重磅:虚拟化交换机性能优化探讨实录@KVM社区实名制群
Posted 云技术实践
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重磅:虚拟化交换机性能优化探讨实录@KVM社区实名制群相关的知识,希望对你有一定的参考价值。
嘉宾介绍:
刘年超,现任职中兴通讯云计算&政企业务产品部,负责云数据中心产品架构规划,见证公司基于SDN架构云数据中心从无到有。目前对Openstack、KVM、vSwitch、SDN/NFV 、分布式存储及IDC虚拟化网络解决方案优化均有浓厚的兴趣和深入的研究。
分享主题:
虚拟化交换机性能优化探讨
网络性能瓶颈在哪儿
网络加速设计核心思路
虚拟化技术回顾
基于DPDK 用户态的OVS性能测试
业界虚拟交换机加速方案对比
虚拟交换机面临的问题
以下为分享实录:
1 网络性能瓶颈在哪儿
在传统的内核协议栈中,当有新的数据包到来时,网卡会通过硬件中断通知协议栈,内核的网卡驱动负责处理这个硬件的中断,将数据包从网卡拷贝到内核开辟的缓冲区中,所以协议栈的主要处理开销分为中断处理,内存拷贝,系统调用和协议处理4个方面。
硬件中断:反复中断用户态内核态的上下文切换和软中断都会大大增加额外的开销,并且中断处理程序应尽可能少,只是简单地通过PIO(Programming Input/Output Model)或DMA(DirectMemory Access)等方式协调后把数据包从网卡内存复制到内核开辟的缓冲区中。
内存拷贝:数据先从网卡缓存区通过PIO或DMA方式传送到内核开辟的缓冲区中,然后还要通过socket从内核空间复制到用户空间,统计表明,在Linux协议栈中,数据包从内核态拷贝到用户态所用的时间甚至占到了数据包整个处理流程时间的57.1%。
系统调用:系统调用是内核态向用户态提供的一组API集,系统调用一般通过软中断来实现,会产生较大的上下文切换开销。
协议处理:主要的耗时包括校验、计算、定时器管理、IP分片/重组、PCB连接管理、可靠传输机制和拥塞控制。
在用户空间层次上实现TCP/IP协议栈,选择绕过内核使我们可以采用某些高级的捕获数据包技术(如直接写TAP字符设备或使用Libpcap捕包技术,或性能更高得多的零拷贝捕包技术,这些由于同在用户态中具有相同的特权指令级别,所以在user_buffer和nic_buffer之间可以直接做内存映射,例如virtio application)直接在网卡和用户空间形成通道,减少内存的复制次数。同时,可以按照自己的需求定制协议栈的协议处理流程,简化某些冗余的处理机制,因此,用户态协议栈的可定制性和可扩展性都比内核态协议栈要高。Openonload是Solarflare公司开发的一个专用高性能用户态协议栈,它运行在Linux上,并具有标准的BSD socket API接口,结合该公司开发的专用网卡设备及设备驱动程序,网络数据包得以旁路内核态协议栈,高效地到达用户态协议栈。
在多核CPU硬件结构中,要充分发挥计算能力,必须采用多进程执行,使得同一时刻都有一个线程(用户线程,内核线程,硬件线程)运行在一个CPU核上。
对于用户态协议栈的构建,可以分为两种模式:一种是用户程序与协议栈分别作为独立的进程,互相之间通过IPC通信;另一种方式是将用户程序和协议栈作为一个进程空间的两个现成实现,假如选择系统开销更小的线程来实现的话,用户态无法像在内核态一样使用中断来进行驱动,用户态的协议栈的数据来源也两种(网络数据包和socket请求),它们本质上都可以看成是消息,因此,用户态的驱动机制可以成为消息驱动机制。
对于基于传统的全虚拟化网卡技术+传统的Hypervisor+传统的Linux内核技术实现云环境,其中一个虚拟机到物理网卡会存在如下的性能开销:
VM,在基于传统的Hypervisor技术中VM是宿主机用户空间的一个进程。在Linux中,一般使用TAP设备作为虚拟网卡,TAP设备在用户空间会有一个字符设备供虚拟机进程读写。
Hypervisor层横跨用户空间和内核空间,这中间会存在数据在内核空间和用户空间的拷贝及切换。
内核网桥再访问物理网卡。
我们看到了网络性能的主要开销在哪里,那么提升性能的方法是如图1-1所示的减少这些层级,下面我们将更详细地展开介绍。

图1-1
2 网络加速设计核心思路
本章节针对上一节网络性能瓶颈的分析,总结两类解决方案,并试着论述其设计核心思路。
第一类为用户态驱动方式,设计概要如下:
将外设IO映射到用户态,让用户态程序可直接访问外设。 这样就避免了内核协议栈的干扰,以及内核态用户态间的内存拷贝开销;
改中断方式收包围查询式收包。当然也可权衡采用一次中断多次查询的方式,在性能和cpu占用率间作出一定的平衡;
预分配buffer。在用户态实现一个buffer cache池,用于填充到硬件。如果硬件支持自释放buffer,此处的设计会更简单;
线程绑定到特定核,避免线程调度带来的时延以及开销。
用户态驱动的性能相比内核态驱动可以提升一大截,基本可满足10G甚至更高的要求。但这类方案也存在一定的弊端:
用户态需要实现一套简单的协议栈,某种程度上会加大工作量
系统健壮性及安全性有一定的降低。用户可直接访问并控制外设。系统入侵成本太低,因此并不适合一些开放式的应用场景。
第二类为基于内核态驱动的优化改造,比较典型的为netmap方案(此次不展开将这个开源项目的细节,只从设计思想进行概括)。以netmap为例:
实现静态预留buffer,避免动态申请释放buffer内存;
采用查询式收报(由用户态发起查询,内核态配合完成);
采用批处理的方式,一次查询完成多个收包处理,分摊查询所带来系统调用的开销。如系统调用开销为100ms,若一次收10个包,则分摊到每个包的开销为10ms;
实现用户态和内核态的贡献内存,作为buffer。这样只需要在内核态跟用户态间传递指针或偏移量即可,无须拷贝内存(Zerocopy)。
同时用户态驱动所实现的线程绑定技术也需要应用到这里来。这类方案比用户态驱动的优势在于:
用户态无法访问外设,增加了安全性;
性能远高于传统内核态驱动,略低于用户态驱动,但可满足线速的需求;
某些时候可借用内核的协议栈。可在性能和功能完整性间比较灵活地切换。
3 虚拟化技术回顾
3.1 QEMU全虚拟化
传统的KVM实现中,kvm.ko是内核的一个模块主要用来捕获虚机的是上述的针对CPU、内存MMU的特权指令然后负责模拟,对I/O的模拟则是再通过用户态的Qemu进程模拟的,Qemu负责解释I/O指令流,并通过系统调用让Host操作系统上的驱动去完成真正的I/O操作。这其中用户态与内核态切换了2次,数据也需要复制2次。如图3-1
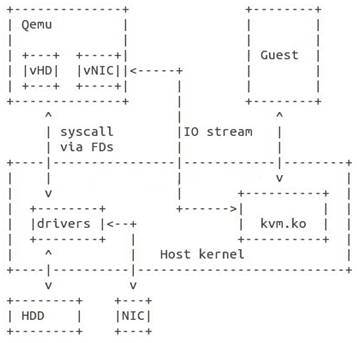
图3-1
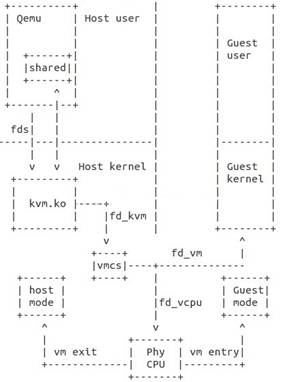
图3-2
全虚拟化下一个完整的数据包从虚拟机到物理网卡的路径是:虚拟机—>QEMU虚拟网卡—>虚拟化层—>内核网桥—>物理网卡。

图3-3
其网络优化方案,总的思路就是让虚拟机访问物理网卡的层数更少,直至对物理网卡的独占,和物理机一样使用物理网卡,以达到和物理机一样的网络性能。
全虚拟化网卡不需要改动虚拟机操作系统,Hypervisor层直接通过软件模拟实现一些通用操作系统都支持的常用网络驱动,如e1000、intel82545的等。这种通用性好一些,但性能不高。
3.2 virtio
解决全虚拟化网卡效率地下的一个办法就是使用半虚拟化驱动程序virtio。要使用virtio必须要在宿主机和虚拟机中分别安装virtio驱动,这样虚拟机的I/O就可以以virtio的标准接口来进行,而虚拟化引擎不需要捕捉这些I/O请求,这样就大大提高了性能。其思想是宿主机和虚拟机操作系统同时改动配合提升性能,其架构如图3-4所示,前端驱动(如virtio_pci,virtio_net等)存在于虚拟机中(所以虚拟机操作系统 要改动和安装virtio专用驱动,Linux kernel从2.6.24开始支持virtio,Window虚拟机需要额外安装virtio的Window版驱动即可),后端驱动virtio backend存在于QEMU内核模块中(所以宿主机操作系统也要改动),中间的virtio是队列,virtio-ring是共享的环形缓冲区。
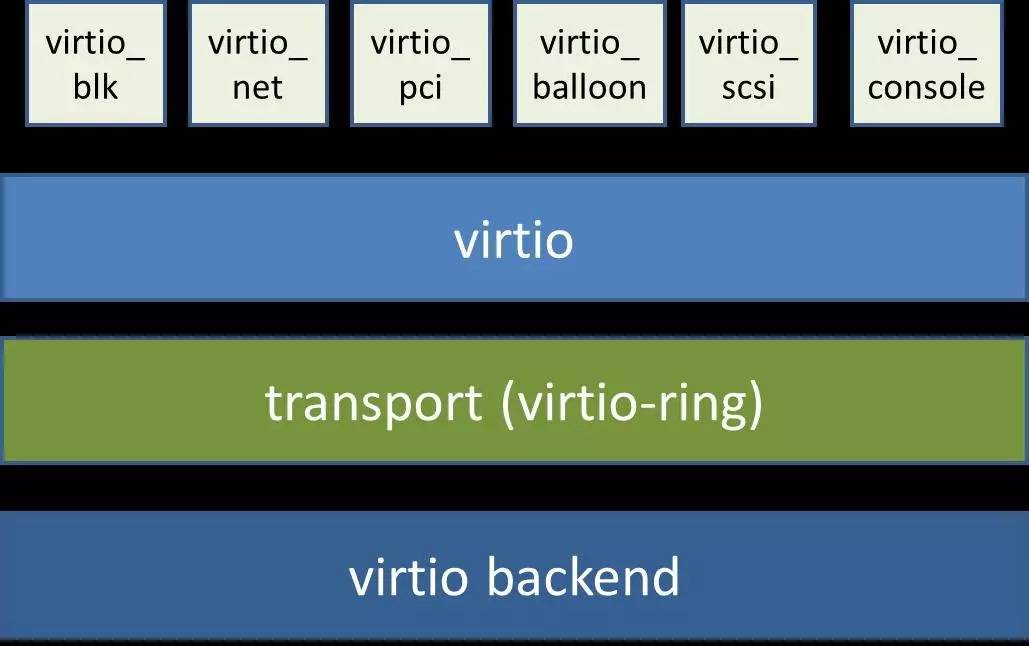
图3-4 virtio架构
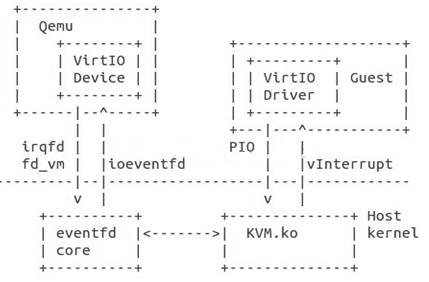
图3-5
virtio的网络数据流如图3-6所示,其网络性能仍存在两个瓶颈:
用户态的guset进程通过virtio driver(virtio_net)访问内核态的KVM模块(KVM.ko),需要用户态和内核态切换一次,数据在用户态和内核态之间拷贝一次。
内核态的KVM.ko并不能直接访问同在内核态的TAP设备,先需要一次从内核态到用户态的切换,再通过用户态的QEMU进程在去访问TAP设备在用户态的字符设备接口,又得切换一次和进行一次数据拷贝。
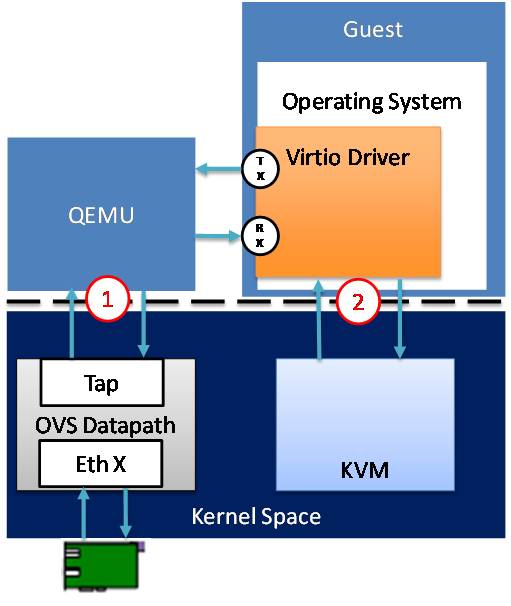
图3-6 virtio的网络数据流及性能瓶颈
3.3 vhost-net
Virtio通过共享内存减小了Guest与Qemu之间数据复制的开销,但Qemu到内核的系统调用还是跑不了。有必要将模拟I/O的逻辑将Virtio Device挪到内核空间避免系统调用。
vhost在内核态再增加一个vhost-net.ko模块, vhost client与vhost backend通过共享内存(virtqueues, unit socket), 文件描述符(ioeventfds),(中断号)irqfds实现快速交换数据的机制。
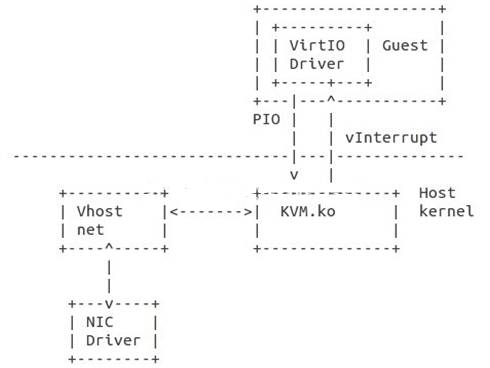
图3-7
vhost的架构如图3-8所示,vhost实际上是两个进程之间通过共享内存实现通信的机制,它不仅可以在两个进程之间共享内存,还能通过unix socket在两个进程之间传递共享内存的文件描述符(ioevenfds)和中断号(irqfd),这样实现了两个进程之间的零拷贝(Zero Copy)。我们知道,在virtio架构中,虚拟网卡的数据缓冲区就是virtio-ring,通过vhost机制实现了数据的零拷贝。
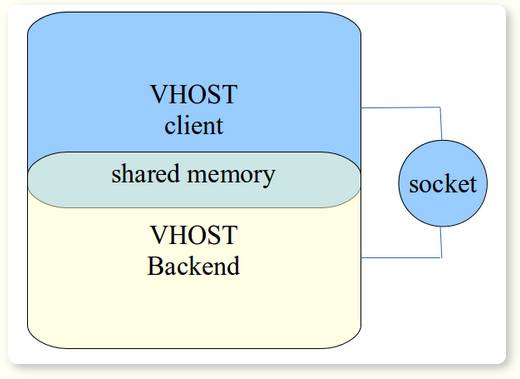
图3-8 vhost架构
vhost的网络数据流如图3-9所示,在内核态增加了一个vhost驱动,与virtio相比,只需要进行一次用户态内核态切换(因为内核态的vhost-net.ko可以直接访问内核态的TAP设备,少了一次切换),另外,由于引入vhost技术共享了虚拟机的网卡缓冲区也省了一次数据拷贝(vhost-net.ko充当vhost backend,kvm.ko充当vhost client)。
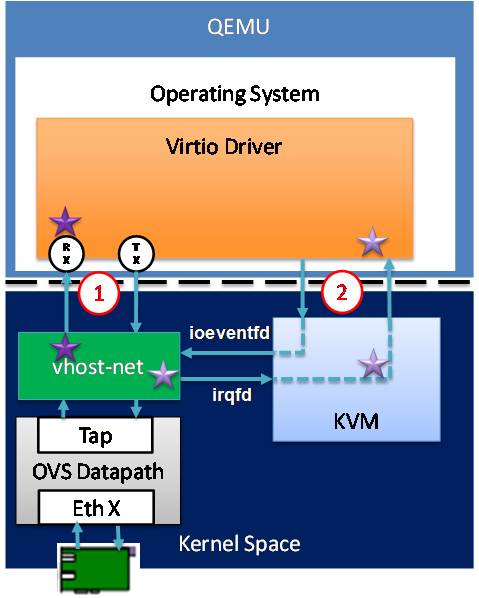
图3-9 vhost网络数据流及性能瓶颈。
3.4 vhost-user
vhost技术相比virtio省了一次切换和拷贝,那么如图3-9所示vhost-user将vhost驱动挪到了用户态实现零切换和零拷贝。一些实现了vhost backend的交换机(如snabbswitch)直接在用户态从vhost共享的虚拟机网卡缓存区virtio-ring中把网络数据进行读取,然后snabbswtich又实现了SR-IOV的物理网卡驱动直接将读到的虚拟机网络数据送到物理网卡上,从而大大提升了性能。所以基于vhost-user或者snabbswtich的技术甚至连虚拟网卡TAP设备都省了。
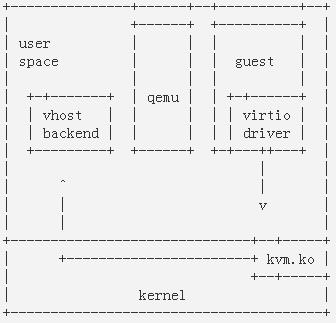
图3-10 vhost-user网络数据流及性能瓶颈
snabbswitch 是一个Lua网络框架,主要用来写 L2 应用。它可以完全接管一个网卡,并且在用户空间实现硬件驱动。它在一个 PCI 设备上实现了用户空间 IO(UIO),把设备寄存器映射到 sysfs 上(译者注:sysfs 是Linux 内核中设计较新的一种虚拟的基于内存的文件系统) 。这样就可以非常快地操作,但是这意味着数据包完全跳过了内核网络协议栈。
snabbswitch是类似于Openvswitch的虚拟交换机,区别在于snabbswitch更重视性能。首先它是一个基于vhost-user的虚拟交换机应用,具有零拷贝和不走内核的特点;其次它实现了物理网卡驱动(目前只实现了一种驱动即intel10g.lua,支持Intel 82599 10-Gigabit芯片网卡)直接调用SR-IOV的硬件网卡的Tagging,Security等功能将由Neutron软件实现的改由硬件实现。基于这两个特点,snabbswitch的性能相当高。
vhost-user是qemu 2.1版本引入的新特性,使用方式如下:
$ qemu-m 1024 -mem-path /hugetlbfs,prealloc=on,share=on \
-netdev type=vhost-user,id=net0,file=/path/to/socket\
-device virtio-net-pci,netdev=net0
-mem-path选项支持为一个虚拟机分配和其他进程的共享内存vring,vring也就是虚拟机的虚拟网卡的缓存区。
再通过unix socket将vring的文件描述符,中断号,IO事件等传给同在用户空间的snabb app进程。
snabb app进程就可以直接通过文件描述符去vring中获取网络数据来了。
可以看出这种机制是不需要内核中的TAP设备的从而绕开了kernel,也是不需要再走QEMU的内核空间的从而绕开了QEMU。
qemu的vhost-user特性
vhost是一种用户空间进程(vhost client与vhost backend)通过共享内存(virtqueues, unit socket), 文件描述符(ioeventfds), (中断号)irqfds实现快速交换数据的机制。其架构是:
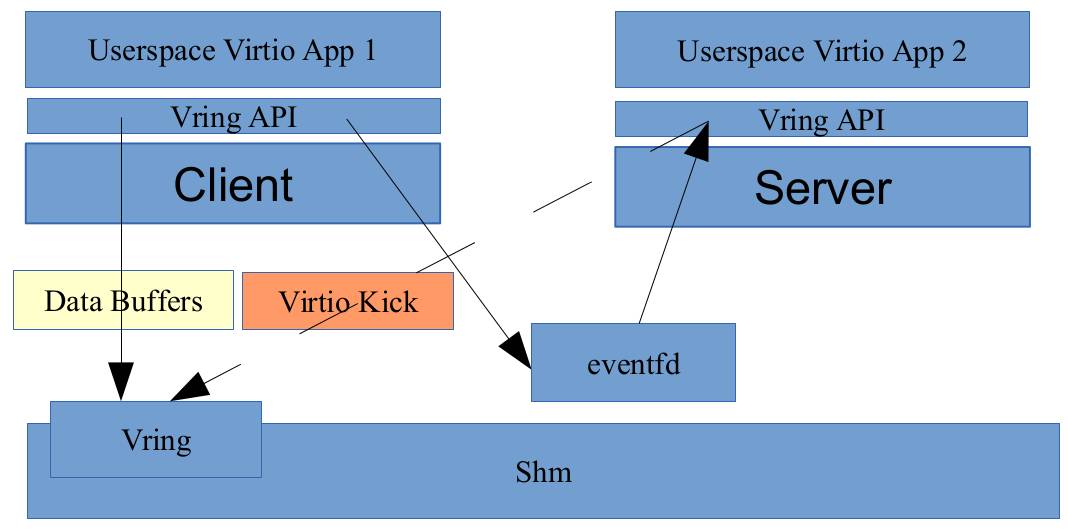
图3-11
vhost backend是一个userspace virtioapplication, 它能绕开kernel,和同样是usersapce的VM虚机进程直接通过共享内存实现zero-copy大大地提升性能;另一方面,kernel也会基于vhost技术为每个vring设备分配独立的中断号、事件中断、文件描述符等,并将这些通过unix socket传给其他用户空间进程,这样vhost backend并能直接访问虚机网卡的文件描述符。
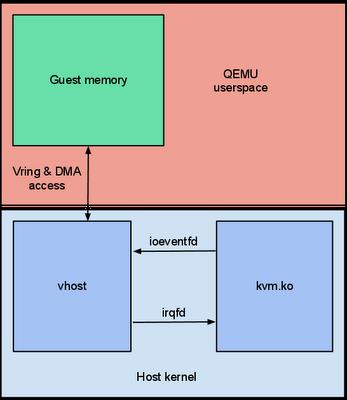
图3-12
3.5 DPDK(Data Plane DevelopmentKit)[3]
DPDK是一个用 C 语言实现的网络框架,专门为 Intel 芯片创建。它本质上和 snabbswitch 类似,因为它也是一个基于UIO 的完整框架。
DPDK便是一个在用户态可以直接操作物理网卡的库函数,它和vhost-user结合便可以实现类似于snabb switch一样性能强劲的用户态交换机了。2015年6月16日dpdk vhost-user ports特性合并到了ovs社区[1], dpdkvhostuser port将创建unix socket将虚机的virtio-net虚拟网卡的网卡缓冲区共享给物理机上的ovs port设备。
1.DPDK特性
图3-13
1)参考传统NP、多核处理器报文收发处理架构;
2)X86架构上纯用户态驱动;
3)R2C( run to completion )模型;
4)内存资源预先分配:Buffer/队列资源;
基于mempool机制、 mbuf机制
环形队列:无锁设计
巨页机制:物理空间连续
IVSHM
Qemu Patch:
支持ivshm
支持巨页
5)Executionunits:不支持调度。类似deadloop方式(可绑定逻辑核);
6)PMD驱动,通过DMA实现零拷贝,不使用中断;
Intel 1G/10G网卡;
部分非Intel网卡支持;
VIRTIO/VMWARENET3半虚拟化网卡。
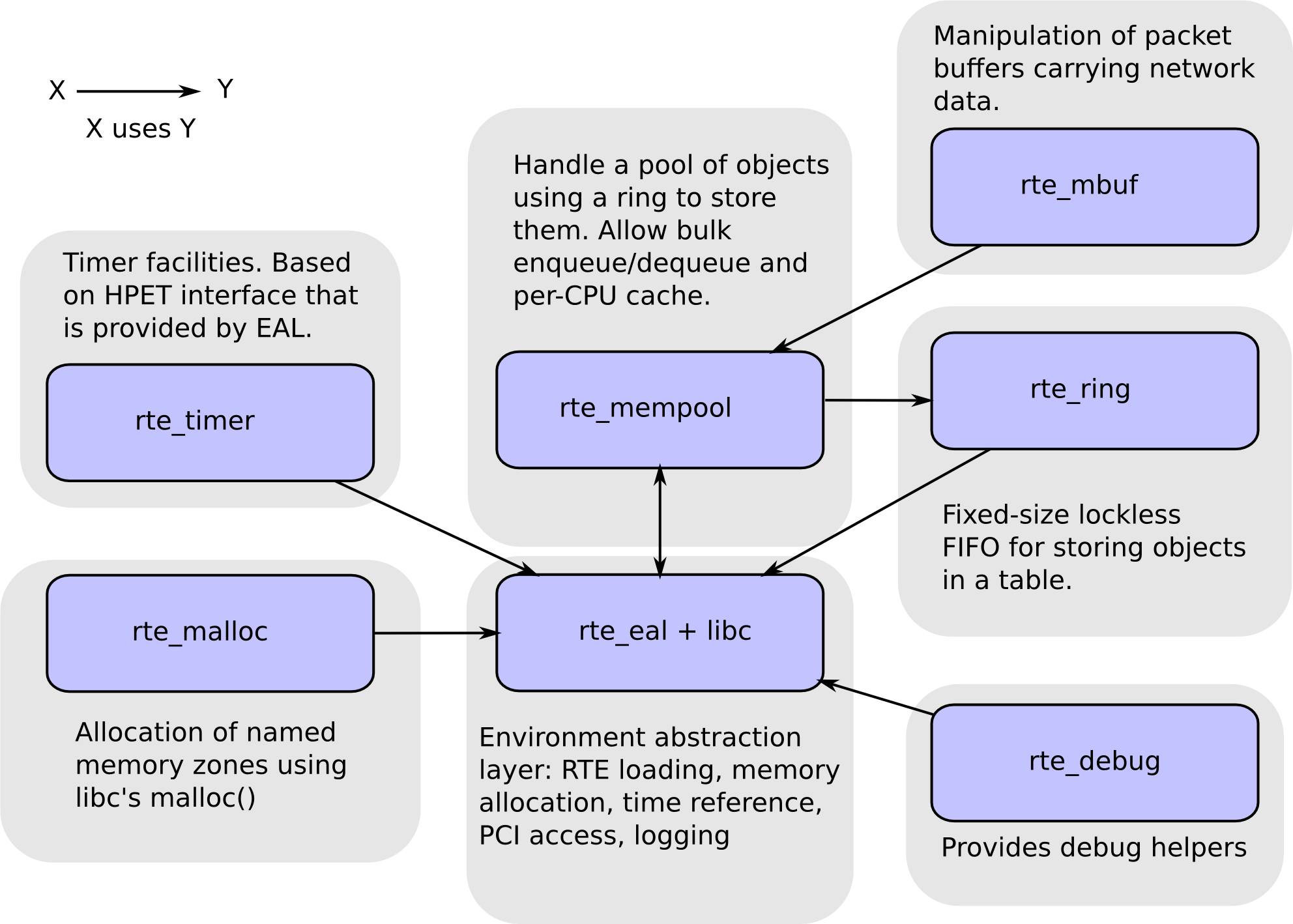
图3-14
7)硬件网卡多队列、分类、QoS及卸载功能;
8)支持非虚拟化、虚拟化场景。
2.DPDK的前端加速
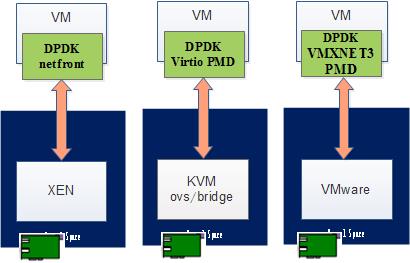
图3-15
非SR-IOV时:
VM仍可使用DPDK+PMD加速;
支持不同云平台XEN/KVM/Vmware。
3.结合dpdk+vhost-cuse+virtio加速
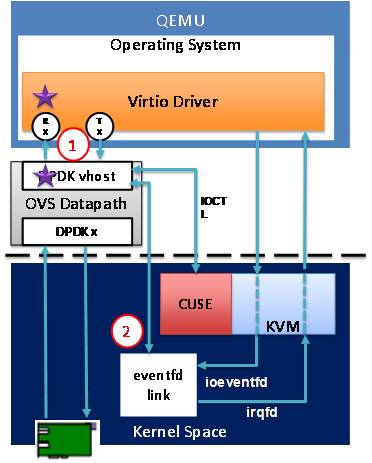
图3-16
Vhost-Cuse
基于DPDK的用户态OVS
后端使用Vhost-Cuse
不使用tap设备、不走Qemu内核部分
前端可使用virtio pmd驱动进一步提升性能
结合dpdk+pmd(ivshm)加速
4.结合dpdk+pmd(ivshm)加速
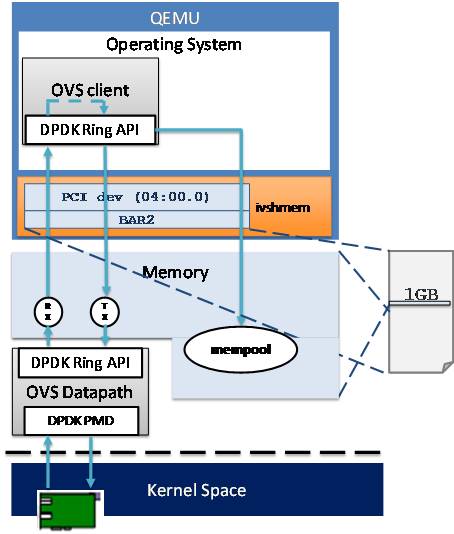
图3-17
IVSHM(Inter-VM shared memory device)模型,性能最高
Guest使用PMD驱动;
使用IVSHM;
基于DPDK的用户态OVS;
报文全程零拷贝。
5.OVS DPDK架构
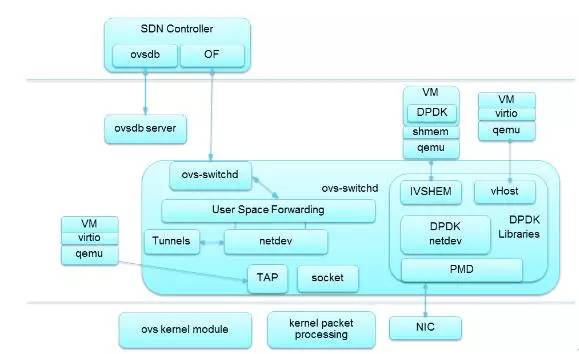
图3-18 OVS DPDK架构
支持轻量型协议栈;
兼容virtio,vhost-net和基于DPDK的vhost-user加速技术;
支持Vxlan功能、端口Bonding功能;
支持OpenFlow1.0&1.3;
支持Meter功能、镜像功能;
支持VM热迁移功能;
性能较内核OVS可提升8~9倍。
6.DPDK的优势及问题
优势:
转发性能高,尤其是短包转发性能、较内核OVS可提升8~9倍以上。
问题:
主要支持Intel网卡,其他网卡支持的较少;
对OVS-DPDK而言,旁路内核Datapath,功能较内核缺失。需要在用户态下开发;
IVSHM的安全性需要关注。热迁移功能难以实现;
vSwitch会消耗宝贵的CPU资源。
3.6 Netmap
1.Netmap简介
Netmap是一个高性能收发原始数据包丰富的网络框架,由LuigiRizzo等人开发完成,但是和 UIO 技术不同,它是由包含了几个内核模块来实现的,为了和网络硬件集成在一起,用户需要给内核网络驱动打补丁。其目标是不用修改现有操作系统软件以及不需要特殊硬件网卡支持,实现用户态和网卡之间数据包的高性能传递。其原理图如下,数据包不经过操作系统内核进行处理,用户空间程序收发数据包时,直接与网卡进行通信。
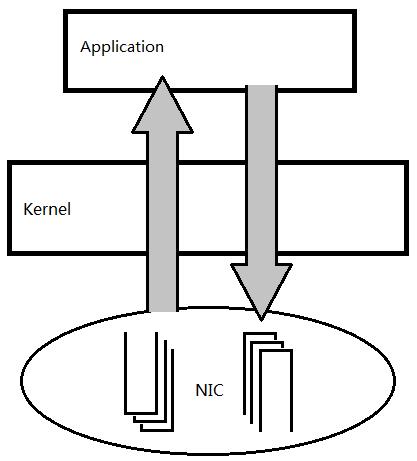
图3-19 netmap原理图
2.数据结构
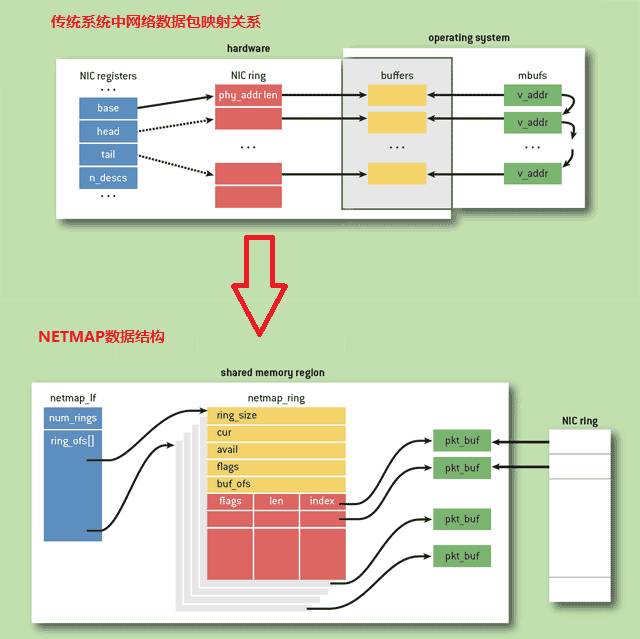
图3-20
在Netmap框架下,内核拥有数据包池,发送环/接收环上的数据包不需要动态申请,有数据到达网卡时,当有数据到达后,直接从数据包池中取出一个数据包,然后将数据放入此数据包中,再将数据包的描述符放入接收环中。内核中的数据包池,通过mmap技术映射到用户空间。用户态程序最终通过 netmap_if获取接收发送环netmap_ring,进行数据包的获取发送。
3.特点总结
1)性能高:数据包不走内核协议栈,不需要层层解析,用户态直接与网卡的接受环和发送环交互。性能高的具体原因有一下三个:
批量处理数据包可以减少了系统调用,处理数据包的时间花费少。
不需要进行数据包的内存分配:采用数据包池,当有数据到达后,直接从数据包池中取出一个数据包,然后将数据放入此数据包中,再将数据包的描述符放入接收环中。
数据拷贝次数少:内核中的数据包采用mmap技术映射到用户态。所以数据包在到达用户态时,不需要进行数据包的拷贝(zero copy)。
2)稳定性高:有关网卡寄存器数据的维护都是在内核模块进行,用户不会直接操作寄存器。所以在用户态操作时,不会导致操作系统崩溃。
3)亲和性:可采用了CPU亲和性,实现CPU和网卡绑定,提高性能。
4)易用性好:API操作简单,用户态只需要调用ioctl函数即可完成数据包收发工作
5)与硬件解耦:不依赖硬件,只需要对网卡驱动程序稍微做点修改就可以使用此框架(几十行行),传统网卡驱动将数据包传递给操作系统内核中协议栈,而修改后的数据包直接放入Netmap_ring供用户使用。
4.应用场景
1)抓包程序
2)高性能发包器
3)虚拟交换机:虚拟交换机场景下,使用Netmap可以实现不同网卡间高效数据转发,将一个网卡的数据放到另外一个网卡上时,只需要将接收环中的packet的描述符放入发送环,不需要拷贝数据,实现数据包的零拷贝。
3.7 Openonload[7]
snabbswitch、DPDK和netmap网络加速技术用在云计算的业务转发面一般都是独占接管用于转发面的网卡,不允许网卡的任何流量经过内核。而Solarflare的开源项目Openonload提供另外一种解决方案。
Openonload是一个用户态的TCP/IP协议栈,相比于snabbswitch它具有更丰富的物理网卡驱动(libcuil.so),snabbswitch是直接和二层帧打交道,而Openonload则直接提供了用户态的TCP/IP协议栈,并提供了标准的BSD socket接口,这样就可以直接支持上层应用,通用性更好。如图7-7所示Openonload的架构。
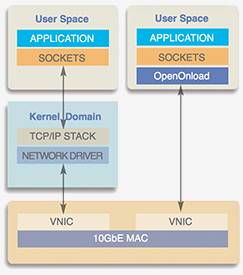
图3-21 Openonload架构
Solarflare 网卡支持Openonload,它通过如图3-21的方式来实现内核旁路,在用户空间实现网络协议栈,并使用 LD_PRELOAD 覆盖目标程序的网络系统调用。在底层访问网卡时依靠 “EF_VI” 库。这个库可以直接使用并且有很好的说明文档。[8]
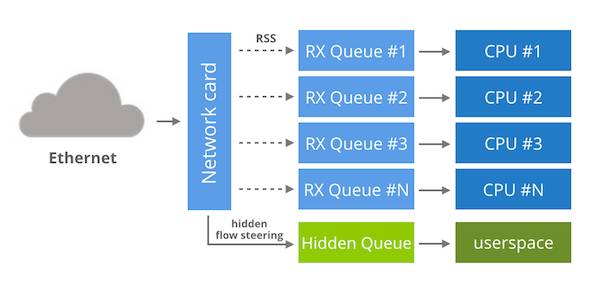
图3-22 Openonload内核旁路示意
EF_VI 作为一个专用库,仅能用在 Solarflare 网卡上,你可能想知道它实际是如何工作的。 EF_VI 是以一种非常聪明的方式重新使用网卡的通用功能。在底层,每个 EF_VI 程序可以访问一条特定的 RX 队列,这条 RX 队列对内核不可见的。默认情况下,这个队列不接收数据,直到你创建了一个 EF_VI“过滤器”。这个过滤器只是一个隐藏的流控制规则。你用 ethtool -n 也看不到,但实际上这个规则已经存在网卡中了。对于 EF_VI 来说,除了分配 RX 队列并且管理流控制规则,剩下的任务就是提供一个API 让用户空间可以访问这个队列。
虽然EF_VI 是 Solarflare 所特有的,其他网卡还是可以复制这个技术。首先我们需要一个支持多队列的网卡,同时它还支持流控制和操作间接表。
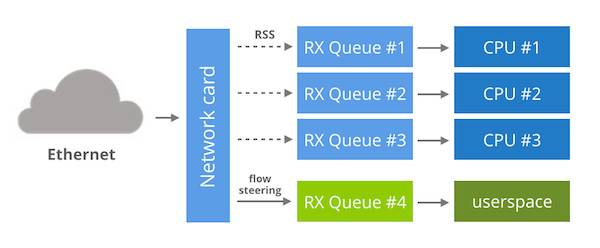
图3-23 分叉驱动内核旁路示意
有了这些功能,就可以做以下事情:
正常启动网卡,让内核来管理一切。
修改间接表以确保没有数据包流向任一RX 队列。比如说我们选择4号 RX 队列。
通过流控制规则将一个特定的网络流引到4号 RX 队列。
完成以上这些,剩下的步骤就是提供一个用户空间的 API ,从4号RX队列上接收数据包,并且不会影响其他任何队列。
这个想法在 DPDK 社区被称为“分叉驱动”。它们打算在2014年创建分叉驱动[9],不幸的是这个补丁还没进入内核的主线。
实现以上这个方案后,就可以将业务转发面和存储面合设在同一个网络平面,因为存储面目前使用都是传统VLAN网络,前提是合设的物理网络平面网卡不能被全部接管而对其他的网络流量应用不可见。
4 基于DPDK 用户态的OVS性能测试
1.软硬件测试环境
1、服务器:华为RH2288H V2存储服务器,规格
1)CPU:E5-2620 v2
2)内存:256G
3)硬盘:SSD 300G、数据盘SATA 4T
4)网卡:Intel 82599 2*10 Gigabit
2、测试仪:
Spirent物理测试仪,版本是4.45
3、被测试自研优化的OVS版本:OVS-1.1.10
2.单机性能测试结果
虚拟交换机是性能得到优化用于Overlay的OpenFlow SDN架构云数据中心,需要虚拟化交换机支持VxLAN和OpenFlow,本次性能测试是在SDN架构下的VxLAN大二层环境下测试的结果。
1、VXLAN隧道数量:10667条vxlan隧道
2、VNI数量:350000个VNI
3、MAC表容量:15000个MAC
4、VxLAN转发性能如下:
1VM |
4VM |
6VM |
|||||
PPS |
带宽(Mbps) |
PPS |
带宽(Mbps) |
PPS |
带宽(Mbps) |
||
128 |
单流 |
274355 |
320 |
653746 |
770 |
1021211 |
1200 |
512 |
182049 |
770 |
597685 |
2540 |
895388 |
3800 |
|
1024 |
187008 |
1560 |
531861 |
4440 |
750891 |
6200 |
|
1518 |
178362 |
2190 |
532352 |
6550 |
669144 |
8200 |
|
5 业界虚拟交换机加速方案对比
Ericsson:基于DPDK的vSwitch
HP:基于WindRiver
VMware:私有vSwitch(非OF交换机)
WindRiver/6Winds:均基于DPDK的vSwitch
Huawei:基于DPDK、Netmap
iNIC:EZChip/BRCM/Netronome…
6 虚拟交换机面临的问题
在Openstack下的东西向安全组和南北向防火墙基于kernel中iptables实现的,在vhost-user实现方案中,iptables便失去应有的功能,采用用户态虚拟化交换机后,由于数据包不经过kernel协议栈,Security group,ACL等的功能如何实现?是否可以直接在网卡驱动或用户态虚拟机化交换机上进行实现,或者SDN方案架构下通过OpenFlow流表实现?
数据包到达用户态后,由于是原始数据包,用户态是否有类似于TCP/IP协议栈的功能的应用进行协议栈解析?
在10Gb甚至40Gb普遍的云计算组网中,为了减少大量光纤布线要求,往往需要将传统上业务平面、管理平面、存储平面两个网络平面设置三个网络平面合设情况下,同时在不同平面上运行这不同二层封装协议。比如基于VxLAN虚拟化大二层SDN架构的云计算平台业务转发面和管理面,存储面是VLAN封装合适情况,如何避免网络虚拟化软件接管物理网卡引起对其他应用不可见该物理网卡,比如是不是可以借鉴solarflare的Openonload上实现的“分叉驱动”,DPDK社区就一个尝试[9]。
纯用户态网络虚拟技术,用户可以直接访问控制物理网络设备,系统健壮性及安全性有一定的降低,系统入侵成本太低,安全性就比较难以控制,因此并不适合一些开放式的应用场景。
虚拟机网络流量监控管理的问题,目前虚拟化交换机运行在计算节点服务器内部,虚拟机之间网络流量监视,管理界限模糊,随着VM和vSwtich激增管理也是一个难题,针对这个情况IEEE标准定义了802.1qbg和802.1qbh(现由802.1BR替代)来解决这些问题,802.1qbg由HP等公司联合提出,802.1BR由Cisco和VMWare等联合提出,相关详细介绍可以通过搜索获取。暂且不说802.1qbg和802.1BR各自背后的利益主导权之争,虚拟化交换机对两个协议支持,也是需要解决的问题。
参考文档:
[1]https://github.com/openvswitch/ovs/commit/7d1ced01772de541d6692c7d5604210e274bcd37
[2]Qemu内幕介绍,http://blog.csdn.net/wj_j2ee/article/details/7978259
[3]https://software.intel.com/en-us/blogs/2015/06/09/building-vhost-user-for-ovs-today-using-dpdk-200?language=ru
[4]http://blog.csdn.net/haitaoliang/article/details/22753423
[5]https://software.intel.com/en-us/blogs/2015/06/09/building-vhost-user-for-ovs-today-using-dpdk-200
[6]netmap源码网址:http://info.iet.unipi.it/~luigi/netmap/
[7]http://www.openonload.org/
[8]https://support.solarflare.com/index.php?option=com_cognidox&file=SF-114063-CD-1_ef_vi_User_Guide.pdf&task=login&Itemid=11&id=
[9]http://events.linuxfoundation.org/sites/events/files/slides/LinuxConEurope_DPDK-2014.pdf
分享讨论实录
.讲的太棒了,一时难以消化。问个基本问题,在同一个hypervisor里面的两个vm网络通信,会通过物理网卡吗?谢谢
启用802.1qbg的发卡功能,是需要通过物理网卡上传到TOR交换机再返回来的。
有个慢通道和快通道。还有就是为了更好监控VM的流量,如果在802.1qbg上的,会到交换机上绕一下的。
不过现在大多少虚拟化交换机不支持802.1qbg,所以使用快通道的话,同物理主机上的VM直接通过内核共享内存传递数据。不需要经过物理网卡。
但是如果是慢通道的话,需要走完一个完整流程,需要通过物理网卡的。
------------------------
好消息!2016年全球运维大会.深圳站门票专属优惠码(折上折)
特别提供KVM社区的专属优惠码:
KVM88XIAOLIVIP5大家在购票时,输入上述优惠码,就可以尽享88折,适用所有门票,有效期截止2016年1月14日(含)。
实名制群分享由迅达云协助完成

迅达云(SpeedyCloud)致力于为用户提供『一站式云服务』
KVM社区群分享奖品由华章科技学院支持电子读书卡
一卡读尽所以华章电子书!
---------------------------
欢迎加入“云技术实名群”,入群要求如下:
1 工作满5年;
2 目前从事云相关技术工作;
3 实名;
4 愿意分享。
入群联系北极熊:
以上是关于重磅:虚拟化交换机性能优化探讨实录@KVM社区实名制群的主要内容,如果未能解决你的问题,请参考以下文章