数据虚拟化环境设计步骤分解(上篇)
Posted 敏捷大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据虚拟化环境设计步骤分解(上篇)相关的知识,希望对你有一定的参考价值。

**数据虚拟化设计思想是敏捷大数据理念的重要组成部分,敏捷大数据团队也研发并推出了数据虚拟化开源实现—计算服务平台Moonbox。为了让大家更加了解数据虚拟化技术,我们会陆续推荐并翻译一些精品文章。欢迎大家一起交流探讨。
导读:文章译自Designing a Data Virtualization Environment - A Step-By-Step Approach(by Rick F. van der Lans),译文分上、中、下三篇向大家介绍基于社区项目Teiid,利用Red Hat的JBoss数据虚拟化服务器,如何逐步设计出数据虚拟化环境。在上篇中,我们首先了解一下具体的背景情况,包括数据虚拟化解决方案的总体架构,几种设计方法的选择以及对样例数据库的介绍。具体内容请看正文~
上篇
摘 要
本文介绍了一种基于社区项目Teiid,利用Red Hat JBoss数据虚拟化(JDV)服务器逐步构建数据虚拟化环境的方法。文中包括一些注意事项和设计准则,帮助企业组织开发有效且高效的数据虚拟化环境。
文中所推荐的设计架构包含四层视图(views):
虚拟基础层视图,负责接入存储在源系统中的数据,与数据质量有一定关系。
企业数据层视图,提供所有源系统数据的一个集成视图。
共享规范层视图,包含共享规范,避免数据消费视图中出现重复或者相互矛盾的规范。
数据消费层视图,简化数据消费者的数据访问。
此外,本文还推荐采用纵向设计和开发的方式,即在本层中确定少量视图之后,就可以开始定义下一层视图。纵向设计方式非常适合当前快速迭代开发的敏捷设计技术;同时,它还适用于现代数据仓库,现代数仓的要求便是更快地开发以及更快的更改现有报表。
开发一个新的JDV环境或者改变现有的JDV环境包括以下步骤:
1. 设计并实现虚拟基础层
2. 设计并实现企业数据层
3. 设计并实现共享规范层
4. 设计并实现数据消费层
5. 设计并实现自助使用视图
6. 设计并实现数据质量管理视图
7. 优化性能
我们并不是要逐个执行实施这7步,而是要把其看做一个快速迭代的过程。
注:Red Hat JBoss 数据虚拟化(JDV),是一种数据供应和整合解决方案,它处于多个数据源的前端,并将这些数据源作为单个数据源进行处理,以符合业务需求的形式、在正确的时间,向任意应用程序或用户提供所需数据。
参考:https://www.redhat.com/zh/technologies/jboss-middleware/data-virtualization
数据虚拟化解决方案
的总体架构
条条大路通罗马。同样,设计开发JDV环境也有许多方法。但无论采用哪种方法,我们始终推荐至少包含四层视图的分层架构(见图1)。
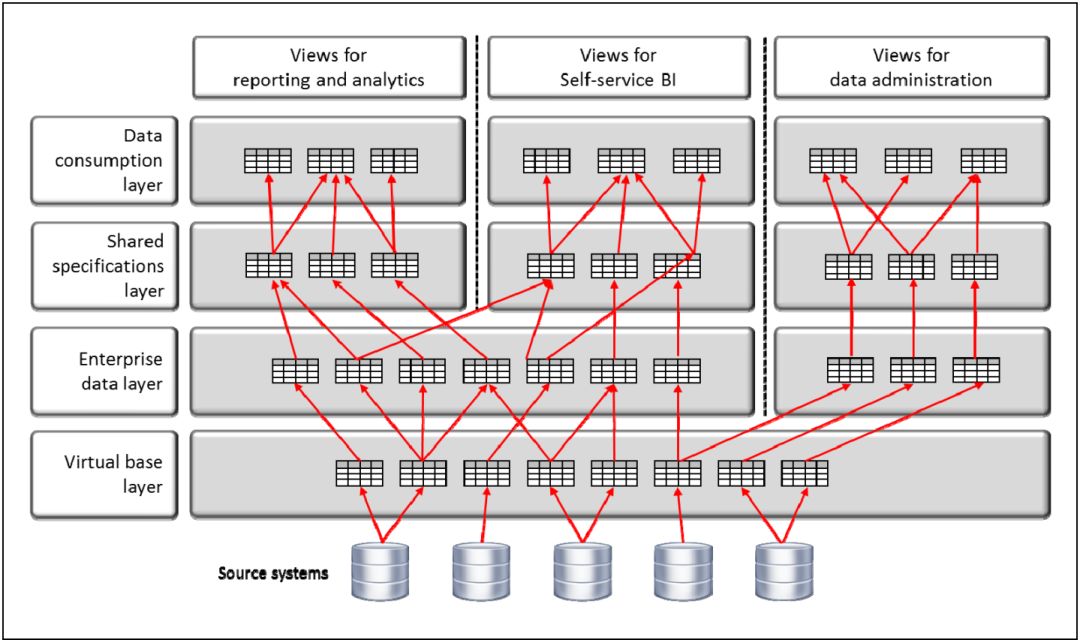
图1 包含四层视图的JDV环境
虚拟基础层链接到源系统,如SQL和NoSQL数据库,基于SOAP / REST的服务,云应用程序以及JSON或XML格式的文件等。虚拟基础层还负责运用清洗规则,提高数据质量。 数据消费者(应用程序、报表和用户)通过访问数据消费层视图来检索数据,所有层都参与转换和重组数据以满足数据消费者的需求。
在这个架构中,每一个视图层都有自己的作用(从底层开始):
虚拟基础层(Virtual Base Layer):虚拟基础层中的视图包含存储在源系统中的数据。我们为源系统中的每个物理表或文件都创建一个视图,每个视图定义都可能包含清洗规范,从而提高源系统数据的质量。除了修正数据之外,这层视图的虚拟内容与源系统的内容相同。
企业数据层(Enterprise Data Layer):第二层的视图提供了源系统中所有数据的集成视图,因此称为企业数据层。每个视图的结构都是“中性的”,换句话说,它不针对某个数据消费者的需求,而是支持尽可能多的使用形式。如果可能的话,每个视图都根据第三范式构建。
共享规范层(Shared Specifications Layer):为避免数据消费视图中存在太多重复或可能相互矛盾的规范,第三层主要包含共享规范。共享规范层存在的目的是避免重复规范,构建尽可能敏捷的环境。共享规范层也可以包含授权规范(允许谁使用哪个视图)。
数据消费层(Data Consumption Layer):数据消费层每个视图的结构侧重于简化数据消费者的数据访问。例如,某些数据消费者希望将数据组织为星型模式,而另外一些数据消费者则希望能够在一个包含大量列的视图中查看所需的所有数据。在数据消费层指定过滤、映射、转换和聚合等操作,仅向数据消费者展示他们所需的相关数据。
图1还展示了视图的三种使用场景,或者说是使用形式:传统使用形式、自助使用形式以及管理使用形式:
传统使用形式涉及数据消费者对视图的重复使用,这些视图由技术人员设计、开发、测试和管理。在传统的使用形式中,每个视图通常都有多个数据消费者使用,其虚拟内容的数据质量十分重要。
自助使用形式所涉及的视图由用户自己而非技术人员开发。特别是在商业智能领域,报表的自助开发非常流行,其中比较知名的工具有Qlikview、Tableau和Tibco Spotfire。 通过允许用户开发自己的视图,工具自身的自助功能也得以扩展。
管理使用形式涉及的视图由负责数据管理方面(如数据质量和使用)的技术人员开发并为他们所用。例如,有的管理视图可以显示具有错误数据值的记录,有的则可以显示数据消费者在一段时间里使用的不同视图。
自下而上,自顶向下
还是由内及外?
设计开发这四个视图层有几种方法:自下而上,自顶向下和由内及外(见图2)。
自下而上的设计方法(Bottom‐up approach):采用自下而上的设计方法,以源系统的结构为起点,设计出符合数据消费者需求的视图:首先开发虚拟基础层,然后是企业数据层,接下来是共享规范层,最后是数据消费层。自下而上设计方法的挑战来自于源系统的结构:源系统数据结构的设计通常是为了尽可能有效且高效地支持它们自己的应用程序;另外,有些结构是很久以前设计的,经过多次调整,随着时间的推移变得有些非结构化。自下而上的设计方法可能会导致顶层视图的结构更多的受源系统数据结构的影响,而不是根据数据消费者需求而设计。
自顶向下的设计方法(Top‐down approach):采用自顶向下的设计方法,首先要分析数据消费者的信息需求,从而在数据消费层上开发一组视图。接下来,开发共享规范层、企业数据层和虚拟基础层的视图,使数据消费层上的视图起作用。因此,这些层是按照从顶层到底层的顺序设计的,是一种非常实用的方法,数据消费者可以快速访问数据。这种设计方法的风险在于,最终整个环境会产生许多重复或相似的规范,难以组织规范共享,从长远来看,这会降低整个JDV环境的潜在敏捷性。
由内及外的设计方法(Inside‐out approach):采用由内及外的设计方法,首先要设计的是企业数据层。定义企业数据层的视图结构时要尽可能中性(neutral),最大限度的支持数据消费者需求。接下来,定义虚拟基础层上的视图,将视图根据一对一映射到物理表;企业数据层的视图要映射到虚拟基础层的视图上。最后,定义数据消费层的视图。这些视图的结构完全是针对数据消费者的需求而设计。由内及外是首选的设计方法,但在现实工作中,项目开发人员有时会因为种种原因而采用另外两种方法,或单独使用,或组合在一起。
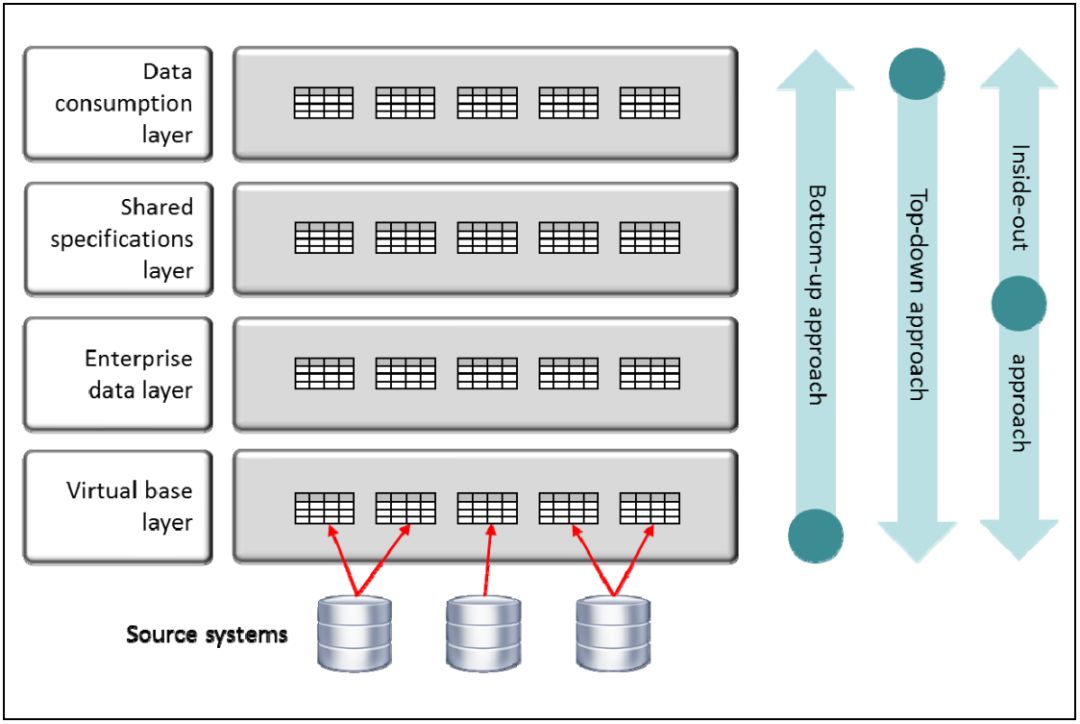
图2 设计开发JDV环境的三种方法
纵向设计?横向设计?
除了在上一节的三种视图设计方法中做出选择,我们还需要决定采用纵向设计方法还是横向设计方法(见图3)。横向设计方法指在设计下一层视图之前,本层的设计和开发应全部完成;纵向设计方法指在设计下一层视图之前,在本层中只需定义少量视图。如果我们使用“迭代”这个术语来形容,采用纵向设计方法,迭代周期会非常之短,而采用横向设计方法,迭代周期可能会非常长。
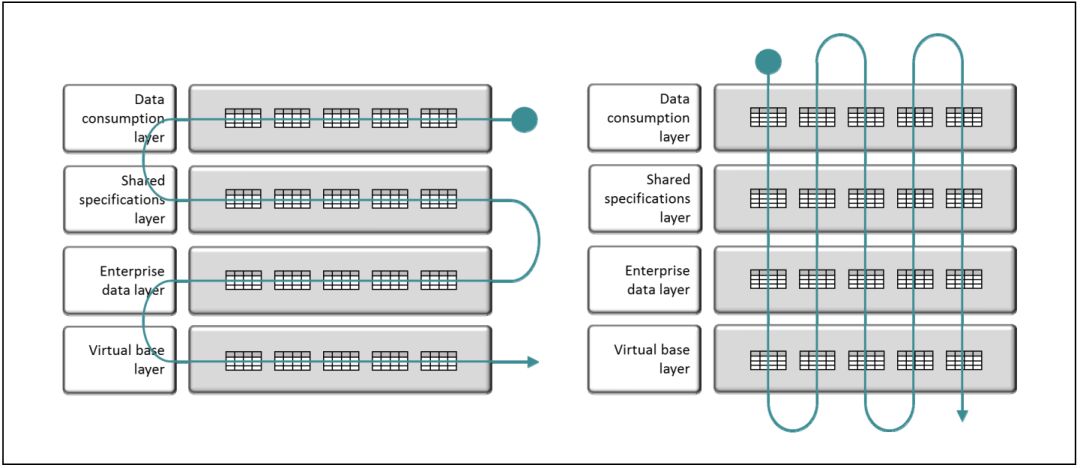
图3 图左为横向设计方法,图右为纵向设计方法
采用横向设计方法,在设计下一个视图层之前,要完成本层视图的设计开发。横向设计方法与企业级方式及“瀑布模型”设计技术相一致,其优点在于更容易得到一组不包含冗余规范或冗余规范最小化的视图。
采用纵向设计方法,在设计下一层视图之前,在本层中只需定义少量视图。纵向设计方法非常适合当前快速迭代开发的敏捷设计技术。此外,它还适用于现代数据仓库,现代数仓的要求是能够更快地开发,更快地更改现有报表。纵向设计方法的总体优势是:高生产率和敏捷的解决方案。如果用户需要来自某个源系统的数据,采用纵向设计可以在最短的时间内定义所需视图。换句话说,纵向设计的反应时间很短。在不考虑与其他系统集成问题的情况下,采用纵向设计方法来开发一份报表只需要几天或几周,而不是几个月。在大多数数据虚拟化项目中,纵向设计方法都因其敏捷性而倍受青睐。
样例数据库
从下一节开始,我们会介绍逐步设计和开发数据虚拟化环境的方法,其中会用到许多例子来详细解释步骤。本文的例子选自同一个样例数据库,它是一家虚拟在线零售公司的产品数据库,公司名为World Class Movies(WCM),提供影片出售和租赁服务。该数据库由一组表组成,表用来记录顾客信息以及销售和租赁信息。
这个数据库是Roland Bouman和Jos van Dongen为他们的书Pentaho Solutions: Business Intelligence and Data Warehousing with Pentaho and mysql所设计。此外,Data Virtualizationfor Business Intelligence Systems一书中也使用了该数据库。本文仅采用了图4数据模型中所显示的表。
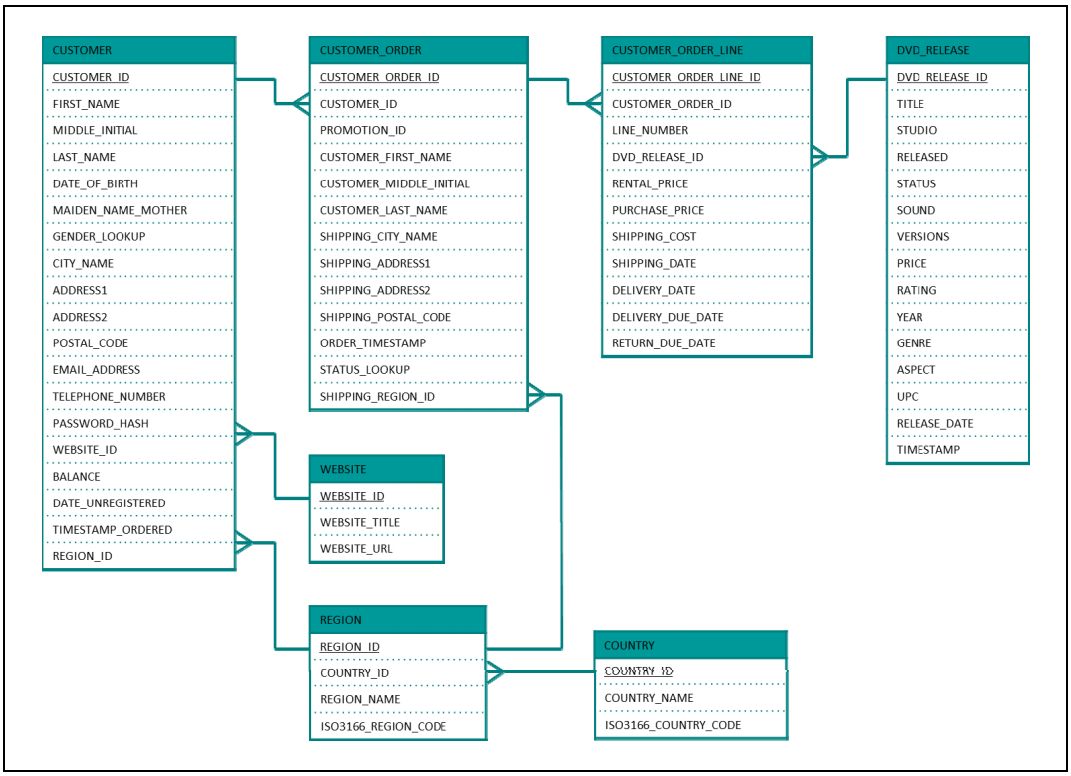
图4 WCM样例数据库的数据模型
待续......
在上篇我们介绍了利用JDV服务器设计数据虚拟化环境的一些背景知识,从中篇开始,我们开始介绍设计数据虚拟化环境的具体步骤,敬请大家期待~


如想了解更多,您还可以:
1.到Github浏览更多平台信息
https://github.com/BriData/DBus
https://github.com/edp963/davinci
https://github.com/edp963/wormhole
https://github.com/edp963/moonbox
2.加入微信群,和技术大神们点对点交流
请先添加小助手:edpstack

以上是关于数据虚拟化环境设计步骤分解(上篇)的主要内容,如果未能解决你的问题,请参考以下文章
python环境配置步骤二:Windows中创建虚拟环境安装Pytorch并在PyCharm中配置虚拟环境