零距离观察蚂蚁+阿里中的大规模机器学习框架
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了零距离观察蚂蚁+阿里中的大规模机器学习框架相关的知识,希望对你有一定的参考价值。
本文根据蚂蚁金服的资深技术专家周俊在蚂蚁金服&阿里云在线金融技术峰会上《大规模机器学习在蚂蚁+阿里的应用》的分享整理而成。在分享中,周俊详细介绍了阿里巴巴大规模机器学习框架——参数服务器的设计理念以及优化方法,并结合支付宝、阿里妈妈直通车搜索广告等具体场景详解了参数服务器在蚂蚁金服和阿里内的应用;分享最后,他对大规模机器学习的未来发展做了展望。
以下为整理内容。
设计理念
图一 大数据时代
当今我们正处于一个大数据时代,Google每天产生30亿查询、300亿Served广告、30万亿indexed网页;FaceBook目前全球超过14亿用户,每天分享43亿内容;推特每天产生4.3万亿Tweets;Apple Store每天App下载量达到1亿左右。国内的互联网公司,阿里巴巴一年产生86亿包裹,平均每天2356万个;蚂蚁金服/支付宝在2015年双十一当天共产生7.1亿笔支付。
这么多数据如何才能有价值地将其利用起来呢?
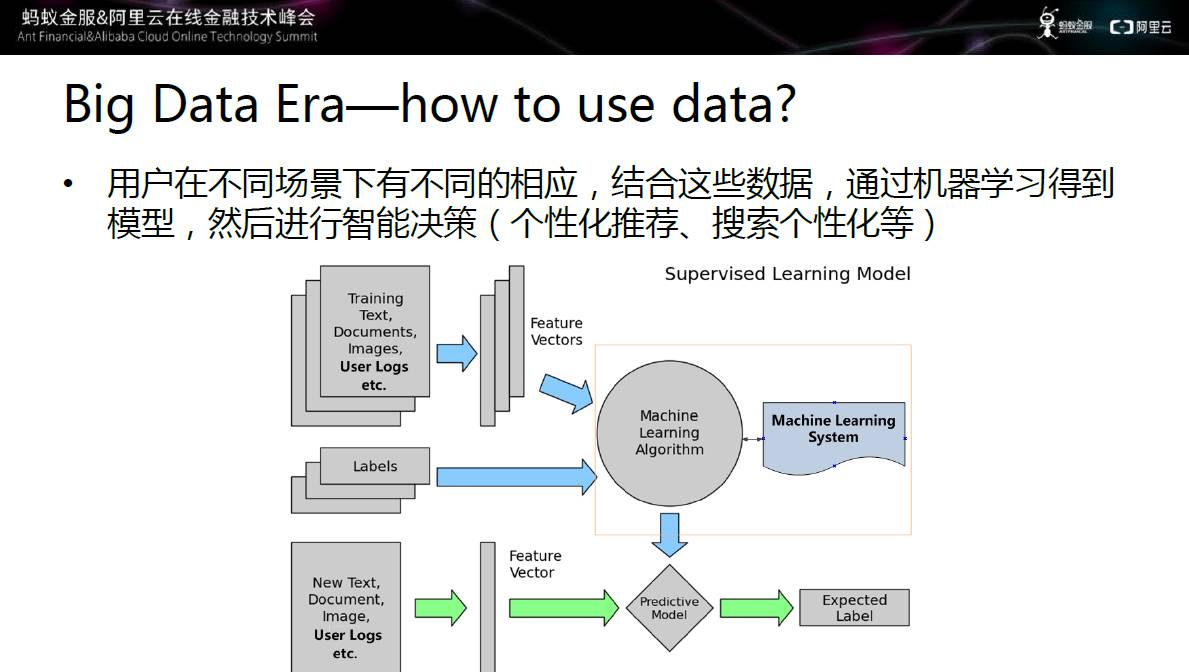
图二 如何利用大数据
用户在不同场景下有不同的响应,结合这些数据通过机器学习得到模型,然后进行智能决策,如个性化推荐、搜索个性化等。上图中显示的监督学习的案例,监督学习通过搜集大量用户的日志、用户行为,然后抽取成特征,然后将特征送入机器学习系统中,系统通过一定的方式得到相应的模型。一个用户到来之后,对用户特征进行提取,将用户特征送入模型中,得到预测结果。例如记录用户的点击。购买、收藏等行为,经过模型的预测,根据用户之前的偏好,进行个性化推荐。
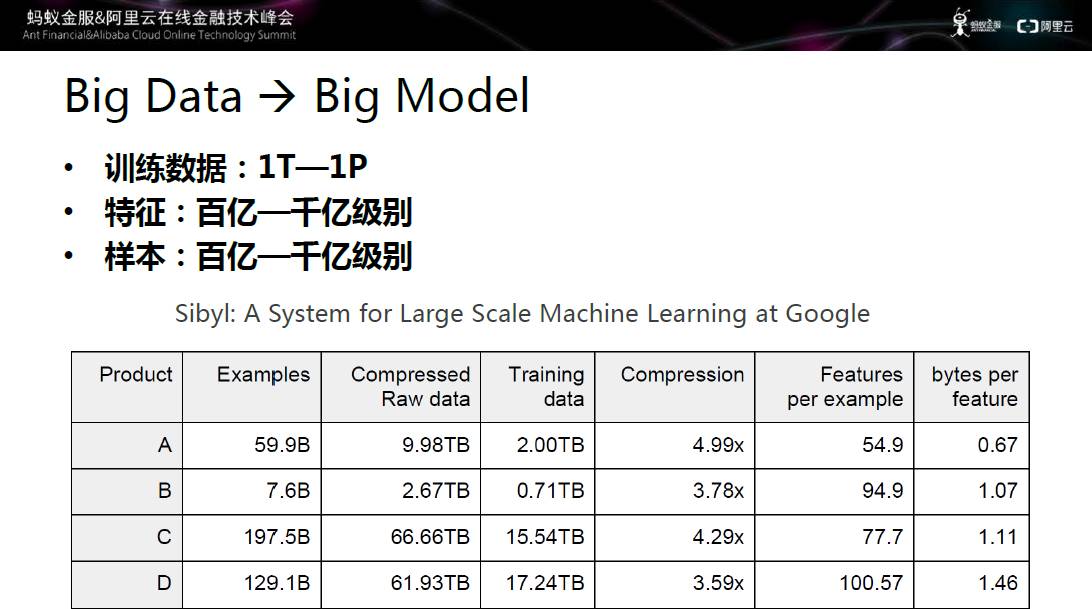
图三 大数据带来的挑战
大数据给机器学习带来机遇的同时也带来了相应的挑战。第一个挑战是模型会非常大,谷歌的大型机器学习系统Sibyl,五年前的训练数据在1T到1P左右,特征级别达到百亿到千亿级别;样本同样是百亿到千亿级别。

图四 大数据与大规模模型结合
如此大的数据和如此大的模型如何进行结合呢?思路是采用分布式学习系统,结合算法和系统两方面入手。
正如上文所提到的,在大数据上,利用机器学习从中学习到知识,是人工智能取得突破的主要手段,也是系统架构师面临的重要挑战之一。很多的模型和抽象先后用于解决这一任务,从最早期的MPI,到后来的MapReduce,再到当前使用较多的Graph、Spark等。
分布学习系统包括两大模块:模型和分布式系统。其中模型需要解决训练和正确率的问题,分布式系统需要考虑并行、网络、慢机、故障处理、调度。
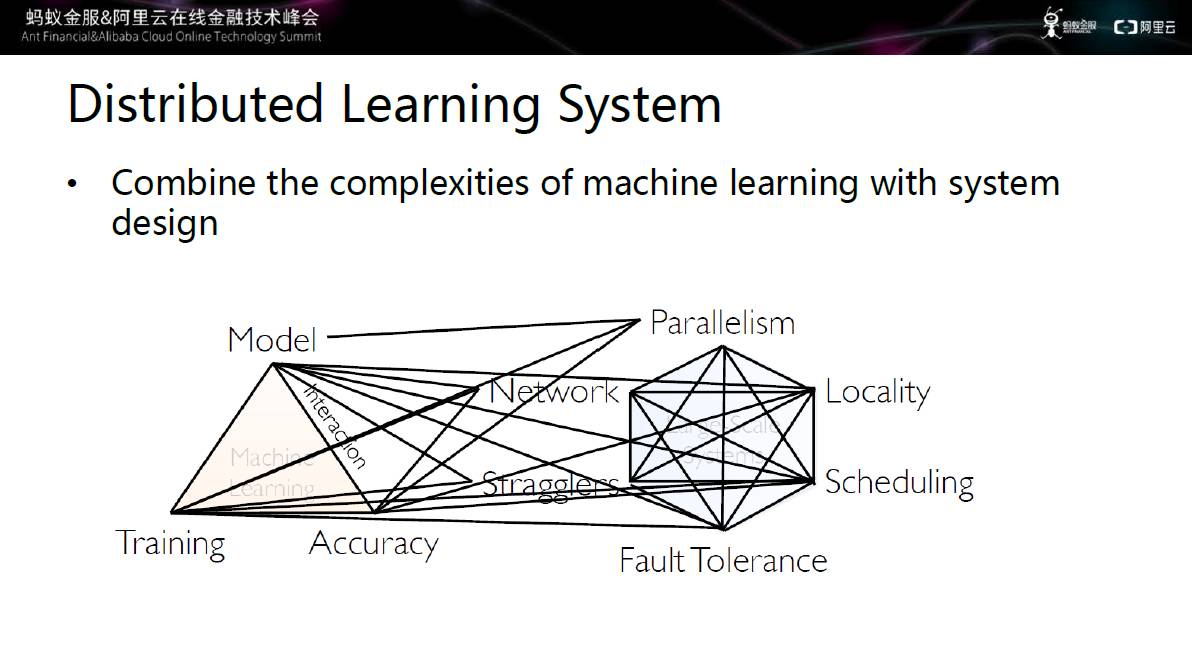
图五 分布式学习系统
如上图所示,分布式学习系统将两者的复杂度结合起来。每一个维度和算法都有融合、交叠。在网络方面,需要考虑网络的通信效率,因为模型非常大,如果直接预发会造成网络的巨大负担,如果有些流量不发,又会影响训练和模型的正确率。
慢机方面,在数千台机器中,肯定会存在机器处理速度的差异,如果采用完全同步的方法,迭代的速度是取决于最慢的机器,这就造成了资源的巨大浪费。第三故障处理,数千台机器中一定会出现机器挂掉的现象,机器挂掉之后如何让训练继续进行,获得正确的训练模型这也是一个非常大的挑战。

图六 工业界现有的系统的不足
首先看一下现有工业界系统的缺点:
MapReduce:迭代式计算低效,节点之间通信效率不高;
MPI:无法支撑大数据,任意节点挂掉,任务就失败;
Graph:用图来做抽象,类似深度学习无法高效求解,只能同步,不支持异步;
Spark:通用框架,高维度和稀疏数据支持不够;
综合考虑模型训练正确率、故障处理、慢机等因素,性价比高的选择是参数服务器(Parameter Sever)。
大规模机器学习框架-参数服务器

图七 大规模学习框架——参数服务器
参数服务器是机器学习的核心竞争力和技术壁垒之一,之所以这么说是因为:首先,它需要使用大数据(1T-1P)快速训练、快速迭代优化;同时需要考虑failover、通信/计算效率、收敛速度等多个特性。
在之前的分析中,阿里巴巴的ODPS中的MPI为例,统计了MPI中的Job的成功率(上图所示),当Work数超过1000时,成功率低于30%,从而导致稳定性很差,浪费大量的资源和费用。由于存在稳定性和成功率等问题,我们自己设计了一套参数服务器框架。
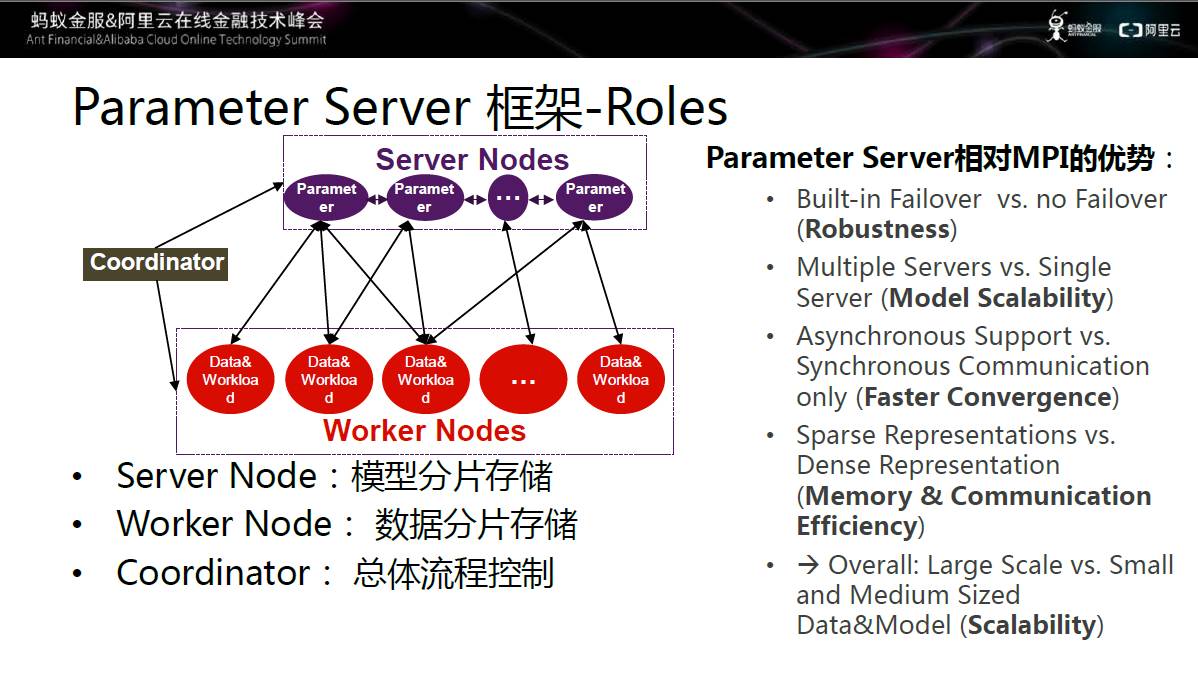
图八 参数服务器框架图
框架的大致结构如上图所示,包括三大模块:Server Node、Worker Node、Coordinator,分别用于模型分片存储、数据分片存储和总体流程控制。该结构相对于MPI的优势在于:
内置Failover机制,稳健性大大提升;
架构中有多个Server,模型的可扩展性非常强;
完美支持同步和异步,可以达到更快的收敛速度,同时不影响模型的精度;
同时在稀疏性的上支持,让worker和server节点在通信效率上大幅度提升。
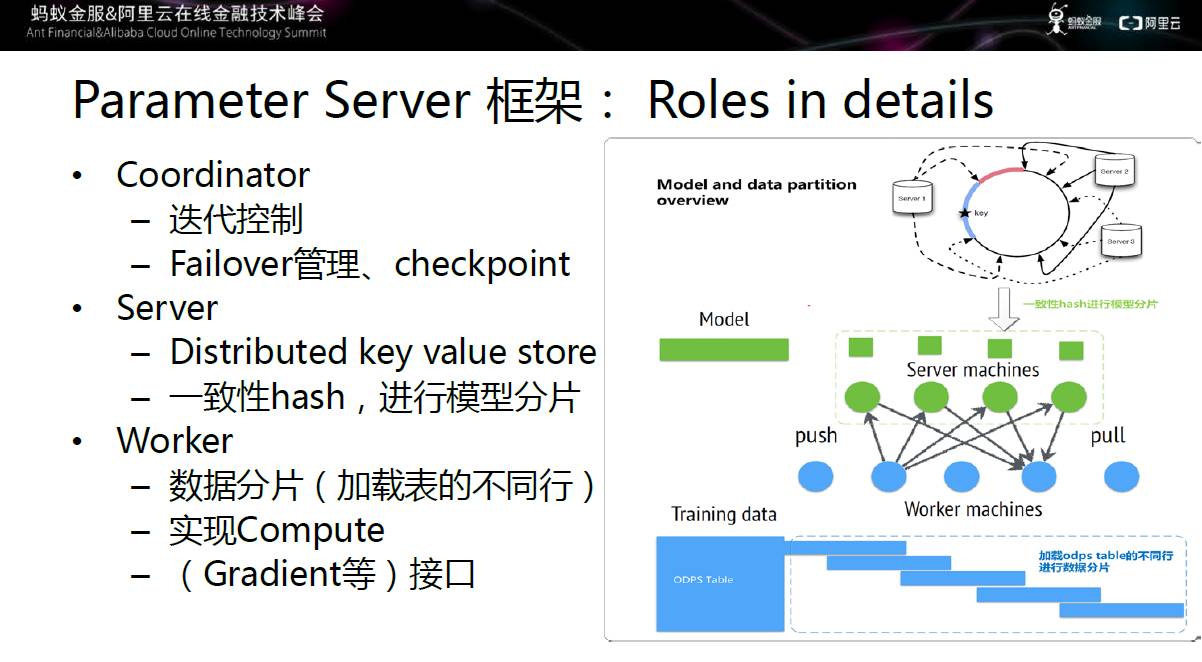
图九 参数服务器具体框架
具体来讲,Coordinator主要进行迭代控制,同时完成Failover管理,当Worker或Server挂掉时,由Coordinator进行处理;当Worker、Server和整个Job都失败的情况下,通过Checkpoint机制,在下一次启动时从上一次保存的中间结果继续前进。

大流量&高并发
互联网应用实践在线峰会

应对超大流量、超高并发的绝密实践,最适合技术开发者的夜间技术交流、每场1.5小时互动分享、素材第一时间公开、全开放注册,我们希望通过在线峰会这样的新模式,广聚开发者,共建技术分享的生态。
[ 09月21日 ] 阿里聚石塔电商云容器服务应用和实践
[ 09月21日 ] 如何打造应对超大流量的负载均衡
[ 09月21日 ] 聚星台:客户运营核心大数据与算法技术
扫码直入报名页:
以上是关于零距离观察蚂蚁+阿里中的大规模机器学习框架的主要内容,如果未能解决你的问题,请参考以下文章