/solr-webapp/webapp/WEB-INF/lib
# mysql-connector-java.jar需要自己下载
cp -r mysql-connector-java.jar /usr/lib/ambari-infra-solr/server/solr-webapp/webapp/WEB-INF/lib
三、创建config set
1. 进入Zookeeper,创建Znode -- collection1
# node96.xdata为主机名
[root@node97 ~]# /usr/hdp/2.6.4.0-91/zookeeper/bin/zkCli.sh -server node96.xdata
[zk: node97.xdata:2181(CONNECTED) 0] create /infra-solr/configs/collection1 null
2. 上传文件到指定Znode -- collection1处
Solr官方提供了一个Zookeeper插件 -- zkcli.sh,使用该工具,可以实现将本地文件上传到zookeeper的Znode上。具体参见链接:使用zkcli.sh来管理SolrCloud配置文件
# 将managed-schema、solrconfig.xml、solr-data-config.xml、elevate.xml上传至指定Znode处
/usr/lib/ambari-infra-solr/server/scripts/cloud-scripts/zkcli.sh -zkhost node96.xdata:2181,node97.xdata:2181,node98.xdata:2181 -cmd putfile /infra-solr/configs/collection1/managed-schema managed-schema
/usr/lib/ambari-infra-solr/server/scripts/cloud-scripts/zkcli.sh -zkhost node96.xdata:2181,node97.xdata:2181,node98.xdata:2181 -cmd putfile /infra-solr/configs/collection1/solrconfig.xml solrconfig.xml
/usr/lib/ambari-infra-solr/server/scripts/cloud-scripts/zkcli.sh -zkhost node96.xdata:2181,node97.xdata:2181,node98.xdata:2181 -cmd putfile /infra-solr/configs/collection1/solr-data-config.xml solr-data-config.xml
/usr/lib/ambari-infra-solr/server/scripts/cloud-scripts/zkcli.sh -zkhost node96.xdata:2181,node97.xdata:2181,node98.xdata:2181 -cmd putfile /infra-solr/configs/collection1/elevate.xml elevate.xml
备注:
上述文件都在 /usr/lib/ambari-infra-solr/example/example-DIH/solr/db/conf目录下;SolrCloud里面也有默认的一组 configset配置组,位置在 Zookeeper的 /infra-solr/configs上面。
核实 solrconfig,xml,确保文件内有下述内容
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">solr-data-config.xml</str>
</lst>
</requestHandler>
其中 solr-data-config.xml需要我们自己定义:
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://node96.xdata:3309/test" user="root" password="root123"/>
<document>
<entity name="solr_test_info"
query="select id, name, address from solr_test_info">
<field column="id" name="id" />
<field column="name" name="name" />
<field column="address" name="address" />
</entity>
</document>
</dataConfig>
说明:
type这是固定值,表示JDBC数据源,后面的driver表示JDBC驱动类,这跟你使用的数据库有关,url即JDBC链接URL,后面的user,password分别表示链接数据库的账号密码,下面的entity映射有点类似hiberante的mapping映射,column即数据库表的列名称,name即schema.xml中定义的域名称。
修改 managed-schema文件,在最后新增:
<!-- id的field在文件内已经存在,就不需要再添加了 -->
<field name="name" type="string" multiValued="false" indexed="true" stored="true"/>
<field name="address" type="string" multiValued="false" indexed="true" stored="true"/>
说明:
name:字段名称
type:类型,分为string、int、long等
indexed:是否构建索引,true:可通过该字段查询到相应的结果;false:该字段不能进行查询
stored:是否存储,true:查询到数据是可以返回此字段;false:该字段不进行存储,即便查询到了结果,也不会返回这个字段
required:是否必填,对应数据库中的not null
multiValued:solr中的一个重要概念,在数据库中没有与之对应的概念。指是否进行多存储,该字段表示能否存储一个list或者数组
四、创建一个Collection
Solr有自己的web UI界面,在ambari平台上面的Solr,有两个Solr web UI,分别是:
http://10.6.6.97:8886/solr/#/ (old UI)
http://10.6.6.97:8886/solr/index.html#/ (new UI)
这里我们使用新UI页面创建Collection。点击 Collections --> Add Collection
参数说明:
name:将被创建的集合的名字
config set:集合使用的配置组,位置在Zookeeper上面。创建集合之前,必须保证zookeeper上面有所选择的config set。
numShards:集合创建时需要创建逻辑碎片的个数
replicationFact:分片的副本数。replicationFactor(复制因子)为 3 意思是每个逻辑碎片将有 3 份副本。
maxShardsPer:默认值为1,每个Solr服务器节点上最大分片数(4.2新增的) 注意三个数值:numShards、replicationFact、liveSolrNode(当前存活的solr节点),一个正常的solrCloud集群不容许同一个liveSolrNode上部署同一个shard的多个replicationFact,因此当maxShardsPer=1时,numShards * replicationFact > liveSolrNode时,报错。因此正确时因满足以下条件:numShards*replicationFact < liveSolrNode * maxShardsPer
为了更直观的说明numShards和replicationFact的意思,请看下图的
collection1和collection3

collection1有三个分片,每个分片就一个副本。也就是numShards=3;replicationFact=1;maxShardsPer=1
collection3有两个分片,每个分片有两个副本。也就是numShards=2;replicationFact=2;maxShardsPer=2
均满足条件:numShards*replicationFact < liveSolrNode * maxShardsPer
五、数据导入
Solr提供了full-import和delta-import两种导入方式。
full-import:
多个entity,每个entity有各自的lastindextime,可以通过dataimporter.entityname.lastindextime来取各自的最后更新时间来进行增量更新。
多个entity时,进行full-import时指明导入某个entity。
delta-import
主要是对于数据库(也可能是文件等等)中增加或者被修改的字段进行导入。主要原理是利用率每次我们进行import的时候在ZooKeeper 对应的config set 配置组下面生成的dataimport.properties`文件,此文件里面有最近一次导入的相关信息。这个文件如下:
#Thu Dec 06 13:03:14 UTC 2018
last_index_time=2018-12-06 13\:03\:14
solr_test_info.last_index_time=2018-12-06 13\:03\:14
lastindextime是最近一次索引(full-import或者delta-import)的时间。
通过比较这个时间和我们数据库表中的timestamp列即可得出哪些是之后修改或者添加的。
选择Solr web UI --> collection1 --> Dataimport,点击 configuration,可以看到 solr-data-config.xml的内容
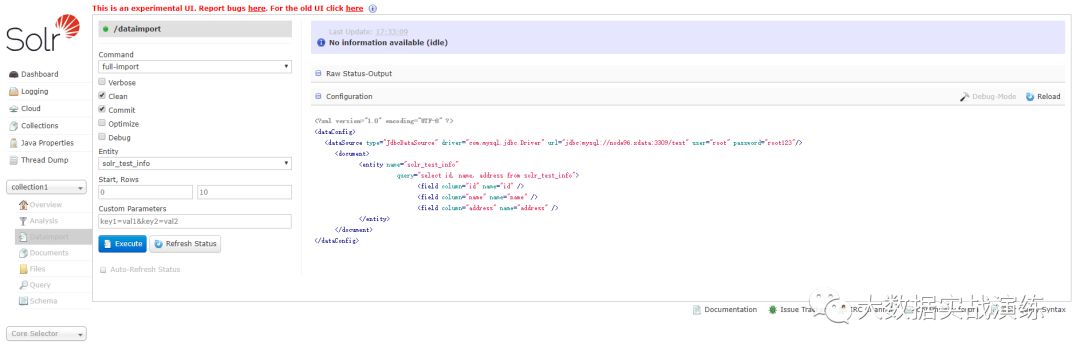
说明
entity
entity是document下面的标签(solr-data-config.xml)。使用这个参数可以有选择的执行一个或多个entity 。使用多个entity参数可以使得多个entity同时运行。如果不选择此参数那么所有的都会被运行。
clean
选择是否要在索引开始构建之前删除之前的索引,默认为true
commit
选择是否在索引完成之后提交。默认为true
optimize
是否在索引完成之后对索引进行优化。默认为true
debug
是否以调试模式运行,适用于交互式开发(interactive development mode)之中。
请注意,如果以调试模式运行,那么默认不会自动提交,请加参数“commit=true”
选择提交方式为:full-import,点击蓝色按钮 Execute,可以选择自动刷新状态。
过一会之后,会出现Indexing completed.的字样,会显示增加/更新了多个文档,如下图所示:
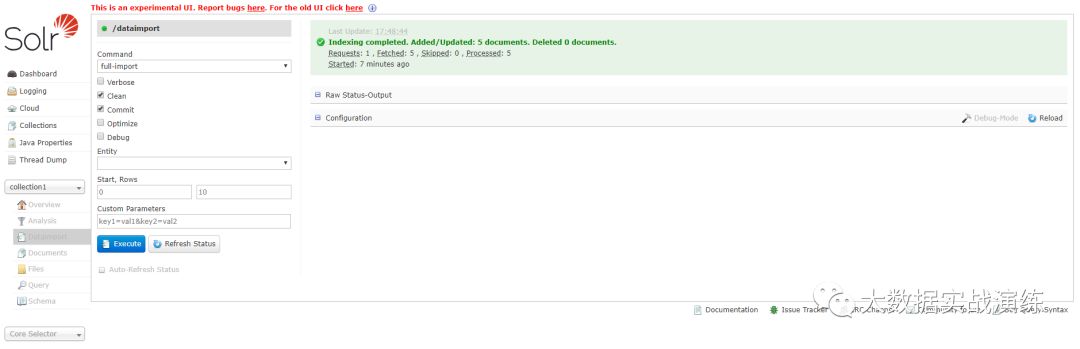
六、数据查询
点击 Query选项,点击页面下方的蓝色按钮 ExecuteQuery,进行全部查询。返回结果如下图所示:
以上是关于Mysql数据导入SolrCloud的主要内容,如果未能解决你的问题,请参考以下文章
使用java代码对zookeeper集群中的solrCloud数据进行CURD
Oracle 数据库 - 使用UEStudio修改dmp文件版本号,解决imp命令恢复的数据库与dmp本地文件版本号不匹配导致的导入失败问题,“ORACLE error 12547”问题处理(代码片段