基于KVM虚拟化的混合部署
Posted AlwaysGeek
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于KVM虚拟化的混合部署相关的知识,希望对你有一定的参考价值。
前言
KVM forum 2019上,作者和同事的演讲主题是《How KVM-based Hybrid Deployment Powers Bytedance’s Biggest Day Ever》。
在这里详细展开一下,介绍一下基于KVM虚拟化的混合部署。下文的脉络大约是:
1,业务背景
2,为什么使用KVM虚拟化方案
3,在使用KVM虚拟化方案的过程中,我们做了那些改进
4,基于KVM虚拟化的混合部署方案取得了怎样的效果
业务背景
对象存储服务(OSS)是典型的IO密集型的业务,对CPU&MEM、甚至是网络消耗都比较低,在存放冷数据的服务器上,CPU的使用率甚至不足5%。
典型的在线业务一般是网络应答式,接收网络请求,处理后返回结果,一般是CPU/MEM密集型,IO消耗一般是业务写log,网络流量一般也不高。
可见,二者的业务特征具有一定的互补性,可以尝试把两种业务进行混合部署。
为什么选择虚拟化
混合部署一直以来都是一个长期讨论、实践的主题。之前,有很多基于cgroup/docker的混合部署的文章和总结也给我们提供了大量的参考,其中有技术改进、最佳实践以及对未来的思考等等。然而,作者所在的团队最终选择了KVM虚拟化方案,原因是KVM虚拟化提供了更高的隔离性,总结如下。
CPU的隔离性问题
写一段代码,16线程并行执行,配置cgroup为4 CPU的quota。使用top -d 1查看,可以发现CPU的消耗基本在400%左右。我们使用脚本收集数据,以1s为粒度,可以看到效果如下:
如果把时间粒度改成10ms收集一次,可以看到如下效果:
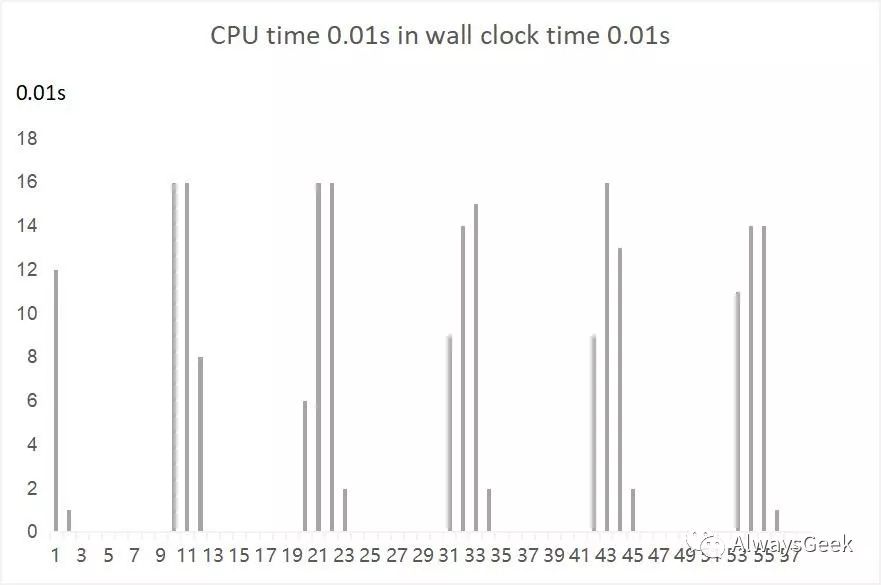
由此可见,Linux本身的调度基于tick实现,cgroup可以保证在一个相对较长的实践范围内实现比较好的CPU限制,但是在较细的粒度上是无法保证的。(详细代码和数据可以参考前文《Cgroup CPU Quota技术的不足》)。
我们继续以mysql为例,在server端启动mysqld进程,在client端启动sysbench压测。同时启动上述的示例代码,设置quota是4 CPU,理论上来说,在12 CPU的服务器上,应该不会对mysql的性能产生非常大的影响。然而实验效果如下:
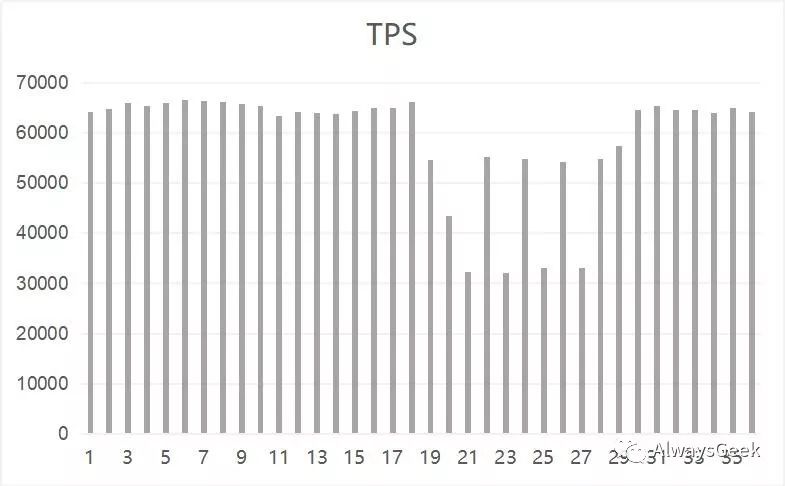
在19s ~ 29s之间,mysqld的TPS发生了比较剧烈的抖动。
对比实验KVM,启动一台4 vCPU的虚拟机,在虚拟机内部运行上述的示例进程,监控qemu进程的CPU消耗,无论在1s还是10ms级别,CPU消耗始终不会超过400%。TPS有所降低,但是非常稳定。
收集延迟的PCT99在虚拟机中更加稳定,对比如下:
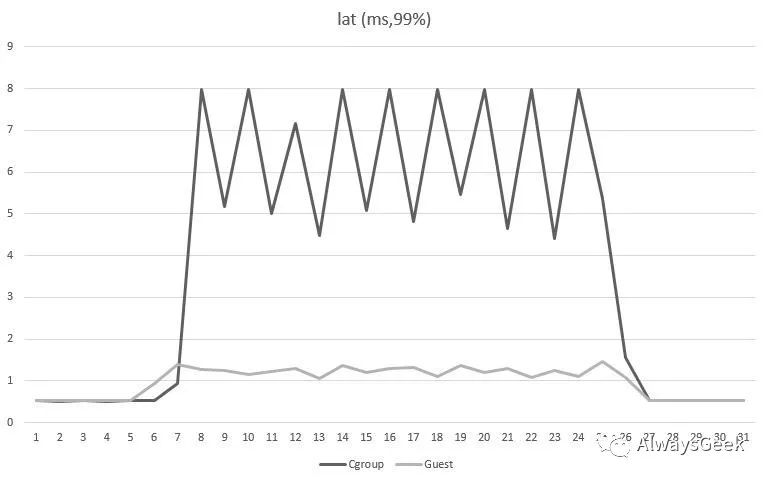
调度模型对比
作者知道的几种在线业务模型:
python业务:由于python是单线程模型,有的业务会选择使用CGI模型,fork起来多个进程(通常是1K量级)。也有python框架实现了异步IO,会启动较少的进程。还有会调用c库,创建起来多个线程。
golang业务:多协程下面有多线程。
java业务:多线程,锁住大块内存。
C/C++业务:多线程,有可能伴随着大量的内存分配/回收。
当然还有更多的不知道的业务场景,由于无法预测在线业务的类型,也无法预测在线业务的workload,就很难有一种适配所有场景的进程隔离方式和内核调度策略。在虚拟化场景下,调度模型就会变得非常简单:在宿主机上仅仅有有限的vCPU线程,通常一个36核的虚拟机仅仅有36个vCPU线程、一个QEMU主线程、有限个数的IO thread、vnc thread等不到50个thread。取得的效果是把大约1K以上的业务Task转换成了大约50个虚拟机的Task。
把复杂的业务调度模型放到虚拟机内部中去,在通过一定的CPU亲和性隔离,宿主机上运行的OSS业务的QoS很容易获得了调度上的保证。
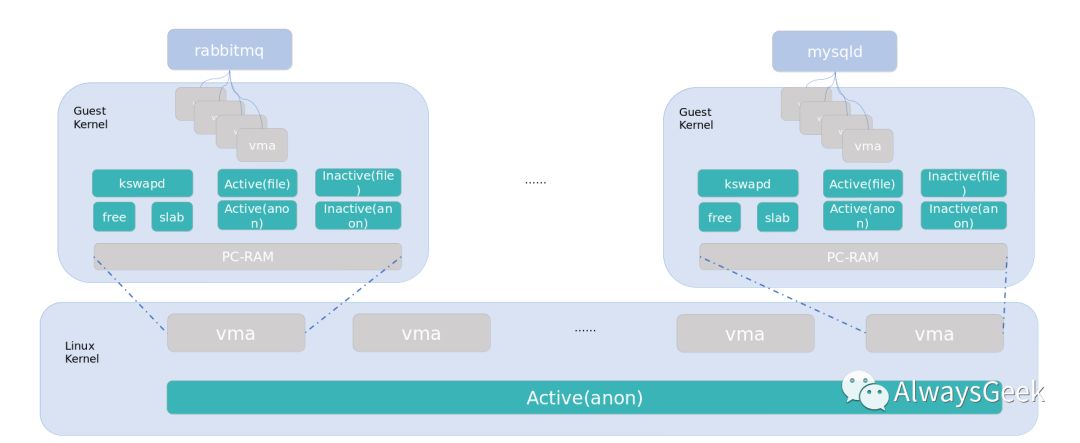
内存模型对比
在Linux服务器上,通常有文件映射(page cache)、匿名映射、free memory、slab内存,内核管理这些内存,维持着各个NUMA node的各个zone的内存分配/回收。且有了cgroup的内存管理之后,内存管理的复杂度进一步提升。
在cgroup/容器隔离的场景下,由于上文提到的业务类型很多,导致服务器上的内存模型相当复杂,且难以预测。
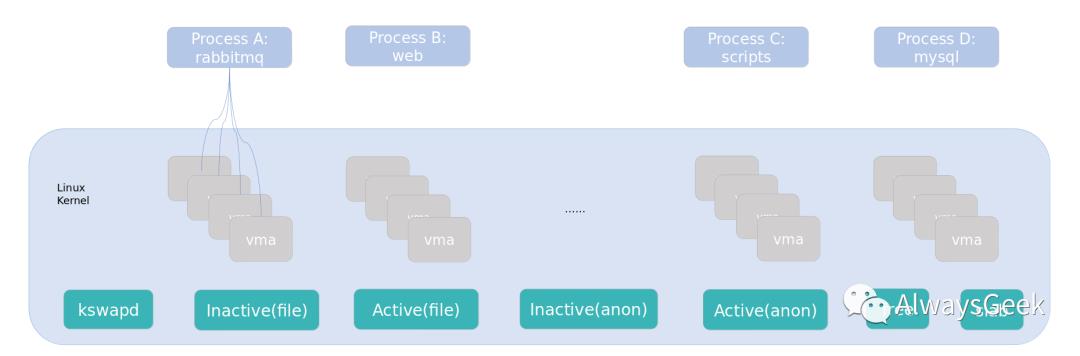
在KVM虚拟化场景下,则会变得简单,对于一台虚拟机,仅仅使用匿名映射,且PC-RAM内存可以使用大页,尤其是HugeTLB隔离出来的内存不再受到Host上的buddy system管理,Host上的内存管理成本几乎没有任何的影响。
磁盘IO的隔离对比
Linux目前无法很好的支持page cache隔离(最新的Linux upstream上开始有些支持,但是效果不好。且目前的LTS版本中都没有支持),page cache隔离不好就很难做好磁盘的IO隔离。
另外,还有一些隐式的竞争,在mysql使用的数据库的分区(EXT4)上,删除一个较大的文件,mysql的TPS会发生一次抖动,效果如下:
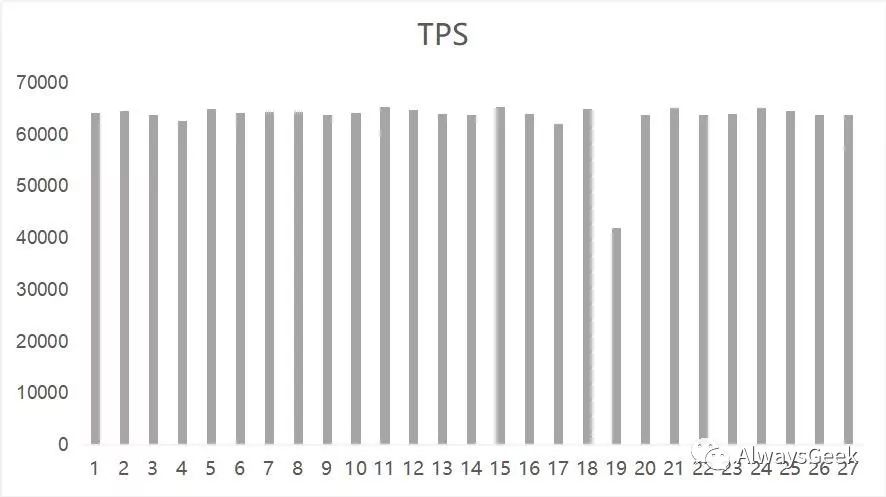
尽管删除一个文件,不会涉及到文件的数据IO,但是因为删除inode,修改了meta data,EXT4会记录journal,而一个文件系统分区只有一个journal线程,这里是串行执行会成为瓶颈。大一些的文件通常会大一点的meta data,会使用较长的时间。在这段时间内,mysql的Create/Update/Delete操作都可能涉及到meta操作,就会产生抖动。
在虚拟化的场景,可以使用裸磁盘分区通过Block访问的方式提供给虚拟机使用。Host上将不再需要文件系统的参与,甚至可以给虚拟机挂载远程盘。同时QEMU对虚拟块设备的IO限速有很好的支持,通过bandwidth和IOPS两个维度的限速,可以让Host进程对盘的访问依然稳定。
同样的测试场景在虚拟机中的表现很好,mysql的TPS和延迟几乎看不到差异。
网络IO的隔离对比
在cgroup/容易的场景下,OSS和业务进程共享整个Host服务器的内核和网卡硬件。目前内核还不能有效的控制每个进程/一组进程的网络IO的bandwidth和PPS。例如在线业务在拉取docker镜像的时候,会有一个大的网络IO的突刺,OSS的QoS有可能会受到影响。甚至在线业务使用过多的本地端口会影响OSS对外部服务的访问。
在虚拟化场景下,使用SR-IOV的方式分配出来一个网卡的virtual function,把VF透传给虚拟机,对VF进行硬件的bandwidth和PPS限速,且Host和Guest分别是两个完全独立的网络协议栈,二者之间没有任何干扰。稍微麻烦一点的地方就是需要额外配置TOR,控制好分配的IP。当然,使用overlay网络也是可行的。
内核版本的差异对比
在cgroup/容器场景下,因为共享同一个内核,所以必须使用相同的内核版本。对于OSS,一般对kernel版本要求不高,且希望稳定不间断的运行。而对于在线业务,尤其是涉及到cgroup/容器之后,对内核版本通常有更高版本的要求。
在虚拟化场景下,Host可以在不做改动的情况下,动态加载kvm的kmod到内核中,启动虚拟机。在虚拟机中,可以运行任何版本的内核,甚至windows。
对虚拟化的改进 --- kvm-utils
在混合部署的场景下,Host通常是在线运行的,且不能升级内核/kmod。但是debug依然是必要的,为此,开发了kvm-utils工具,用来分析虚拟化的性能问题。kvm-utils的debug功能基于kprobe,可以动态的安装/卸载。分析vm-exit功能的效果如下:

分析wrmsr exit的效果如下:
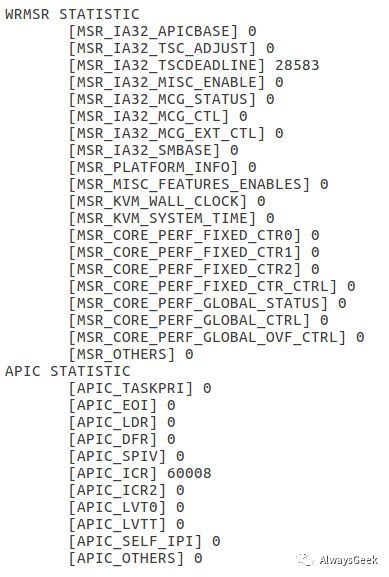
kvm-utils还包含microbenchmark功能,能够测试PIO/MMIO/TIMER/IPI的消耗的时钟周期。软件很快将会开源在https://github.com/bytedance。
使用kvm-utils可以帮助分析很多性能问题,例如:
例子一,业务侧反馈说gettimeofday消耗的时间比正常偏高,kvm-utils可以发现PIO变多了。分析下来发现Guest内部的时钟源异常导致。因为关掉了kvm-clock,希望使用tsc作为默认时钟源,但是因为缺少了tsc reliable的参数,导致guest里面误认为tsc不稳定,自动切换到了acpi-pm导致的问题。
例子二,虚拟机内部的业务的QPS低于物理机,kvm-utils发现wrmsr TSC DEADLINE vm-exit超过了1M/s。后来发现是tcp的拥塞算法使用了bbr设置了太多的timer导致。
对虚拟化的改进 --- nohlt_list
作者使用的环境下,Host上有48个CPU,其中12个预留给OSS业务,于是启动了36 vCPU的虚拟机。
网卡VF有8队列,在虚拟机内部通常把中断亲和性绑定到CPU 0~7上。每秒钟大约150K ~ 500K左右的网络中断。那么平均单核每秒的中断数量大约在20K~60K左右,这样的数据量不足以让vCPU 0~7一直处于忙碌状态,所以vCPU进程需要执行idle任务,从而运行HLT指令而发生vm-exit。下一个网络报文到达VF后,vCPU将会被Posted-Interrupt Wakeup Event唤醒,重新进入none-root模式。
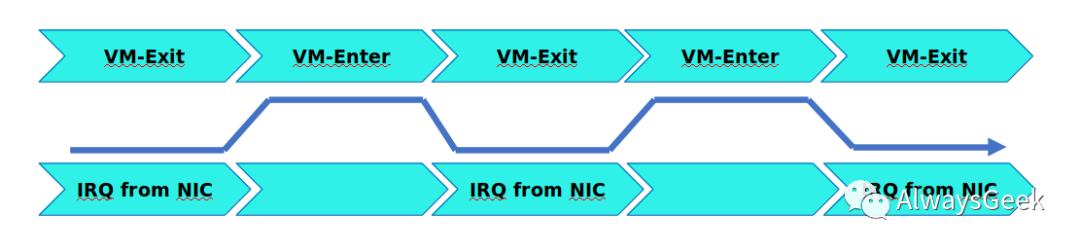
不断的HLT退出到PIW唤醒导致虚拟机处理中断的延迟不稳定,业务的延迟也会有偶尔的抖动。
当前内核中支持nohlt或者idle=poll模式,就会让所有的vCPU一直处理polling模式,不会执行HLT指令退出,但是这也意味着在Host上看到所有的vCPU thread都是100%的CPU消耗状态,这对于混合部署来说是不友好的。同时,这种polling会损害 CPU的另外Hyper-Thread的性能。
为此,作者开发了nohlt_list功能:允许一部分CPU跑在polling模式,配置内核启动参数如下:
linux ... irqaffinity=0-7 nohlt_list=0-7
只配置处理网卡中断的vCPU(0~7)跑在polling模式,在Host上只看到8个vCPU线程跑在800%,对于整机的48个CPU来说,不是太大的问题,同时虚拟机内部处理网络中断的延迟是稳定的。业务表现上PCT99也有所改善。
Patch: https://lkml.org/lkml/2019/5/22/164
PIW数据的测试效果,随机选择1K的服务器,对于没有启用nohlt_list的情况,多数服务器每秒会产生20K~100K的PIW:
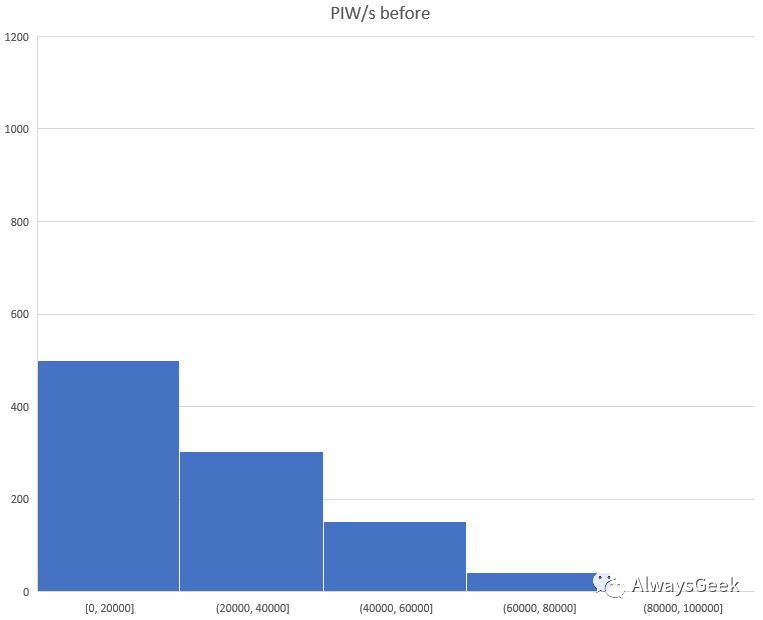
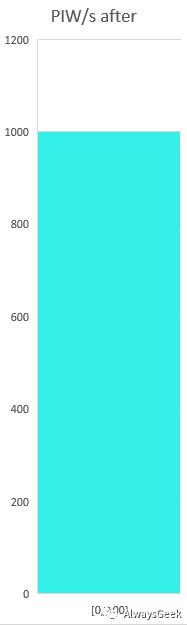
对于启用了nohlt_list的场景,所有的服务器上都只有很少的PIW,实际上多数都是0。
对虚拟化的改进 --- 用户进程
例子一,atop是Linux上一个监控软件,在作者的工作环境中,深受大家喜爱。然而atop会自动收集Instruction Per Cycle的信息。收集IPC信息需要使用PMU,在虚拟化场景下,虚拟机中使用vPMU会造成wrmsr/rdpmc的vm-exit,就会看到虚拟机的vm-exit每隔一段时间就会发生一次抖动(默认是10s)。为此,作者修改了atop程序,让atop在启动阶段自动检测运行环境,如果是在虚拟机中,则默认关闭IPC收集功能,当然也可以通过配置强制enable/disable。
patch在https://github.com/Atoptool/atop/commit/16abcac132eec4755373aa673389e67219488844
例子二,jemalloc是一个高性能的用户态内存管理库,有一些cache型的业务会使用jemalloc代替glibc的ptmalloc。但是jemalloc的decay特性会调用madvise(void *addr, size_t length, MADV_DONTNEED),而这个操作会触发TLB shootdown(上文《[Linux][mm]TLB shootdown和读取smaps对性能的影响》一文中有更多的描述),TLB shootdown在虚拟化上的成本要高于物理机,所以cache型的业务的QPS和延迟通常要略差于物理机上的表现。简单粗暴的办法是最好关闭掉decay功能,性能会接近物理机。
取得的效果
如上文所说,OSS服务器的CPU利用率普遍不高,随机选择了7K服务器,在晚高峰九点到十点左右收集CPU数据绘制分布图,大部分的服务器的CPU使用率在10%以内,还有部分服务器的CPU使用率在20%以内:
使用了KVM虚拟化混合部署的方案之后,几乎所有的CPU使用率都得到了很大的提升:
在CPU利用率提高的同时,额外超分配出来的百万量级的CPU得到了充分的使用。得益于KVM虚拟化的强隔离性,Host上的OSS业务几乎没有任何的损耗,而Guest内部的在线业务的性能也逐渐接近物理机,在性能调优之后,性能在一些场景下要好于某云计算大厂的虚拟机。
以上是关于基于KVM虚拟化的混合部署的主要内容,如果未能解决你的问题,请参考以下文章