solr建索引优化
Posted 尧字节
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了solr建索引优化相关的知识,希望对你有一定的参考价值。
这是我 2016 年写的文章,发出来,做索引优化的朋友都可以参考下。
名词解释
Lucene:高性能的全文检索开源的 Java 工具包。
Solr :高性能的利用 java 开发的、开源的,基于 Lucene 的搜索服务器。
非结构化数据:非结构化的没有固定格式的数据,比如一篇文章等。
索引: 利用分词语言处理等手段得到的词与文档 ID 对应关系的数据结构。
全文搜索:利用索引对非结构化数据进行搜索的方法。
文档:类似于数据库的一条记录,由多个字段组成,是建立索引的基础,索引中的分词是对文档中特定分词字段或不分词字段组成。
一.背景介绍
近段时间一直在研究 solr 和 Lucene 相关东西,主要是由于工作需要,需要利用 Solr 来进行日志搜索,但是 Solr 的建索引效率不是很高,难以满足工作中特定日志的性能要求,需要优化其建索引的性能。
性能的具体要求:
1、在一台机器上普通硬盘的情况下,索引单个文档大小为 200 字节左右,需要达到的效率为 5WTPS。
2、具有良好的水平扩展性。
3、对数据备份和数据丢失情况,要求不严格。
对于以上的性能要求,设计出合理的架构,并建议验证实践。本文没有多少高深的技术,我也是个 solr 和 Lucene 的初学者,只是一个总结,希望起到抛砖引玉的作用。
二.关于 Solr 建索引优化
2.1 基本说明
Solr 是基于 Lucene 开发的,外层封装成 Servlet 形式,运行在 Java 的 Web 容器之中,提供索引分片、多副本等功能,并提供基于 HTTP 的 API,方便调用。
Solr 的部署有单节点、Master-Salve 模式、SolrCloud 方式。SolrCloud 具有良好的水平扩展性、自动容错性、自动负载均衡等特性,所以这次采用 solrColud 的方式进行索引的优化。
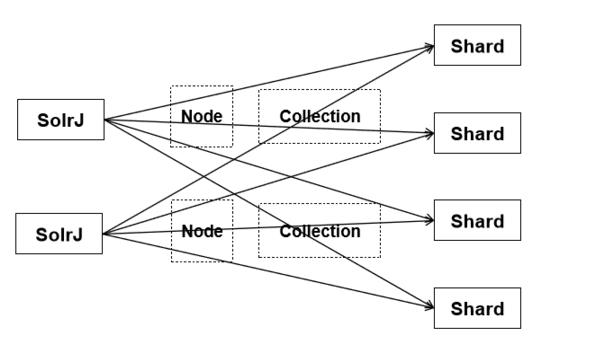
SolrCloud 中完整的索引为 Collection,这是一个逻辑概念,一个 Collection 由多个 shard 组成,shard 同样为逻辑概念,一个 shard 下面分为多个副本,每份基本相同, 其中一份被选举为 Leader,在建索引的时候通过 Leader 来新建索引。用图表示如下:
注:1、红色字体为 Leader,只是个示意,实际上 Leader 是通过选举算法选取出来的。2、Collection 的数据由 shard1 和 shard2 组成,每个 shard 的数据有两份,Collection_shard1_core1 和 Collection_shard1_core2,不同的版本名称可能有差异,对应是一个文件夹,里面保存的是索引的数据。
2.2 建索引的过程
为优化 SolrColud 的创建索引的效率,有必要对整个建索引的流程有所了解,建索引的流程如下, 下面描述的建索引过程主要是最常见的通过 SolrJ 方式创建索引,不是采用 DIH 方式创建索引。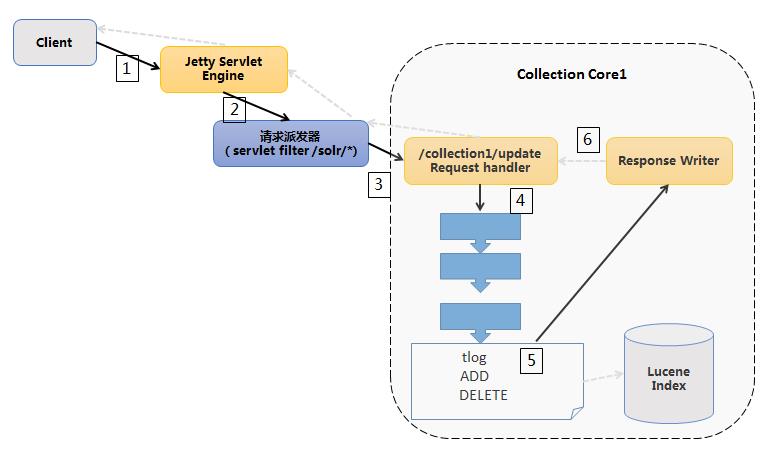
简单说明:
1、客户端发送 HTTP 的 POST 请求到 Solr 服务器,报文格式一般有 xml、json、javabin(只有 java 才支持,二进制结构)。
2、Web 服务器将请求派发到 Solr 的 Web 应用程序Servlet。
3、Solr 根据请求的 URI 中的 Collection 名字在 solrConfig.xml 找到注册的/update 消息处理器;这是单个副本的情况下,如果多个副本的情况下,如果需要判断此副本是否为 Leader,如果是非 Leader,则需要将此文档发送给此副本的 Leader,如果是非直接路由模式,Solr 则会根据文档 ID 进行 hash 路由,路由到特定的 Leader 上。
4、按照 solrConfig.xml 配置的请求处理链来处理索引,比如分词处理器等。
5、写事务日志,当发送提交后正式将数据写入到存储(初始写入是内存,最后通过硬提交写入磁盘)中。
6、返回写索引的结果。
2.3 优化部分
如果从整体考虑,可以考虑 JVM 调优,通过优化 Web 服务器性能,通过程序和配置等其他方面来建索引。目前通过 JVM 简单的调优和 Web 服务器优化,没有怎么研究,简单的试了下,性能改进不是很大。本文主要考虑程序和其他方面配置方面优化。
2.3.1 报文批量大小优化
首先考虑到我们的建索引是通过 HTTP 请求发送的,所以在网络速度固定的情况下,可以通过优化报文大小来提高性能。目前 SolrJ 的接口可以通过 XMl、Javabin 的方式来建索引,Javabin 方式只有 Java 程序可以用,是一种特殊格式,在默认情况下使用 Javabin 方式的报文长度会比 XML 或 JSON 的格式要短,经过测试有部分性能。
对于 HTTP 请求,我们可以通过控制批次大小,一次发送的合适报文批量大小来进行优化,通过实践,目前 200 个字节左右,发送批量为 1W 左右性能较高。
2.3.2 路由模式优化
我们注意到在 Solr 建索引的时候,判断文档属于哪个 shard,需要通过文档 ID 经过 hash 算法,每个文档都要判断一次,这对于性能来说,是不利的,
这种网络上也有朋友提倡通过直接路由的模式来进行建索引。需要注意的是:1) 索引要特殊方式通过以下 URL 新建:
http://ip:port/solr/admin/collections?action=CREATE&name=implicit1&shards=shard1,shard2,shard3&router.name=implicit
-
在 solr4.x 版本中通过更改 schemal.xml 在 5.x 更改 managed-schema 文件添加以下字段定义:
<field name="_route_" type="string"/>
-
在 solrJ 添加文档的时候需要加入以下字段:
doc.addField("_route_","shard_x")
后面的 shard_x 要替换为具体的 shard,比如 shard1 或 shard2 等。通过直接路由模式,多线程的方式,在 solr6.0 版本的情况下,报文 200 个字节左右情况下,单节点的处理效率可以达到 2.5WTPS,比 solr4.9 的单节点 1W 左右 TPS 有较大的提升。另外在测试中发现,报文大小在 200 个字节到 1k 字节之间对 TPS 的影响比较大,当然吞吐量在报文更大的时候会有更好效果。
注意:1、通过这种方式建索引一定要采用多线程同时发送到多个 shard 中去,在 SolrJ 中采用 HttpSolrServer(在 5.x 以后好像已经更改为 HttpSolrClient) 方式进行发送。
2、如果采用默认的路由模式采用的是 CloudSolrServer 进行发送,CloudSolrServer 内部有负载均衡。3、采用直接路由的模式,如果其中一个 shard 所归属的节点挂掉的话,可能造成数据的丢失。CloudSolrServer 可以通过 zookeeper 上的 clusterstate.json 信息得到具体的 shard 的 leader 的具体 url,直接将 updateRequest 提交给它,不用经过 replica 转发;另外还可以通过随时监听节点的状态变化,来保证可靠性,所以在性能准许的情况下还是不要采用直接路由的模式。
2.3.3 参数调整优化
solrconfig.xml 参数优化调整:
<ramBufferSizeMB>100</ramBufferSizeMB>
<maxBufferedDocs>1000</maxBufferedDocs>
以上两个参数为建索引的默认值,表示达到这个值的时候,才会将索引刷新到磁盘中去,可以适当调整测试。
更改建索引线程数:
<maxIndexingThreads>16</maxIndexingThreads>
这个为建索引的线程数,目前在 4.x 版本中存在,6.0 版本未发现此配置,建议设置为 2*cpuNum,默认为 8 个。更改合并段参数参数:
<mergeFactor>10</mergeFactor>
索引的存储是按照段为单位的,这个参数决定了多少个段的时候,进行段合并。如果设置的大,则建索引的速度快,但是会导致索引文件多,查询速度慢;相反,如果设置小,则合并段的频率高,加快查询速度,降低了建立索引的速度。
提交方式的优化:
<autoCommit>
<maxTime>${solr.autoCommit.maxTime:150000}</maxTime>
<maxDocs>50000</maxDocs>
<openSearcher>true</openSearcher>
</autoCommit>
自动提交是指在有文档添加的情况下,经过特定的时间间隔或者添加了特定文档数后进行索引的自动提交,设置了自动提交可以在 SolrJ 的代码中不同提交,由于有更新日志的存在,即使在 solr 服务器出现问题的时候,仍然可以在重启 solr 服务器的时候自动恢复索引数据。
另外参数 openSearcher 表示提交完成后是否重新打开搜索器,打开的会让索引可见。
注意:自动提交和打开搜索器都是很消耗时间的操作,设置自动提交的文档数量过大的情况下,可能造成建索引的速率产生较大的浮动;
自动调整在多并发的时候可以防止打开多个搜索器的问题。
<autoSoftCommit>
<maxTime>${solr.autoSoftCommit.maxTime:60000}</maxTime>
</autoSoftCommit>
自动软提交,软提交不将索引刷新到存储,所以速率相对比较快,软提交可以让索引立刻可见,故此在要求索引近实时的情况下,可以设置软提交。
注意如果在自动提交的情况下打开了搜索器,而且延迟时间可以接受的情况下,可以不使用自动软提交。
三. 结合 Lucene 创建索引
3.1 基本思路
从底层来说,Solr 利用的 Lucene 来进行创建索引的,所以在高版本的 Solr 中,只要是相同版本的 Solr 和 Lucene 用的索引文件是兼容的,solrconfig.xml 有使用 Lucene 的版本信息。所以提出一种方案,是否可以通过 Lucene 直接在 Solr 的目录中创建索引,这样就可以减少网络的开销和 HTTP 服务的开销,直接写本地文件效率肯定是更高的。设想如下图所示: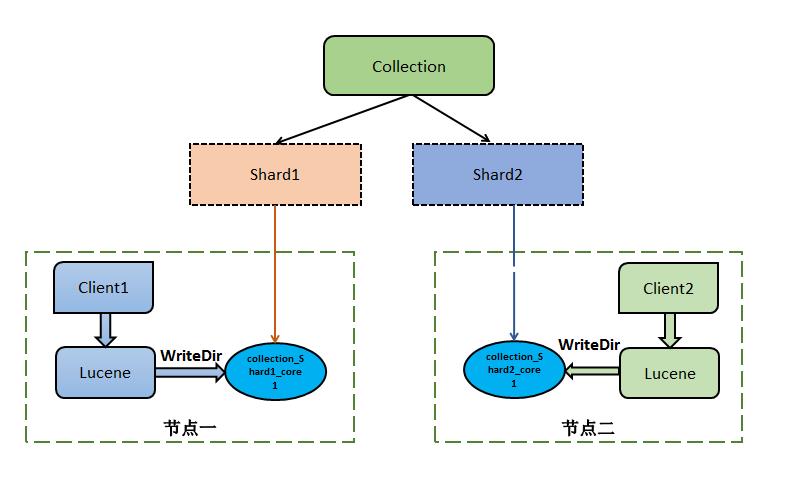
1、客户端调用 Lucene 的 API 直接在本地的 Solr 的 core 的目录建索引。(Collection 一个 shard 的副本其实就是一个 core 文件)
2、多个客户端,每个客户端对应一个 shard 副本,注意这里是一个 shard 只有一个副本的情况下,如果多个副本可能会导致数据不同步等问题。
3.2 思路实践
有了这个思路后,我就进行了实践,在不考虑数据备份的情况下和查询效率的情况下,优先考虑下建索引的效率,发现如下问题:
1、首先 Lucene 为了防止同一个目录由多个程序在写,加了文件锁,也就是通过了一个叫 write.lock 的文件来控制防止重复写的问题。
尝试解决:
到的第一个方法是看看有没有办法进行解锁,Lucene 的 4.9 版本里面还真有个解锁的方法:
if (IndexWriter.isLocked(index)) {
try {
IndexWriter.unlock(index);
} catch (Exception e) {
print_exception_trace(e);
}
}
但是这个方法,调用起来看起来是成功的,但是在真正往 solr 的目录进行写索引的时候仍然报错。遂放弃。这个思路本来没错的,既然在 solr 的索引目录无法再创建 Lucene 的索引,那么可以考虑在其他的目录创建索引,然后再合并到 solr 的索引中去。
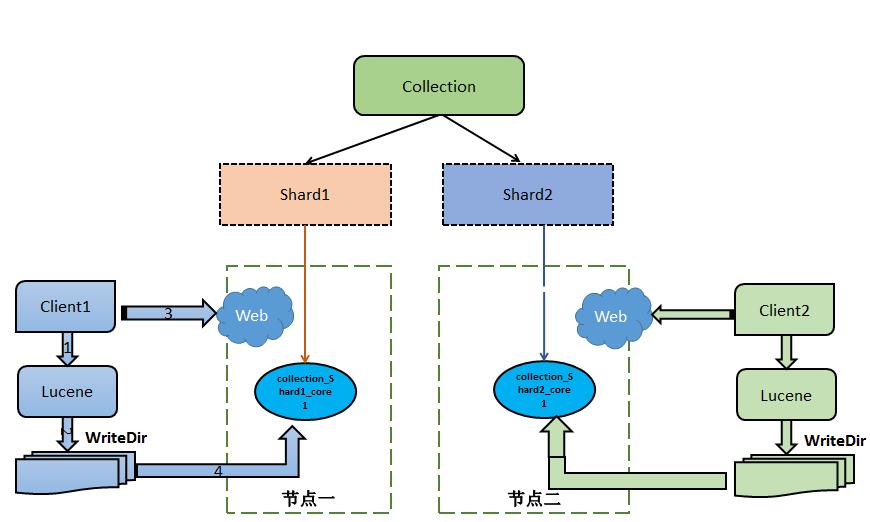
过程说明:
1、 客户端程序调用 lucene 的 API 进行写索引。
2、 索引写到特定的目录下。
3、 调用 solr 的索引合并的 HTTP 接口,进行索引合并。
4、 调用 HTTP 的合并结构后会将 Lucene 新建的索引目录合并到 Solr 的索引中去。
注意:1、 这种合并的 URL 如下:
http://ip:port/solr/admin/cores?action=mergeindexes&core=collection_shard1_replica1&indexDir=/parkfs01/aus/soft/luncenetmp/0
2、 合并后的索引不是可见的,需要重新加载索引,或者重新做提交,提交时候需要打开搜索器使索引可见:
http://ip:port/ solr/collection/update?commit=true&openSearcher=true
这里的 collection 要改成具体的 collection 名字。在单节点时候需要重新加载整个 core,
这个耗时很大,单节点仅仅提交,仍然搜索不到新添加的文档。
3、如果在一个目录下进行新建 Lucene 索引,需要删除目录后以备下次重写。
3.3 架构设计
方案一:
对于改造后的思路,设计了一种模式来进行建索引和提交并发进行,设计的结构如下:
说明:
1、文档生成线程是根据数据生成所需要建索引的文档集合。
2、文档集合生成后,发送到中间队列中去。3、有一个线程池,里面有 N 多线程,负责取文档集合,写入本地的索引文件夹中去, 注意一个线程对应一个 IndexWriter,一个 IndexWriter 对应一个文件夹。
4、将需要合并的 URL 和提交的 URL,发送到合并和提交队列中去。
5、提交合并线程池取到需要合并的 URL 和提交的 URL,先进行合并,然后提交。
6、提交后,为了让文件夹再次循环利用需要删除文件夹内容。
注意:
1、solr 的提交操作是很耗时的,在实际中,可以通过定时提交等手段进行进一步优化,不过 solr 本身设置的定时提交是无法起作用的。
2、在删除目录数据之前对于 4.x 版本需要进行 IndexWriter 的删除索引动作,不删除索引直接写会存在段信息错误的问题。
3、对于 lucene 的 6.0 版本,在删除文件的时候需要保存加锁文件 write.lock;不能通过删除索引的方式进行索引信息的清理,不然数据仍然有问题,直接删除文件即可。
4、以上设计经过测试,效率并没有高多少,也就是 2WTPS 左右。
方案二:
经过方案一的测试,发现速度并没有达到预期,方案一本想通过各个环节分离来达到并行的最大速率的目的,结果并不如意,经过分析后设计第二套方案,如图:
说明:
1、根据要求生成文档。
2、根据生成的文档列表生成可执行单元,可以执行单元的主要是创建 IndexWriter 和添加索引动作。
3、将可行对象发送给线程池执行。
4、执行完毕后将需要合并的索引目录和 url 发送到合并队列,合并队列数量达到一定数量后,执行合并索引动作和提交索引动作。
5、索引线程池存在建立一定数量索引后,会关闭原来的 IndexWriter,从新创建的目录生成新的 IndexWriter。
注意:
1、因为 IndexWriter 是线程安全的,所以线程池可以共同操作同一个 IndexWriter 对象。
2、在合并索引后,不能立刻删除目录,调用 SOLR 的合并索引的 URL 返回后,后台也有可能还在合并。
3、经过测试在一个索引文档 286 个字节条件下,solr6.0 版本,速率大概在 4.7W 和 5.1W 之间浮动。
方案三:方案二测试的速率不太稳定,而且需要定时执行删除索引文件,提交和合并索引的速率还是比较慢。需要合并、提交索引和删除索引文件的根本在于 Lucene 的索引和 solr 的索引不在同一个目录,写同一个目录测试有问题的是 4.9 版本,所以想在 solr6.0 版本上测试试试。结果在 solr6.0 版本,通过直接程序删除 write.lock 后,可以将索引直接写到 solr 的索引目录里面去。但是如果让数据可见,就必须重新 reload 整个索引副本,在 reload 整个索引副本后,数据可以查询,但是由于我们删除了 write.lock,导致了重新 reload 的 solr 日志存在部分错误信息。简单的测试结果如下:
1、测试环境:2 台机器,2 个 solr 节点,实际使用一个节点,配置:64G 内存、16CPU。
2、线程个数:1 个。
3、按照报文大小分别为 0.2k、1k、2k 测试结果如下:
| 序号 | 报文大小(字节) | 速率(TPS) | 吞吐量(MB/s) |
|---|---|---|---|
| 1 | 286 | 51088 | 9.9 |
| 2 | 1228 | 37900 | 44 |
| 3 | 2406 | 38000 | 84 |
以上是关于solr建索引优化的主要内容,如果未能解决你的问题,请参考以下文章