基于硬件辅助虚拟化的多核确定性重演系统研究
Posted CCF系统软件专委
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于硬件辅助虚拟化的多核确定性重演系统研究相关的知识,希望对你有一定的参考价值。
导读
2018年1月,北京大学肖臻研究员团队的论文《Leveraging Hardware-Assisted Virtualization for Deterministic Replay on Commodity Multi-Core Processors》被计算机系统领域顶级学术期刊TC(IEEE Transactions on Computers)录取并在线发表(DOI: 10.1109/TC.2017.2727492)。肖臻研究员团队在虚拟机多核确定性重演领域已深耕数年,2016年团队也曾在顶级学术会议USENIX Annual Technical Conference上发表题为《Samsara: Efficient Deterministic Replay in Multiprocessor Environments with Hardware Virtualization Extensions》的学术论文。本文将以上述两篇论文为主线,简要介绍肖臻研究员团队在虚拟机多核确定性重演领域的相关研究内容和发现。
研究背景
确定性重演(Deterministic Replay)指在处理器指令执行过程中,记录开始时的状态和执行时的必要信息,从而使得将处理器恢复到开始位置重新根据记录的信息执行这一段指令后,能够获得与前一次执行完全相同的结果。虚拟机确定性重演系统在记录阶段将程序执行时发生的所有不确定性事件记录到日志中,在重演阶段选取相同的检查点作为执行起始点,并且在相同位置插入记录阶段的所有不确定性事件,使得处理器执行相同的指令流,进而得到一致的输出和结果。
虚拟机确定性重演技术被广泛应用于众多领域之中。在软件调试领域,虚拟机确定性重演是实现循环调试的有效手段之一;在信息安全领域,虚拟机确定性重演可以被用来实现入侵检测和病毒行为分析等应用;在虚拟机容错领域,虚拟机确定性重演可以被用来实现虚拟机双机热备份系统。在区块链领域,确定性重演可以用来实现高效的共识机制。已有的区块链技术(比如以太坊中的智能合约)往往只支持单线程,就是因为在多核环境下并行程序的执行存在不确定性,影响区块链中的节点达成共识。确定性重演技术运用到区块链协议中有助于实现高性能公链。
针对单核处理器的确定性重演技术已经相当成熟,并且已经出现了众多成熟稳定的商用系统。然而多核处理器环境的出现给确定性重演技术带来了极大的挑战。在多核处理器环境下,多个处理器核对共享内存的交织访问也是导致程序执行结果不确定的重要原因之一。另外,随着多核处理器的普及,越来越多的程序采用多线程技术开发,而多线程程序的各个线程间可能包含了大量的共享内存访问,如同步锁、信号量、共享内存变量等。在多核处理器环境下,多线程程序每次执行时对共享内存的访问顺序有可能完全不同,而这会导致确定性重演的失败。
针对上述问题,本研究团队提出了Samsara系统来解决内存访问交织问题。Samsara是第一个基于硬件辅助虚拟化技术来从软件上实现多核虚拟机在线确定性重演的系统,该系统采用了基于执行块的方法,在运行时将虚拟处理器执行的指令划分为若干个指令块,通过指令块内存访问写时复制机制和指令块的提交-回滚机制保证指令块的执行满足原子性和可串行性,通过记录指令块的长度和提交顺序实现对于共享内存访问交织的记录。该方法使得对共享内存交织的记录能够以指令块为粒度进行处理,从而大大提高了记录效率并且减少了记录日志的大小。此外,Samsara还使用了多种硬件辅助虚拟化特性来优化对内存访问的追踪及对重演过程的加速。
系统架构
图2.1 Samsara系统架构图
如图2.1所示,Samsara对VMM进行了扩展以实现确定性重演。如图中所示,Samsara的架构包括控制组件、DMA事件记录组件、不确定性事件记录和重演组件以及用户态日志记录守护进程四个组件。控制组件作为QEMU的一部分工作在用户态,负责管理虚拟机记录或重演功能的开启与关闭。不确定性事件记录和重演组件作为KVM的一部分工作在内核态,也是Samsara用来记录和重演不确定性事件最重要的一部分。由于DMA事件的特殊性,Samsara需要通过DMA时间记录组件来单独记录DMA事件。最后,为了提高记录和重演阶段对于日志文件的读写速度,Samsara在用户空间单独实现了日志记录守护进程,利用Linux 的mmap系统调用实现了日志文件在内核空间与用户空间的高效映射。
利用硬件辅助虚拟化实现共享内存访问交织的记录和重演
因为对共享内存的交织访问数目远多于其他不确定性事件,所以对于多核确定性重演系统最大的挑战就是如何记录和重演该事件。一些纯软件的解决方案通过采用共享读-独占写协议记录对共享内存的读写顺序,在重演时只要保证对于共享内存的读写顺序即可。为此,每一次对于共享内存的读写都要被检查。然而,无论是使用硬件页保护还是二进制指令翻译来记录每一次对于共享内存的访问,都给记录阶段的执行带来了极大的性能开销并且产生大量的日志。为了提高性能,人们提出了一些硬件辅助的记录方法。有些方法通过修改缓存一致性协议来记录共享内存访问顺序。然而该方法需要修改现有的硬件结构、并且仍旧会产生大量的日志。Samsara运用硬件辅助虚拟化提供的一些新特性实现基于指令块的内存交织记录方法,在不修改现有硬件的前提下,实现了对于共享内存访问交织的高效记录,并且减少了日志大小。
3.1 基于指令块的共享内存访问交织记录
Samsara采用了一种基于指令块的共享内存访问交织记录方法,该方法把连续执行的一段指令序列称为一个指令块,如果可以保证指令块的执行满足原子性和可串行性,那么只通过记录指令块的大小和指令块的提交顺序即可实现共享内存访问交织的记录和重演。
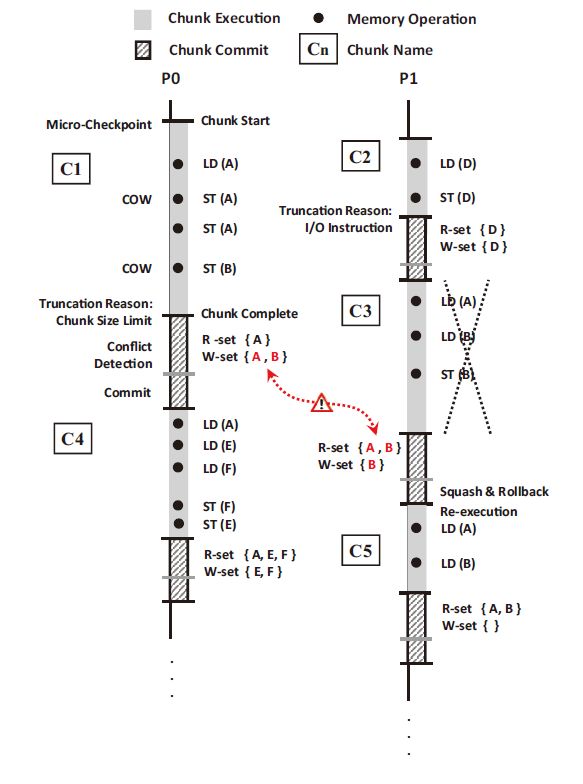
图3.1 基于指令块的共享内存访问交织记录策略的执行流
Samsara采用了基于内存写时复制、内存访问冲突检测和指令块提交-回滚的机制来实现基于指令块的系统,并且保证了指令块的执行严格满足原子性和可串行化要求。图3.1展示了基于指令块的共享内存访问交织记录策略的执行流,其中P0和P1代表两个vCPU,并且图中每个指令块读内存的内容均来自共享内存,而写内存操作则写到一块私有空间内,并不能立即被其它指令块读取,从而保证了指令块的原子性。此外每个指令块执行之前都需要保存当前vCPU的状态到微检查点中,以备后面回滚使用。系统开始时P0执行了指令块C1,同时P1执行了指令块C2。C2首先因为执行到了I/O操作从而结束指令块,并且获得该指令块对内存的读写访问集合,每个集合中只有D一个内存页面。由于C2是第一个结束的指令块,此时系统中还没有任何部分受到影响,所以 C2可以将其修改过的内存内容复制到虚拟机共享的内存中。之后 C1 因为达到指令块的大小限制从而结束执行,并获得内存读集合为{A},写集合为{A, B}。检测发现读写集合与刚刚提交过的指令块C2的写集合{D}没有交集,说明C1在执行过程中所需要的内存资源没有被C2修改过,即满足可串行化要求,因此C1也可以提交,并将其修改的内存更新到共享内存中。在C1提交的过程中,P2执行了C3,并且读写集合分别为{A, B}和{B}。由于C3开始执行时C1还没有完成提交,且C3的读写集合与C1的写集合有交集,这意味着C3在执行的过程中无法确定其对内存A和B的读操作的结果是C1提交之前的值还是之后的值。此时如果提交C3则会导致C3与C1的执行无法满足可串行性要求,因而需要放弃C3对内存的更改,并且将C3所在vCPU回滚到前文所述的检查点。此时C3将重新执行该指令块。
3.2 利用硬件辅助虚拟化高效地获取读写集合
指令块提交时进行的冲突检测的目的是确保指令块的执行满足可串行化要求,如果指令块执行期间内其读或写的任何内容被其他已经提交的指令块修改,那么这个指令块将被摧毁。要实现这点,最关键的是获取指令块执行期间完整的读写集合。以往方法通过检查VM的每次读写来确定读写集合,带来了极大的性能损失,并需要记录庞大的日志。尤其以往在虚拟机上的实现方法,通常需要利用硬件页保护的机制使得VM内部的每次读写都陷入到VMM内部进行检查,而由于陷入导致的虚拟机退出的代价是极大的。因此 Samsara 系统需要一个更高效的内存访问冲突检测机制。
通过对硬件辅助虚拟化的深入研究,我们发现Intel VT技术中的扩展页表(EPT)提供了一种对内存访问的检测特性,即在EPT页表项中提供Accessed和Dirty位。当虚拟机对某个页面发出写操作时,EPT会将该页对应的EPT页表结构中的Dirty位置位;当虚拟机对某个页面发出读或写操作时,EPT则会将相应页表结构中的 Accessed位置位。借助该硬件辅助虚拟化技术的支持,Samsara系统只需要在每个指令块开始前清空 EPT 页表结构中所有的Accessed和Dirty位,并结束后对整个EPT页表进行一次扫描便可获得这个指令块所有内存读写操作涉及的页面。
图3.2 EPT页表的遍历过程
在实际应用中,如图3.2所示,并不需要扫描整个EPT 页表结构,这是因为EPT为每一层的页表结构都提供Accessed和Dirty位,由于指令块的内存访问具有空间局部性,所以常常只需要扫EPT页表结构中的一部分子树即可获得所有的内存读写页面。对于虚拟机系统来说,虚拟机陷入VMM的代价是非常大的,再加上指令流中的内存访问非常之多,使用硬件辅助虚拟化获得内存访问的方法会大量减少虚拟机陷入次数和对EPT页表的修改操作,是一种非常高效的获得内存访问的方法。
3.3 利用硬件辅助虚拟化截断指令块的执行
指令块不可能无限制的执行下去而不结束,这是因为如果某个指令块过大的话,那么它与其他指令块发生冲突的概率会大大增加,导致该指令块被反复回卷并被重新执行。因此指令块也不能够太大,否则会严重降低系统的响应速度,所以Samsara 系统需要指定指令块大小的上限,并且在当某个指令块的执行达到上限时截断指令块的执行。
Samsara通过硬件辅助虚拟化Intel VT技术中的Preemption Timer技术实现了指令块的截断。Preemption Timer技术为虚拟处理器提供了一种计时器,该计时器可以在虚拟处理器执行若干条指令后触发一次相关虚拟机退出,陷入到VMM中,从而达到截断指令块执行的目的。Samsara利用Preemption Timer可以显著提高指令块截断操作的效率。
3.4 共享内存访问交织的重演
基于指令块的共享内存记录方法允许Samsara实现并行重演。在重演时,只需要保证各个指令块按照重演阶段记录的大小被构造,并且按照记录阶段的提交顺序被提交即可。为此,Samsara首先需要保证重演时执行的指令块与记录阶段完全一样,因此Samsara需要确保虚拟处理器在准确的位置截断指令块。此外,Samsara还需要确保指令块按原有顺序执行。因此在任一个指令块开始执行前,Samsara需要检查在记录阶段,在该指令块开始之前已经提交的其他所有指令块是否都已经被正确提交。特别需要指出的是,在重演阶段Samsara仍然需要采用写时复制技术确保该指令块更新的所有内容对其他同时执行的指令块不可见。在保证上述几点之后,Samsara就可以实现所有内存访问交织的重演。并且在执行过程中,并不需要冲突检测广播更新等等的过程。
总结
本文首先简要介绍虚拟机多核确定性重演系统的概念,接着指出了限制传统虚拟机多核确定性重演系统应用的性能问题,在此基础上,提出了基于硬件辅助虚拟化实现的多核确定性重演系统Samsara。
Samsara系统解决了困扰学术界和工业界多年的多核确定性重演的效率问题。Samsara利用硬件辅助虚拟化技术实现了对于共享内存访问交织的高效记录。与以往虚拟机多核确定性重演方法不同,Samsara第一次将基于指令块的执行方法应用于软件实现的多核确定性重演系统中,通过遍历扩展页表中提供的Accessed和Dirty位来快速获取虚拟机运行过程中的读写集合,从而避免了以往系统中效率低下的硬件页保护机制。我们在KVM和QEMU上实现了Samsara系统,实验结果表明,对于两个处理器来说,Samsara将记录阶段执行效率从以往的10x以上降至3x以下,并将日志文件大小降低到了原有方法的1/70。
除了虚拟机确定性重演技术之外,我们课题组还在虚拟机热备份领域进行了深入的研究。我们首次提出了利用硬件辅助虚拟化技术中的PML特性进行内存脏页追踪的方法和基于RDMA的异步脏页预取策略,使得备份虚拟机可以在不中断主虚拟机运行的情况下,异步地将主虚拟机产生的内存脏页拉取到备份虚拟机中。相较于业界主流的双机热备份系统,我们的技术能够降低85%的系统延迟,大幅度提高系统的性能。
相关成果
论文
[1] Shiru Ren, Le Tan, Chunqi Li, Zhen Xiao, and Weijia Song. Leveraging Hardware-Assisted Virtualization for Deterministic Replay on Commodity Multi-Core Processors IEEE Transactions on Computers (TC), January 2018.
[2] Shiru Ren, Le Tan, Chunqi Li, Zhen Xiao, and Weijia Song. Samsara: Efficient Deterministic Replay in Multiprocessor Environments with Hardware Virtualization Extensions Proc. of the USENIX Annual Technical Conference (ATC 2016), June 2016.
[3] Shiru Ren, Chunqi Li, Le Tan, and Zhen Xiao. Samsara: Efficient Deterministic Replay with Hardware Virtualization Extensions Proc. of the ACM SIGOPS Asia-Pacific Workshop on Systems (APSys 2015), July 2015.
以上是关于基于硬件辅助虚拟化的多核确定性重演系统研究的主要内容,如果未能解决你的问题,请参考以下文章
基于intel x86+fpga智能驾驶舱和高级驾驶辅助系统硬件设计
基于国产银河飞腾多核 DSP +FPGA的图像识别硬件设计与算法实现
基于国产银河飞腾多核 DSP +FPGA的图像识别硬件设计与算法实现