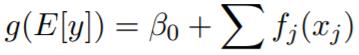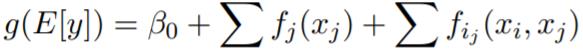微软开源可解释机器学习框架InterpretML Posted 2021-05-02 我爱计算机视觉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微软开源可解释机器学习框架InterpretML相关的知识,希望对你有一定的参考价值。
点击 我爱计算机视觉 标星,更快获取CVML新技术
起初,机器于黑暗之中学习,为解释它们,数据科学家于虚空之中挣扎。
微软在可解释机器学习项目 InterpretML 的 GitHub 页面上这样写到。 很显然,他们相信 InterpretML 会是打开机器学习黑箱的钥匙。
在机器学习领域,可解释性(interpretability)至少在以下几个方面至关重要:
过去,最好理解的模型往往非常不准,而最准确的模型又无法被我们理解。微软研究院之前已经开发了一个名为「可解释 Boosting 机(EBM:Explainable Boosting Machine)」的算法,可以在实现高准确度的同时具备可理解性。EBM 通过 bagging 和 boosting 等现代机器学习技术为传统的 GAM(广义可加模型)注入了新生命。这使得它们能像随机森林和梯度提升树一样准确,同时其可理解性和可编辑性也得到了增强。
现在,微软研究院更进一步,在 EBM 的基础上扩展并开源了一个用于机器学习可解释性的统一框架 InterpretML,该框架基于 Python,可用于训练可解释模型和解释黑箱系统。
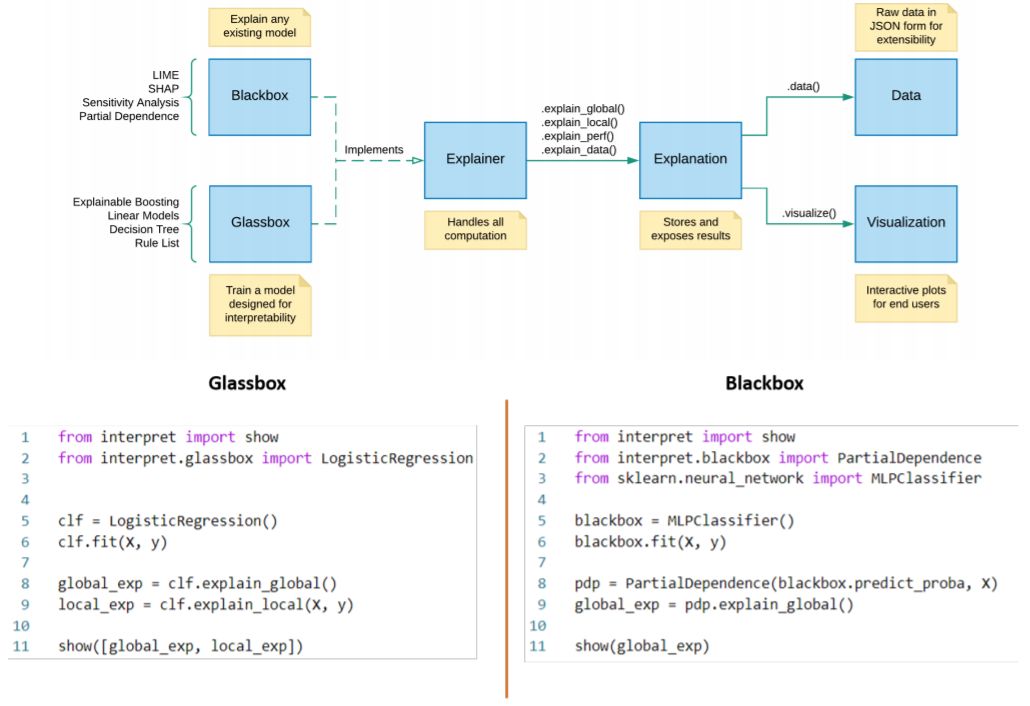
InterpretML 是一个为实践者和研究者提供机器学习可解释性算法的开源 Python 软件包。InterpretML 能提供两种类型的可解释性:(1)明箱(glassbox),这是针对可解释性设计的机器学习模型(比如线性模型、规则列表、广义加性模型);(2)黑箱(blackbox)可解释技术,用于解释已有的系统(比如部分依赖、LIME)。这个软件包可让实践者通过在一个统一的 API 下,借助内置的可扩展可视化平台,使用多种方法来轻松地比较可解释性算法。InterpretML 也包含了可解释 Boosting 机(EBM)的首个实现,这是一种强大的可解释明箱模型,可以做到与许多黑箱模型同等准确。
随着机器学习日益成熟,应用愈渐广泛,构建能让用户理解的模型也正变得越来越重要。在医疗、金融和司法等高风险应用中,这一点尤其显著。可解释性在模型调试、合规性和人机交互等一般应用的机器学习问题方面也很重要。
InterpretML 正是为解决这些需求而生的,其将很多当前最先进的可解释性算法纳入到了一个统一的 API 下。这个 API 包含两种主要的可解释性形式:明箱模型,即让用户能够理解以及向用户解释;黑箱可解释性,即能为任何机器学习流程(不管多么不透明)生成解释的方法。其还开发了进一步的功能,支持交互式可视化,还有一个为可解释性算法比较而设计的内置仪表盘。InterpretML 使用了 MIT 许可,并重点关注可扩展性以及与 scikit-learn 和 Jupyter Notebook 环境等常见开源项目的兼容性。
InterpretML 的架构和 API 设计遵循四个关键设计原则。
易于比较。
使多个算法的比较尽可能地容易。机器学习可解释性还处于发展早期,不同的研究创造了很多不同的算法方法,每一种都各有优劣。比较能让用户找到最适合自身需求的算法。InterpretML 实现了这一点,其做法是采用了一种 scikit-learn 风格的统一 API,另外其还提供了一个以算法比较为中心的可视化平台。
忠于来源。
尽可能地使用参照算法和可视化。InterpretML 的目标是以最准确的形式为世界提供可解释性算法。
能与其它方法很好协同。
利用开源生态系统,不重复发明轮子。InterpretML 与 Jupyter Notebook 和 scikit-learn 等常用项目高度兼容,并且其构建过程也使用了很多库,比如 plotly、lime、shap 和 SALib。
按需使用。能使用和扩展 InterpretML 的任意组件,而无需引入整个框架。比如可以在服务器上得到计算密集型的解释,无需 InterpretML 的可视化及其它相关依赖。
图 1 展示了 InterpretML 的代码架构和统一 API,其中提供了整体的概况以及相关的代码示例。
InterpretML 框架还包含一种新的可解释算法——可解释 Boosting 机(EBM)。
相关论文:https://www.microsoft.com/en-us/research/wp-content/uploads/2017/06/KDD2015FinalDraftIntelligibleModels4HealthCare_igt143e-caruanaA.pdf
EBM 是一种明箱模型,是为与随机森林和提升树等当前最佳机器学习方法比较准确度而设计的。EBM 是一种广义加性模型(GAM),其形式为:
其中 g 是将 GAM 适配于回归或分类等不同设置的链接函数。EBM 相比于传统 GAM(Hastie and Tibshirani, 1987)有几项重大改进。第一,EBM 使用 bagging 和梯度提升等现代机器学习技术来学习每个特征函数 f_j。boosting 流程使用非常低的学习率以轮询方式非常慎重地限定为一次训练一个特征,这样特征顺序就不重要了。它在特征中轮询循环,以减缓共线性的影响以及学习每个特征的最佳特征函数 f_j,从而展示每个特征对模型的预测的贡献量。第二,EBM 可以按以下形式自动检测和囊括成对的交互项:
这能在维持可理解性的同时进一步提升准确度。EBM 是 GA²M 算法(Lou et al., 2013)的一种快速实现,使用 C++ 和 Python 写成。这个实现是可并行的,并利用了 joblib 来提供多核和多机并行。该算法在训练流程和成对交互项选择方面的细节以及案例研究请见(Lou et al., 2012, 2013; Caruana et al., 2015)。
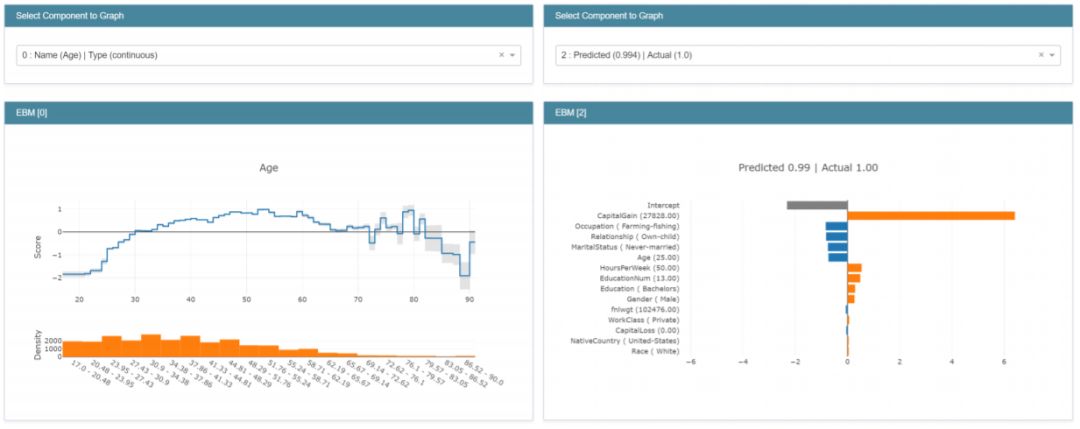
EBM 是高度可理解的,因为每个特征对最终预测的贡献都可以通过绘制 f_j 的图来可视化和理解。因为 EBM 是一种加性模型,所以每个特征对预测的贡献都是模块化的,因此可以很简单地推理每个特征对预测的贡献。
图 2: 左: 函数 f_Age。 随着 Age 从 20 增长到 50,p(1) 增长显著。 右: 单个预测,其中 CapitalGain 特征占主导地位。
为了进行单个预测,每个函数 f_j 都可作为每个特征的查找表,可返回项贡献。只需要简单地将这些项贡献加起来,然后通过链接函数 g 来计算最终预测。因为模块化的特性(加性),可以对项贡献进行分类和可视化,从而可展现哪些特征对任意的单个预测的影响最大。
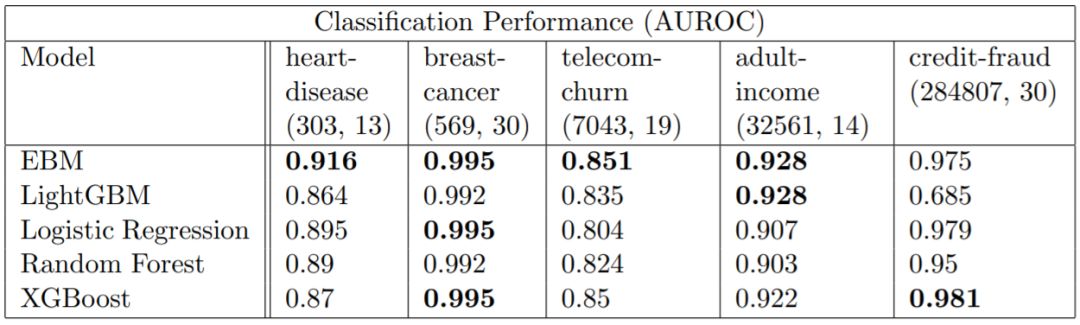
表 3: 不同模型在不同数据集上的分类性能(行,列)
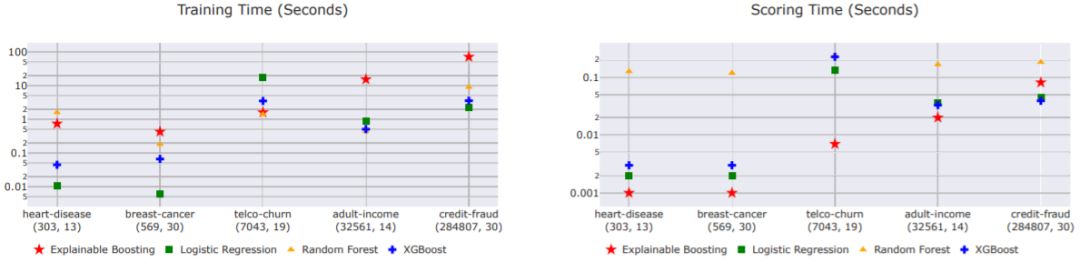
图 4: 不同模型在不同数据集上的计算性能(行,列)
就预测能力而言,EBM 的表现常常出奇地好,而且能与随机森林和 XGBoost 等当前最佳方法媲美。为了保证各个项的加性,EBM 要付出额外的训练成本,因此会比表现相近的其它方法慢一些。但是,由于预测仅涉及到在特征函数 f_j 中进行查找和简单的加法,所以 EBM 在预测时是执行最快速的模型之一。EBM 的轻量级内存使用和快速预测时间使其尤其适合模型的生产部署。
https://arxiv.org/abs/1909.09223v1
https://github.com/microsoft/interpret
CV细分方向交流群
52CV已经建立多个CV专业交流群,包括:目标跟踪、 目标检测、语义分割、姿态估计、人脸识别检测、医学影像处理、超分辨率、神经架构搜索、GAN、强化学习等,扫码添加CV君拉你入群,如已经为CV君其他账号好友请直接私信,
(请务必注明相关方向,比如: 目标检测 )
(不会时时在线,如果没能及时通过验证还请见谅)
长按关注 我爱计算机视觉
以上是关于微软开源可解释机器学习框架InterpretML的主要内容,如果未能解决你的问题,请参考以下文章