机器学习框架之争将走向何方?
Posted 重大计算机研工组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习框架之争将走向何方?相关的知识,希望对你有一定的参考价值。
选自The Gradient
2019 年,ML 框架之争只剩两个实力玩家:
PyTorch 和 TensorFlow。
研究者大批涌向 PyTorch,而业界的首选仍然是 TensorFlow。
未来,谁能在 ML 框架之争中迎来「高光时刻」?
自 2012 年深度学习再度成为焦点以来,很多机器学习框架成为研究者和业界工作者的新宠。
从早期的学术框架 Caffe、Theano 到如今有业界背景的大规模框架 Pytorch 和 TensorFlow,层出不穷的新成果使得跟踪当前最流行的框架变得越发困难。
如果只刷 Reddit,你可能觉得大家现在都转投 Pytorch 了。而如果看一下谷歌研究员 Francois Chollet 的推特,你可能又觉得 TensorFlow/Keras 会成为将来的主导框架,而 PyTorch 则陷入停滞。
2019 年,ML 框架之争还剩两个实力玩家:PyTorch 和 TensorFlow。我的分析结果表明:研究者正在抛弃 TensorFlow,大批涌向 PyTorch;而在业界,TensorFlow 仍是目前的首选,但这种情况可能不会维持太久。
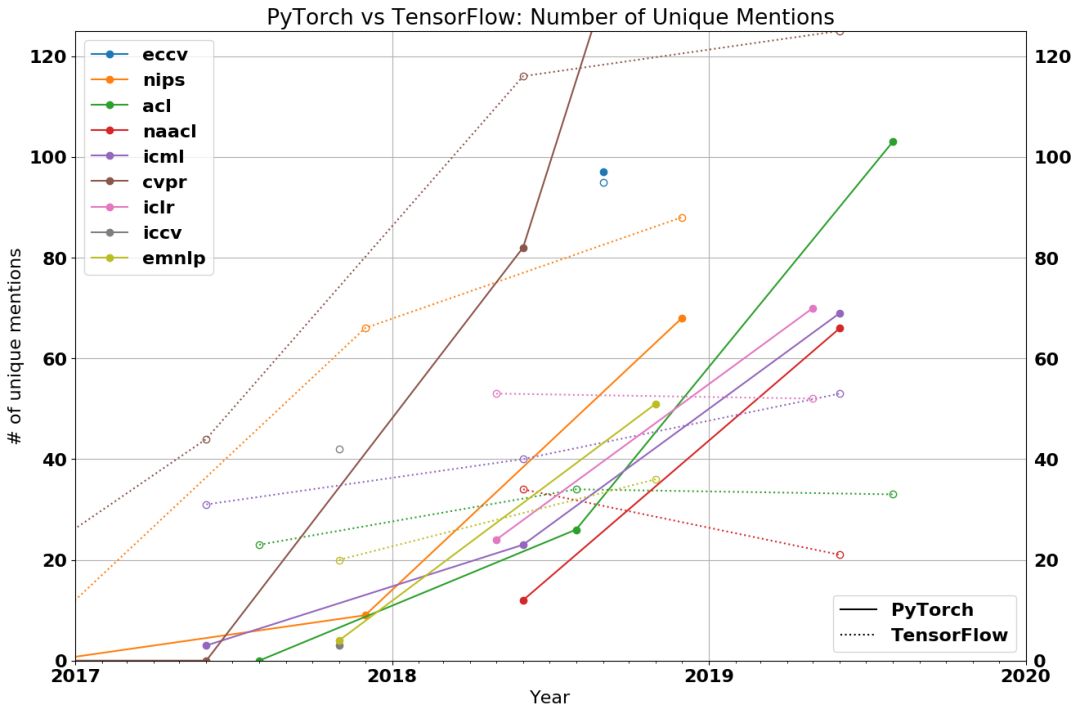
我们来看一组数据。下图展示了在每次学术顶会中「使用 PyTorch」占「使用 TensorFlow 或 PyTorch」的论文比例。所有的线都向上倾斜,2019 年的每个学术顶会都有大量论文用 PyTorch 实现。
该图的交互版本参见:https://chillee.github.io/pytorch-vs-tensorflow/。
2018 年,使用 PyTorch 的还是少数派,而如今,PyTorch 已经称霸学界,使用 PyTorch 的 CVPR 论文占 69%,NAACL 和 ACL 都超过了 75%,ICLR 和 ICML 都超过了 50%。PyTorch 不止在视觉和语言会议中占据主导地位,在 ICML、ICLR 等综合机器学习会议中也更加受欢迎。
如果你想知道 PyTorch 在学界发展有多快,这里有一张 PyTorch 和 TensorFlow 的原始统计图。
虽然有些人相信 PyTorch 仍然是一个试图在 TensorFlow 主导的世界中开疆扩土的新贵框架,但数据却无法支撑这些观点。除了 ICML,甚至没有一个会议中的 TensorFlow 增速能跟上论文的整体增速。在 NAACL、ICLR 和 ACL 中,今年利用 TensorFlow 实现的论文实际上低于去年。
需要担心自己未来的不是 PyTorch,而是 TensorFlow。
即使 TensorFlow 与 PyTorch 功能相当,PyTorch 也已经成为了社区的主流。这也意味着,PyTorch 实现在社区中将更加常见,作者们也会更加乐于发布 PyTorch 代码(这样人们才会去用),你的合作者们也会更加偏爱 PyTorch。因此,如果真的要回归 TensorFlow 2.0,那也将是一个漫长的过程。
TensorFlow 在谷歌/DeepMind 内部有一批捆绑用户,我想知道谷歌最终会不会将这批用户松绑。即使是在现在,谷歌想要招募的很多研究者也都会或多或少地偏爱 PyTorch,我听说谷歌内部的很多研究者都想使用 TensorFlow 之外的框架。
此外,PyTorch 的主导地位可能会切断谷歌研究者与研究社区的沟通。一方面,他们难以在外部研究的基础之上构建新的研究;另一方面,外界研究者也很难在谷歌发布的代码之上进行改进。
TensorFlow 能否重新激发研究者的兴趣还有待观察。尽管 eager 模式很吸引人,但 Keras API 可不是。
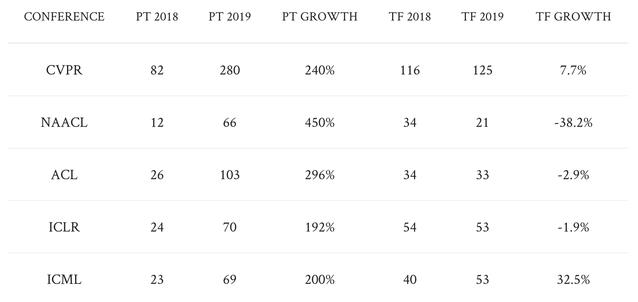
尽管 PyTorch 现在已经称霸学界,但纵览业界可以发现,TensorFlow 仍然是主导框架。例如,根据 2018 和 2019 年的数据,TensorFlow 和 PyTorch 对应的岗位数分别是 1541 和 1437,Medium 文章数分别是 3230 和 1200,GitHub 新增星数分别为 13.7k 和 7.2k。
PyTorch 在学界如此流行,为什么在业界却稍显逊色呢?这首先要归因于惯性。TensorFlow 比 PyTorch 早几年问世,业界接纳新技术的速度又总是慢于学界。另一个原因在于,TensorFlow 比 PyTorch 更适用于生产环境。此话怎讲呢?要回答这个问题,我们需要先了解一下学界和业界需求的差异。
研究者关心的是迭代速度,他们通常用的是比较小的数据集(一台机器就能处理的数据集),用到的 GPU 通常不到 8 个。这种情况通常不会受到性能状况的影响,限制因素是研究者快速实现新想法的能力。而业界认为性能才是最重要的。运行速度提高 10% 对于研究者来说可能毫无意义,但却可能为公司节省数百万美元。
学界和业界在部署方面也有很大的不同。研究人员会在自己的机器或专门用于运行研究项目的服务器集群上进行实验,但业界有一大串的限制或要求:
没有 Python。一些公司的服务器可能承担不了 Python 运行时的开销。
移动设备。你不能在移动代码中嵌入 Python 解释器。
服务性。这是一个包罗万象的特性,如模型的无停机更新、模型之间的无缝切换、预测时间的批处理等。
TensorFlow 就是围绕这些需求打造的,而且为所有这些问题都提供了解决方案:图格式和本地执行引擎不需要 Python,TensorFlow Lite 和 TensorFlow Serving 可以分别解决移动和服务性难题。
纵观过往,PyTorch 始终未能满足这些要求,因此多数公司在生产环境中仍然选用 TensorFlow。
2018 年底,两件大事改写了两个框架之间的故事:
PyTorch 引入了 JIT 编译器和「TorchScript」,由此拥有了基于图的特性。
TensorFlow 宣布将在 2.0 版本中默认切换到 eager 模式。
显然,两家的举动都是为了弥补自身的不足。那么这些特性到底是什么?它们又带来了什么?
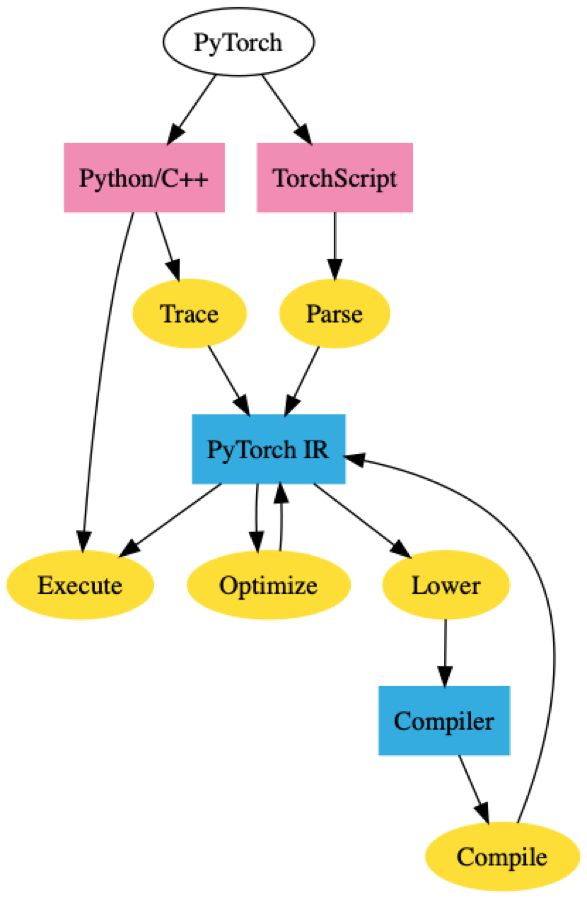
PyTorch TorchScript
PyTorch JIT 是 PyTorch 的一个中间表征(IR),被称为 TorchScript。TorchScript 是 PyTorch 的「图」表征。你可以使用 tracing 或 script 模式把一个常规的 PyTorch 模型转换为 TorchScript。tracing 接收到一个函数和一个输入,记录下用该输入执行的操作,然后构建 IR。
虽然简单,但 tracing 也有其缺点。例如,它无法捕获还未执行的控制流。例如,如果执行了条件语句的真块(true block),它就无法捕获假块(false block)。
Script 模式接收一个函数/类,重新解释 Python 代码,然后直接输出 TorchScript IR。这使得它可以支持任意代码,但它需要重新解释 Python。
一
旦你的 PyTorch 模型在这个 IR 中,我们就得到了图模式的所有好处。
我们可以在没有 Python 依赖的情况下用 C++部署 PyTorch 模型,还可以优化该模型。
在 API 层面上,TensorFlow 的 eager 模式与 PyTorch 的 eager 模式基本相同,最初是由 Chainer 发明的。加入 eager 模式之后,TensorFlow 就拥有了 PyTorch eager 模式的大部分优势(易用、可调试等)。
但这也给 TensorFlow 带来了相同的劣势。TensorFlow 的 eager 模型不能导出到非 Python 环境中,无法优化,也无法在移动端运行。
这将 TensorFlow 置于与 PyTorch 相同的境地,它们的解决方式也基本相同——要么跟踪你的代码(tf.function),要么重新解释 Python 代码(Autograph)。
因此,TensorFlow 的 eager 模式也不是万能的。尽管你可以用 tf.function 注释将 eager 代码转换为静态图,但这并不是一个无缝过程(PyTorch 的 TorchScript 也有类似问题。)tracing 在根本上被限制了,重新解释 Python 代码本质上需要很大程度上重写 Python 编译器。当然,通过限制深度学习中用到的 Python 子集可以极大地简化这一范围。
在默认情况下启用 eager 模式时,TensorFlow 强迫用户做出选择,要么为了易用性使用 eager 执行,这种做法需要为了部署而重写;要么彻底不用 eager 执行。PyTorch 也面临相同的问题,但 PyTorch 可选择性加入的 TorchScript 似乎更加令人愉悦。
根据上面的内容,我们可以判断出 ML 框架的现状:
PyTorch 拥有研究市场,并尝试将成功经验复制到业界;
TensorFlow 则试图在不牺牲过多生产力的情况下,也尽其所能守住学界的一些地盘。
PyTorch 肯定要花很长时间才能在业界站稳脚跟,因为 TensorFlow 的地位很稳固,业界的接受速度也比较缓慢。
不过 TensorFlow 从 1.0 到 2.0 的进阶将很困难,这也为公司评估 PyTorch 提供了契机。
我们还没有完全认识到机器学习框架对 ML 研究有多大影响。它们不只是影响机器学习研究本身,还会影响研究者的理念。多少个新 idea 都是因为在框架中找不到容易的表达方法而彻底粉碎的?PyTorch 可能已经实现了研究中的局部最小值,但是其他框架所能提供的研究内容和机会仍然值得探索。
PyTorch 和 Tensorflow 的核心是自动微分框架,它允许使用某些函数的导数。尽管有许多方法可以实现自动微分,但大多数现代 ML 框架选择的都是「反向模式自动微分」(通常称为「反向传播」)。事实证明,这对于采用神经网络的导数极为有效。
但是计算高阶导数(Hessian/Hessian Vector Products)的话,情况就不一样了。想要高效地计算这些值需要用「前向模式自动微分」。不用这个功能的话,高阶导数的计算速度会慢几个量级。
输入 Jax。Jax 的创造者和原始 Autograd 是同一人,它也同样具备正向和反向两种自动微分模式,使得高阶导数的计算速度比 PyTorch 或 TensorFlow 还要快几个数量级。
除了高阶导数的计算,Jax 的开发人员还将 Jax 看作一个任意函数变换的框架,包括用于自动批处理的 vmap 或自动并行化的 pmap。
原始的 Autograd 拥有自己的忠实粉丝(即使没有 GPU 的支持,ICML 上也有 11 篇论文都使用了它)。之后,Jax 会建立一个类似的可用于各种 n 阶函数的专门社区。
当你运行 PyTorch 或 TensorFlow 模型时,实际上大多数运行并不是在框架内,而是由第三方内核完成的。这些内核通常由硬件供应商提供,并且由可利用的高级框架的算子库组成。这就是 MKLDNN(用于 CPU)或 cuDNN(用于 Nvidia GPU)之类的东西。高级框架将其计算图分成多个块,然后调用这些计算库。这些库能持续使用数千个工时,同时能针对体系架构和应用程序进行优化以产生最佳性能。
但是,近期对于非标准硬件、稀疏/量化张量的和新算子的研究显示出了使用这些算子库的主要缺陷:它们不够灵活。就比如说,你要是想在研究中使用像胶囊网络这样的新算子该怎么办?想在没有很好的 ML 框架支撑的新硬件加速器上运行模型怎么办?现有的解决方案可能就达不到要求了。正如本文所指出的,现有的胶囊网络实现在 GPU 上的表现比理想中要慢 2 个量级。
每个新硬件体系架构、张量类别或算子都会大大增加这个问题的解决难度。有各式各样的工具可以用来解决不同方面的问题(Halide、TVM、PlaidML、张量理解、XLA、Taco 等),但综合来看还没有一个特别完善的解决方式。
在没有更多的办法来解决这个问题的情况下,一定意义上说,我们是在冒着将 ML 研究和现有工具过度拟合的风险。
未来 TensorFlow 和 PyTorch 将会有更加「高光」的时刻。
这些框架的设计越来越趋于一致,所以将来任何一个框架都不会凭借其设计获得决定性的胜利。
每个框架都有自己的领土:
一方擅长研究,另一方则制霸产业。
个人来说,在 PyTorch 和 TensorFlow 之间,我会更青睐 PyTorch。
机器学习仍然是一个研究驱动型的领域,产业界还是会十分在意研究成果,只要 PyTorch 主导研究,企业就必须做出选择。
但是,除了快速发展的框架,机器学习的研究本身也处于不断变化的状态。
不仅框架会发生变化,而且 5 年后使用的模型、硬件、范式都可能跟我们今天使用的有大不相同。
假如有某种新计算模型的普及,也许 PyTorch 和 TensorFlow 之间的竞争会变得无关紧要。
在诸如此类由机器学习带来的利益竞争和浪潮中,最好还是持保守态度。大多数人也并不是为了赚钱或者协助企业的战略而去开发机器学习的软件,我们之所以关心,只是因为期待机器学习研究更进一步,让 AI 更加普及,或者说只是想关注一些有趣的东西。
无论是站「TensorFlow」还是「PyTorch」,我们都是怀着让机器学习软件变得越来越棒的初心而已。
以上是关于机器学习框架之争将走向何方?的主要内容,如果未能解决你的问题,请参考以下文章
2019年机器学习框架之争: PyTorch主导学术界,工业界首选TensorFlow
2019机器学习框架之争:与Tensorflow竞争白热化,进击的PyTorch赢在哪里?
最受欢迎机器学习框架“王座”之争:PyTorch “存在感”已直逼 Tensorflow
机器学习框架从开源走向融合
最适合中国开发者的深度学习框架:走向成熟的PaddlePaddle 1.0
深度学习的冬天什么时候到来?