虚拟化实践
Posted 微店技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了虚拟化实践相关的知识,希望对你有一定的参考价值。
虚拟化实践
引言
这里的虚拟化等于私有云。本文并非虚拟化的科普文章,主要将我们在私有云实践过程中的一些思想和遇到的问题拿出来跟大家讨论分享。我们虚拟化实践包含了传统的基于libvirt协议的KVM以及目前流行的docker。
为什么要虚拟化
虚拟化的目的各家公司原因应该都差不多,一般都是为了实现如下目标:
资源交付效率
传统物理机的时代,一个服务器交付要经历找资源,网络配置,idc安装,配置初始化等过程,效率很慢。在瞬息万变的互联网环境中,产品周期的变的越来越短,对开发和运维的要求越来越高,对于运维来说,资源交付效率就至关重要。
虚拟化可以将物理机的初始化时间前置,应用上线使用机器时,虚拟机交付可以做到秒级交付,可以很大缩短上线时间。
资源利用率
有了现代多核、多处理器系统,单个服务器可以很容易地支持十几个或者更多的虚拟机,让更多的应用程序能够受益于高可用的硬件配置,榨干硬件的红利,降低公司硬件成本。
自动化运维
虚拟化更容易提供统一的抽象资源和抽象接口,有利于平台化运维。
目标
我们虚拟化的目标主要是实现一个统一的资源管理和交付平台,
在运维中的位置大致如下:
在技术上同时具备如下目标:
跨平台,支持libvirt虚拟机和docker容器
支持libvirt主要是为了支持传统的虚拟化技术,如kvm,xen;支持docker主要是为了使用容器的灵活性和高密度。
支持用户自助
申请和准备资源在运维的日常工作中占了相当大的一部分工作量,我们很懒,我们想将这个工作放给各个部分负责人或者开发人员。
自助的服务包括:自助增删改查、自助扩容、自助打镜像。
可运维性
一项技术再牛逼,如不可运维,那结果绝对是灾难性的。因此我们希望我们的私有云是可控、稳定,同时兼顾数据的准确性。
弹性计算
实时监控各个虚拟机或者容器的性能指标,弹性的扩容和缩容,合理的分配利用资源。
IAAS化
为了和当前的运维体系对接,我们要求虚拟化平台统一对外提供IAAS服务,虚拟机均配置IP,可ssh。
设计
简单,可控,稳定是设计的基本原则.
关键点设计
我们是分了如下7点来设计和规划我们的vcloud平台。
1.虚拟化技术选择
容器最近很热,其确实也很灵活,但是大规模的使用时机还不成熟;所以我们选择传统虚拟化技术KVM+docker,确保线上应用的稳定的同时,测试环境可以利用到docker的轻量,高性能和灵活。
但如何抽象管理docker和KVM呢,KVM支持的是libvirt,docker的是API,为此我们自己开发了一个cloudagent,部署在各个宿主机上,对外提供统一的管理接口。
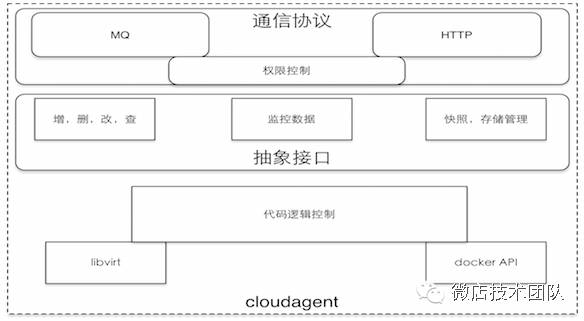
支持MQ为了进行复杂的调度算法和大规模部署,支持http可以方便调试。
2.网络选择
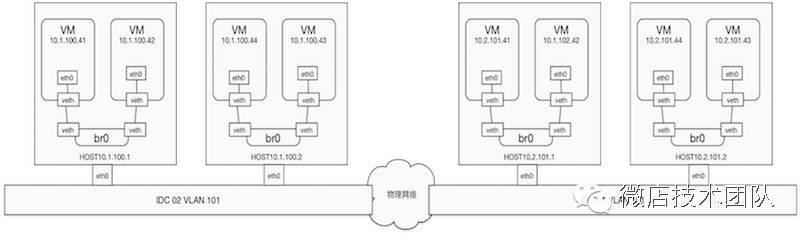
考虑到私有云无自建私有网和隔离的需求,我们选择的网络解决方案是网桥,来简化网络的设计,所有VM网络都是联通的,如有跨环境隔离需求,统一使用网络ACL控制;
虚拟机的IP统一在web平台指定(按规则生成),不使用libvirt或者docker本身的自动分配,防止DHCP带来的不可控问题。
3.存储选择
本地存储使用ssd的LVM,虚拟机跑在LVM上,让运行的虚拟机有非常好的IO性能。同时用ceph作为镜像管理中心和快照中心,提供一个大,但性能不是太好的附加存储。
PS:强烈建议大家私有云配置ssd,而且单盘裸盘足够,我们前期使用过SAS和SATA盘,性能惨目忍睹,IOwait经常大于50。
4.镜像管理
KVM和docker如果使用两套镜像管理,带来的管理成本太高,为此我们kvm使用tgz镜像,docker使用官方的registry v2,这样kvm和docker的镜像可以相互转换,可以做到镜像内容统一。
PS:由于最新的docker registery v2不支持ceph的S3,我们自己写了一个模块来支持。

5.管理平台选择
是开源还是自己开发?目前功能最全的openstack,大而全,特别是在网络和存储这块,很多公司都用openstack开发自己的私有云和公有云。但对于我们来说,openstack很多功能用不到,特别是它最复杂的网络;而且openstack维护复杂,需要有专门的commiter来跟进和修改,以满足自动化运维的需要。
考虑到工作量和后期开发维护成本,我们选择自己开发一个简单灵活的管理平台,主要具备如下功能:
用户管理
虚拟机管理
监控管理
镜像管理
API
6.集群调度
我们没有使用swarm或者kubernetes,主要原因有两个:第一,我们需要的功能很简单,实现起来并不复杂;第二,swarm和kubernetes版本更新太快,会增加运维成本。
我们的使用满足单机之间没有交互,每一个单机都可以独立运行,互不影响;所有的调度都在平台上控制,保持架构简单、稳定、高效、可控。
调度算法很简单:
第一,管理员人工指定物理机,这个优先级最高。
第二,在不指定的情况下(普通用户不能人工指定),秉持最少使用(CPU and 内存)和同一应用尽量分散的原则选择物理机。
PS:kubernetes是一个好东西,特别是他的pods理念很好,很值得借鉴。
7,监控
监控很关键,是调度,弹性管理和故障迁移的前提,这个的要求是不入侵虚拟机,监控数据采集统一在宿主机上通过cloudagent采集。
传统虚拟机可以通过libvirt接口,docker可以通过cgroup+docker API,来计算虚拟机的CPU利用率,内存使用率,磁盘IOPS,磁盘吞吐量和网络速率。
平台设计
如下是我们vloud平台的架构图: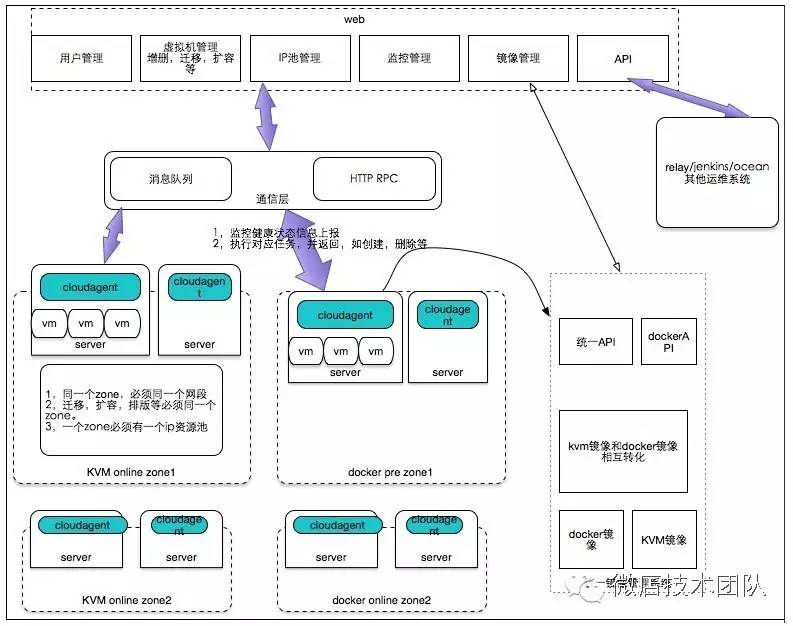
zone集群
zone是一个最小集群管理单元,迁移,扩容,批量创建都是一个zone里操作。
一个zone必须在一个网段,一个zone对应的IP池,IP由一个统一算法分配,也可以管理员手工指定。
一个zone内的物理机不相互通信,所有的动作都在平台上控制,由cloudagent接收指令并执行。
镜像管理
docker的镜像管理使用docker registry v2,kvm使用http的tgz,docker的镜像和kvm的tgz镜像,我们按需要进行相互转换。
cloudagent
这个是我们自己开发的统一的管理agent,部署在各个物理机器上,封装了libvirt的API、docker API。对外抽象出统一的接口,含创建、删除、扩容、暂停、监控等。
性能监控
使用不入侵容器和虚拟机的方式,通过cgroup统一抓取cpu、mem、iops、网络;监控数据作为扩容和缩容的一个依据。
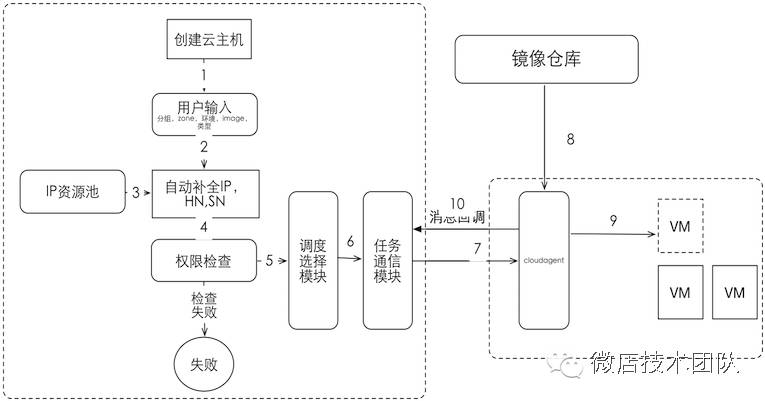
创建一台虚拟机
我们拿创建虚拟机这个工作,简单看一下我们的内部调用流程:
docker关键技术
由于kvm这块比较成熟,网上说的也比较多,本文不做太多的阐述,这里简单介绍一下我们是如何使用docker。
docker的技术清单如下:
| 项目 | 参数 |
|---|---|
| docker版本 | 1.10.1 |
| 存储 | 本地ssd devicemapper |
| 网络 | 网桥,–net=none,pipwork种IP |
| image管理 | docker registry V2 |
| 物理机配置 | 32核 128G内存 800Gssd |
| 密度 | 4核4G容器 单台 60个 |
| 管理方式 | Cloudagent+docker API |
我们现在最高的密度已经达到了单台50个,服务器运行毫无压力,应用无异常,估计可以跑到100个。
CPU限制
CPU限制,为了管理方便,只用cpuset来限制CPU。在选取绑定的CPU时,按照最少使用原则,同时需要考虑不要跨NUMA。
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
"CpusetCpus": "14,15,12,13",内存限制
我们选择了3个参数来控制内存,Memory限定最大可用物理机内存,MemorySwap限定物理内存+物理机内存总大小,OomKillDisable标记内存超过限定是否KILL容器。
原则上是Memory=MemorySwap,即不使用swap,因为我们希望容器内存溢出时可以被直接kill掉,不要影响其他容器。
"Memory": 4294967296,
"MemoryReservation": 0,
"MemorySwap": 4294967296,
"MemorySwappiness": 1,
"OomKillDisable": false,网络
网络使用网桥,—bridge=docker0,且和物理机共享一个vlan,简化网络架构。
由于docker目前还不支持指定IP,所以这里使用了pipwork来为容器指定我们需求的IP。
/root/cloudagent/script/pipework docker0 -i eth0 idc01-dev-devgroup-101104 1.1.1.1/24@1.1.1.254 02:42:c0:01:65:68docker registry V2
后端存储使用ceph,能够提供几乎无限大的存储,方便用户自定义做快照和镜像。
由于是在内网,registry 没有使用验证。
docker 本地存储
我们用的是devicemapper + direct-lvm,LVM用的是一个800G ssd裸盘。
--storage-opt dm.basesize=40G --storage-driver=devicemapper --storage-opt=dm.thinpooldev=/dev/mapper/docker-thinpool --storage-opt dm.use_deferred_removal=true成果展示
经过半年的开发和使用,目前vcloud1.0已经的在微店内部使用,虚拟化也全部推开。
普通用户管理视图
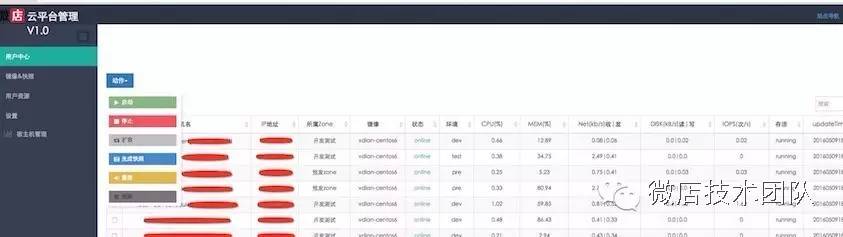
用户权限管理
用户按zone授权,资源控制到CPU,内存和总个数。

监控数据
我们的监控数据统一由cloudagent抓取,并且计算的都是每个VM实际使用的。
QA
为什么不提供PAAS?
这个看如何理解PAAS和IAAS,在私有云里PAAS应该理解为应用是否可以自动化上下线。创建一个容器提供出一个nginx服务,在私有云里叫不上PAAS,一般都还需要SRE将这个nginx服务暴漏出去,所以我们将我们的Vcloud叫做IAAS平台;当自动化上线实现了其实才是真正的PAAS。
用什么语言开发,考虑开源吗?
我们平台用的是java,后端cloudagent用的是python;暂时还不考虑开源,主要是没有时间整理我们的代码,等后续平台稳定和功能完善后,会抽出空来整理我们的代码和规范,开源给大家参考一下。
如何实现KVM和docker的统一管理?
我们之所以可以做到统一管理,主要原因有两个,第一:cloudagent,由其来抽象libvirt API及docker API;第二就是KVM使用tgz的模板装机,tgz的模板可以和docker的image相互转换,这点特别重要。要不然需要管理两套的image,那就谈不来统一管理了。
物理机挂了或者load过高怎么办?
这里解释一下我们这边的迁移功能(重新创建功能):将之前的节点销毁,然后在zone里重新找一台机器来创建,如果之前有快照,可以选择之前的快照。
当物理机挂了,我们只要将物理机从zone中剔除,然后逐个迁移,然后重新发布(无快照情况);由于IP等信息不变,无需修改CMDB 和LB配置。
为什么不全部使用docker?
相比KVM比较成熟的虚拟化技术,容器目前还有很多不完善的地方,除了集群管理、网络和存储,最重要的还是稳定性。容器的隔离性不是很好,当一个容器出现问题,很可能影响到整个物理机。
后续还有什么规划?
后续我们将重点围绕docker经行更多功能的开发,编排,jenkins对接,自动上下线和分布式附加存储。
最后
注:封面图片来自http://news.watchstor.com/
以上是关于虚拟化实践的主要内容,如果未能解决你的问题,请参考以下文章