容器将完全颠覆虚拟化
Posted 云头条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了容器将完全颠覆虚拟化相关的知识,希望对你有一定的参考价值。
新闻来源:Dockone.io
译者介绍:李毅,中国惠普大学资深培训专家。
新一轮的服务器虚拟化浪潮看起来并不像上一次,Mark Shuttleworth如是说。Shuttleworth在十几年前发起了Ubuntu Linux项目,现在他在Canonical(运作Ubuntu的公司)公司负责战略和用户体验。
在他的领导下,和其他的Linux玩家一样,Canonical迎来并相继支持了一波又一波的虚拟化技术,从一开始的Xen hypervisor,到后来的KVM,再到Docker。Ubuntu曾支持过Eucalyptus,当。Docker及其将软件容器化的方式完全类似于虚拟化并且让云计算服务商为之癫狂,但是让Shuttleworth兴奋的是另一种称为Linux容器 (缩写为LXC)的技术及与之相应的称为LXD的Hypervisor。LXD是由Canonical开发的一个后台进程来管理这些容器并且提供了或多或少与开源的Xen及KVM、微软的Hyper-V或者VMware的ESXi这些服务器虚拟化Hypervisor类似的功能(LXD与Docker的思路不同,Docker是PAAS,LXD是IAAS)。
Shuttlworth向The Next Platform表示:“我们相信这是(LXD)十年来对Linux虚拟化最大的突破,你可以看到我们对此是多么兴奋”。
LXC容器的想法和初期的工作都是由Google完成的,容器化应用程序已经在其基础架构上运行了超过十年时间,而且据说每天会启动超过20亿的容器。Canonical和其他大约80个组织已经开始致力于LXC的商业化,因为LXC最初并不是一个对用户很友好的技术。商业化是为了让其具有常见服务器虚拟化的观感和体验,尽管它使用的是非常不同且简化的技术。
“对于容器,很多人并不了解的是我们用来配置容器的系统其实可以用很多种方法来做虚拟或者模拟”,Shuttleworth解释说,有时你希望模仿看起和Docker类似的东西,而有时你又想模拟其他的东西。就LXC而言,我们想要创建容器的途径是创建假想的主机,而不是运行操作系统的主机或者构成一个操作系统的所有进程。这与Docker完全不同,虽然它们都使用相同的底层原语,但是创建了不同的的东西。LXC的宗旨是不借助硬件虚拟化来创建虚拟机。
说起Docker,它在早期是基于LXC的但是现在它有了自己的抽象层,它更像一个运行在文件系统之上的单个进程,就好比你启动了主机但并没有运行Init和所有构成操作系统的进程而是直接运行数据库或者其他的东西,然后在一台主机上启动多个容器并把它们一起置于其中。通过LXC及其LXD守护进程,Canonical希望保持拥有一个完整Debian、CentOS、Ubuntu或其他Linux操作系统的感观。
在LXC 1.0中,常见的情景是程序员说:“给我创建这个容器”。现在我们的做法是接收代码然后将其纳入LXD守护进程来管理,因此并不需要由程序员去创建每一个容器,我可以拥有上百个虚拟机并且与LXD守护进程进行通信来进行统一管理,因此我所拥有的虚拟机集群与你使用VMware ESXi hypervisor所构建的类似。把LXC打包到一个守护进程中就使得它变成了一个hypervisor。什么是ESXi?它基本上是一个操作系统,你可以通过网络跟它通信并且让它给你创建一个虚拟机。通过LXD,你可以跟一个运行LXC的主机说给我创建一个运行CentOS的新容器。这成为一个集群的导引机制。
LXD也提供了另一个重要功能:它是运行的在两台不同物理主机上的一个软件,从而使得LXC实例能够在主机间在线地迁移。
本周,Canonical发布了首次包括LXD hypervisor的LXC 2.0 beta版本。在本月将要发布的Ubuntu Server 15.10的更新中就包括这两个组件,而Canonical也通过统一步骤把LXC 2.0反推入Ubuntu Server 14.04 LTS(LTS是Long Term Support的缩写)的服务器版本。LTS版本每两年发布一次而且具有五年的支持生命期。由于它的稳定性有保证,所以70%的客户都在生产环境中运行Ubuntu服务器的LTS版本。
据Shuttleworth说,包含LXD hypervisor的LXC 2.0生产级别版本将在明年亮相,根据命名方案的建议可能就在二月或者三月最迟到4月就与新的企业级版本 – Ubuntu Server 16.04 LTS一同发布。负责Ubuntu产品和战略的Dustin Kirklan对TheNext Platform说,从下一个LTS版本开始,在每一个Ubuntu Server中就会缺省安装LXC和LXD组件,这样每个主机都可以运行几十到几百个容器 –IBM在最大的使用POWER处理器的服务器上甚至可以运行数千个容器。
相比于依靠硬件虚拟化的常规虚拟机,LXC容器具有两个巨大的优势:一台主机上可以打包的容器数量和这些容器的启动速度。尽管为了在一台硬件上用不同的容器运行不同的Linux需要一些额外的工作,但是由于LXC其实就是用Linux运行Linux,所以不需要虚拟什么。
“这在性能方面前进了一步,而在密度方面的改进则是巨大的”,Shuttleworth无不得意地说:“而这对于低延迟、实时型的应用程序具有显著的改善。在云计算环境中这类事情都变得容易处理了,当然过去他们可不是这样。如果你的云平台运行了LXC,很快高性能计算可以搞定了,云计算平台上的实时计算也可以搞定了,而且如果你是一个需要低传输延迟的电信运营商的话,那么NFV(网络功能虚拟化)也可以搞定了。在这些需要巨大资金投入的领域,人们真的希望使用云计算和虚拟化,而LXC使其成为可能。这是非常令人振奋的”
Shuttleworth说LXC容器在密度方面可以达到诸如EXSi、Xen或KVM这类使用虚拟机的hypervisor的14倍,而且LXC和LXD组合在开销方面却只占基于硬件虚拟化的Hypervisor的20%不到。对于空闲的负载而言,VM和LXC容器就和大多数VM和物理主机所作的一样大部分时间在等待。对于繁忙的VM而言,LXC容器则能够提供明显要好得多的I/O吞吐量和更低的延迟。因此,对于空闲的主机你专注于整合,而对于繁忙的主机你专注于吞吐量和延迟。而且由于Hypervisor和VM的特定开销可以释放出来用于实际工作,所以你可以得到大约20%的性能提升。
现在已经开始对LXC及LXD组合进行基准测试。在上周东京召开的OpenStack峰会上,Canonical LXD开发团队的Tycho Andersen展示了一些在虚拟化环境中的测试基准,其中一个是使用Hadoop TeraSort测试而另一个是对Cassandra NoSQL数据存储的压力测试。这两个测试中,主机运行的是在峰会期间发布的最新OpenStack “Liberty”云控制器和同样刚发布的Ubuntu 15.10. 15.10,它既有KVM也有LXD hypervisor和各自的虚拟机和容器。这些服务器配备了24核和48GB内存,一个控制器负责管理OpenStack而其他三台用作基本的计算节点。
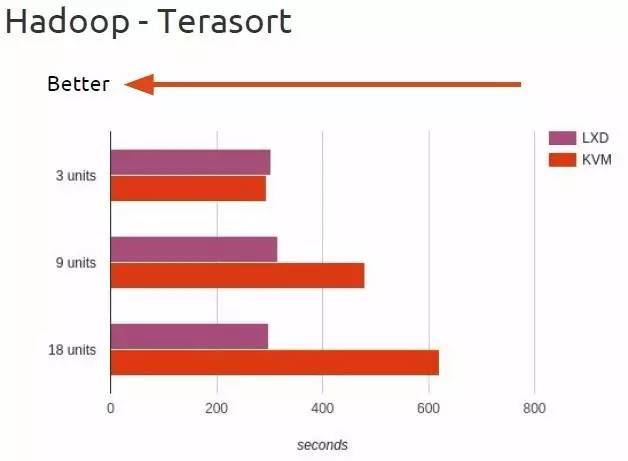
在TeraSort测试开始的时候,在三台主机上LXC和KVM的表现基本一致,但是当OpenStack/Hadoop集群中的主机数量随着数据集的规模增长后,两种不同的虚拟化手段在性能方面的差异开始显现。
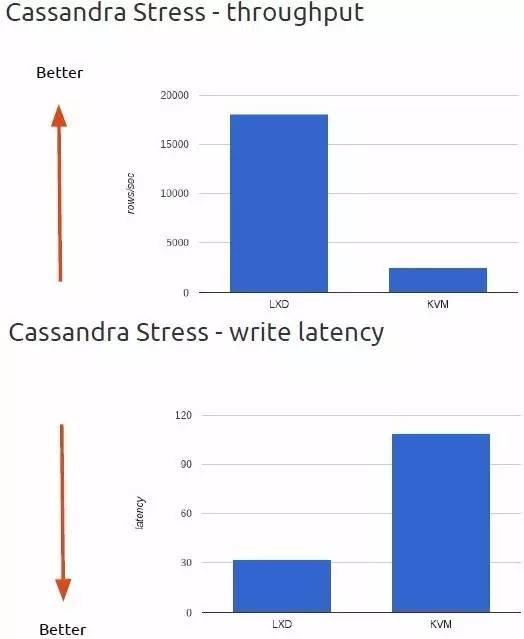
你可以看到LXC/LXD同KVM在延迟和吞吐量上的差异是非常明显的。
爱立信研究院和阿尔托大学发表了一篇很有意思的论文,它表明主机在运行LXD和Docker时比运行Xen和KVM能节省更多的能耗,你可以查看(参考阅读1)。在CPU和内存的基准测试结果中,随着更多的VM或者容器加到主机上,服务器的功率随之消耗上升而且两者之间的差距并不明显,但是当他们处理网络流量时,Docker和LXC在完成相同的工作时要少消耗10%的能耗。
由于容器的轻便特性,使得LXC容器毫无意外地用于很多云计算平台,而且极有可能成为未来基础架构云的基础 – 至少是那些只运行Linux的云基础架构平台,因为LXC不能运行在数据中心中的另一种重要操作系统 – Windows server上。但尽管如此,大多数重要的新软件是在Linux之上开发的 – Hadoop、Spark、NoSQL数据库、多种文件系统等等,所以这不会受限于人们所构建的平台的特定部分。
有意思的是正如那句俗话“吃自家的狗食”所言,现在Canonical也在用LXC容器部署他们的Ubuntu OpenStack。这使得管理员能够分步地升级OpenStack或者把部分负载从硬件上移走来发挥硬件的性能。
Shuttleworth说,在一个典型的小规模OpenStack云中你可以用八台管理节点来运行管理平台的所有组件,而且你希望以一式三份的方式来运行它,这样即使有你失去了一个节点,还能通过另外两个来保持高可用。这就需要32台物理服务器。通过把这些组件打包到LXC容器并通过LXD hypervisor进行管理,这些管理平台的大部分组件都可以打包到同一个物理服务器上从而缩减了OpenStack管理平台的物理服务器规模却不会牺牲性能和可用性。
程序员都追求简洁而且他们喜欢保持事物有序和整洁。在某种程度上,只是因为硬件虚拟化的成本很高就不得不把程序部署到多个主机上已经成了一个痛点。现在,你可以快速地在一台主机上运行多个程序而没有这些开销并且始终保持他们的原始状态和隔离。
谈起LXC,Shuttleworth告诉我们红帽很难忽视我们而且他们最终把LXC加到了RHEL 7当中,而Kirklan说尽管Canonical做了很多努力使得KVM管理工具libvirt支持LXC,但是libvirt的维护者还是专注于KVM虚拟机而非容器。所以他认为这事儿有点棘手。而Shuttleworth说:红帽一直以来想试图把容器的想法曲解为轻量级的VM,因为他们在KVM投入了大量的资金,而这就扭曲了他们的世界观。
推动LXC和LXD普及的关键因素是这样的一个事实,即企业(超大规模的)和高性能计算(HPC – High Performance Computing)中心里的大量负载都是运行在Linux之上,而且这些组织希望在迁移基础架构的时候能够保留这些应用程序。恰恰是这个需求使得VMware成为企业数据中心领域60亿美元的巨头。
作为一个例证,Shuttleworth说Canonical已经与Intel和其他一些不具名的HPC中心在LXC容器基础上利用LXD hypervisor以近乎裸机的性能来测试以前的仿真和建模代码。”想一想这是怎样的场景。现在一个超级计算机运行着管理员最喜欢的操作系统,而科学家们能够获得裸机的性能同时还可以访问他们最熟悉的操作环境。这一切都得益于虚拟化而且两者获得了所期望的东西而没有任何物理主机虚拟化带来的困惑。
私有云先行,而后公有云
LXC和LXD都不需要使用OpenStack云控制器,但是在数据中心里这三者将极有可能要在一起配合。Shuttleworth说根据OpenStack社区的最新统计,Ubuntu server支撑着全世界一半以上已安装的OpenStack云而且它也占据了最大的OpenStack集群中百分之六十五的份额。
Canonical的Ubuntu OpenStack发行版本已经被沃尔玛、AT&T、Verizon、NTT、彭博社及德国电信所采用 – 都是成功的大单。此外,上周在东京的OpenStack峰会上,Shuttleworth补充说他看到没有一个在Ubuntu上运行OpenStack的企业客户对LXD不感兴趣,因为其经济性和密度实在是太棒了。
总体而言,这些都是私有云的成功案例。Shuttleworth认为长期目标是使公有云服务商把LXC和LXD作为其基础架构和平台服务的基础,但是要实现这个目标大多数公有云服务商可能要等到X86、Power及ARM服务器拥有虚拟化专用电路来为LXC和LXD提供与KVM、Xen或者Hyper-V等同的硬件安全(当然,这和平台有关)。当前,Linux社区能够为LXC容器提供Linux内核内的安全防护,但是这对于云服务提供商而言是不够的。至于这些功能合适会加入到至强、Opteron、Power和ARM芯片中还不得而知,而且Shuttleworth也没有透漏Canonical的硬件合作伙伴的路线图。
参考阅读1:http://arxiv.org/abs/1511.01232
以下另外一篇网上流传比较多的文章,供各位参考
虚拟机已死 "容器"才是未来?
我也曾经是容器技术尤其是 Docker 粉丝,但用了一年后觉得事情也没那么美好,而颇有一些同学以及一些公司依然认为容器就是银弹,虚拟机已经是昨儿黄花必须打倒,大家赶紧一切皆容器。这里我 对这种观点吐吐槽。仅代表作者个人看法首先要明确的是,软件开发和运维活动中,可维护性、正确性、性能的优先级是依次降低的,不要跟我抬杠少数极端情况。
关于可维护性和正确性的先后,著名的 “worse is better” 文章就是很好的无奈的解释,如果你犹豫这两者,这还情有可原,毕竟真善美和糙快猛的斗争从未停歇,而你如果第一反应觉得性能是最重要的,那就不要继续往下看了,洗洗去睡吧——适合的才是最好的。
那么对于虚拟机 vs 容器,自然我们也需要从这三方面考察。
回合一:可维护性之争
虚拟机—维护性
从 hypervisor 讲,Xen/KVM/vSphere/HyperV 都很成熟了,久经考验,BSD 也在凑热闹搞 bhyve(FreeBSD) 和 vmm(OpenBSD),最近 unikernel 也在试图跑在 hypervisor 上,而 AWS/GCE/Azure 等等云计算巨头以及 Intel/AMD 等在CPU、磁盘和网络IO虚拟化技术上的投资显然不会立马推翻,Linux 上虚拟机的开源管理方案也已成熟定型:libvirt, OpenStack,没人吃饱了撑的去弄个 “新的开源” 项目替换它们,虽然我很不喜欢 OpenStack 的乱糟和复杂。VM 的动态迁移也是成熟技术,出来好多年了,实现原理非常简单,反正整个 OS 内存一锅端弄过去,不操心少个依赖进程的内存没过去。想用不同版本内核? 想要自定义内核模块?想调整内核参数?期望更安全的隔离?期望如同物理机版几乎一致的使用体验?VM 就是虚拟机的缩写嘛,这些都是拿手戏。
容器— 维护性
Linux 容器,Linux 一贯的作风,慢慢演化,不求仔细设计,然后就是 cgroup, pid/uts/ipc/net/uid namespace 一个个实现出来,凑出一个容器技术,貌似 uid namespace 还是最近刚刚出来的特性。用户空间则更是群雄并起,LXC,Docker,rkt,LXD,各有拥蹇,鹿死谁手,还真不好说,在这个局还没明朗的时候,Mesos、Swarm、Kubernetes、Nomad 又出来一堆搅局的,眼下看来最吸引眼球的 Kubernetes 俨然有 OpenStack 继任者的感觉,但依然很嫩,没几个人敢在生产环境大规模使用。
Linux容器里进程的跨机器动态迁移我还没听说,不要说是个服务就得有集群有 HA 嘛,可还真有不少用户一个服务就单机顶着呢,就算有热备或者冷备,在线那台机器内存里的东西可宝贵了,轻易不能丢。用Linux容器就不能挑内核,不能加载内核模块,不能挂载文件系统,不能调整内核参数,不能改网络配置,等等,不要告诉我你能——你是不是开了 docker run –privileged 了? 你是不是没 drop capability?你是不是没有 remap uid?话说某大公司的容器还真就用 –privileged 选项跑的呢。 而 Linux 的隔离不彻底恐怕大部分人都没意识到,/sys, /dev, /selinux 还有 /proc 下的某些关键文件比如 /proc/kcore 没隔离呢。
Redhat 做的 project Atomic 意识到这些问题,正在积极的给 Docker 加 SELinux 支持,指定 SELinux policy,但 Docker 官方爱搭不理,而且 SELinux 这种高端技术是凡人玩的么? 结局大概依然是 “FAQ 1: 关掉 SELinux”。Linux 容器本来并不局限在一个容器里跑几个进程,但 Docker 官方为了加强“轻量级”这词的洗脑效果,搞出个无比脑残的 single process 理念,被无数人捧臭脚,所幸有些人慢慢意识到问题,Yelp 搞了个 dumb-init 擦了一半屁股,还有无数 docker image 用 runit、supervisor 之类的做 /sbin/init 替换,但问题在于这要自定义启动脚本,需要加 ssh/cron/syslog/logrotate 等等边角料——这已然是解决了无数遍的问题,还要解决一遍,不觉得麻烦吗?难道没有人认为这些包的作者或者打包者更善于处理服务启动脚本么?像 systemd 那种搞法还算正道,特意考虑容器环境,跳过一些步骤,但貌似还没做完善,需要手动删除一些 .service 文件。
虚拟机 vs 容器
也许有人会说 docker pull/push 多方便啊,docker build 多方便啊,可不要忘了,vm image storage 早在 openstack 里就解决了,自己处理也不是个大事,vm image build 也有 Hashicorp 的 Packer 工具代劳,不是个事。Docker 自豪的官方 docker registry 其实大家最多用用 base os image,那些 app 级别的出于信任以及定制考虑都会自己 build。而 Docker 自豪的 layered storage 也是无数血泪,aufs & overlayfs 坑了多少人?容器社区最近还特崇拜 immutable deployment,以把容器根文件系统弄做只读的为荣,全然不管有紧急安全更新或者功能修正怎么处理——什么,你要说 docker rm && docker run 再起一批不就完事么?真有这么简单就好了。
像 Linux kernel 和 git 那种才是正经 unix 设计的思想,分层堆叠,底层提供mechanism,高层提供 policy,各取所需,可惜人总是易于被洗脑,在接受各种高大上policy的时候全然忘了mechanism还在不在自己手里。
回合二:正确性之争
强隔离、full OS 体验、保留 mechanism,这才是正道。另外容器还隐藏了一个坑,/proc/cpuinfo和free命令输出是host os的,这坑了无数探测系统资源自动决定默认线程池和内存池大小的程序,尤以Java最为普遍。
回合三:性能之争
容器粉丝津津乐道——启动容器快,容器的开销少。 这两点确实如此但好处真的有那么巨大么?谁有事没事不停创建虚拟机?谁的虚拟机生命周期平均在分钟级别?谁的“用完全启动时间”平均在秒级? 至于说到虚拟机浪费的资源太多,其实也就是个障眼法。理论上服务器的资源利用率平均不应该超过 80%而实际上绝大部分公司的服务器资源利用率应该都不到 50%,大量的CPU、内存、本地磁盘都是常年浪费的,所以 VM 的额外开销不过是浪费了原本就在浪费的资源罢了。就单机的巅峰 I/O 能力来言,VM 确实不敌容器。但平时根本就用不到巅峰状态, 原本一个 VM 里多进程干的事,非得搞多个容器跑,这容器开销,这人力开销怎么算?
关于容器还有一个幻想,那就是可以在物理机上直接跑容器,开销巨低、管理巨方便,用专用物理机方式提供多租户强隔离。前面两点上面已经驳过了,话说还有人用 openstack 管理 docker 容器呢。 我只是说一下第三点,在一台物理机上直接跑容器的一个最容易被忽视的问题:现在用来提供云服务的物理机一般都是硬件超级牛逼,跑上百个容器都没问题,但问题在于用户很可能只需要几个容器,所以要么跟人共用物理机,要么浪费资源白交钱。哪怕用户需要上百个容器,出于容灾考虑,也不可以把上百容器部署到一台物理机上,所以还是要么跟人共用物理机,要么浪费资源。
方案
以上是我的观点,我并不是“容器黑”,而是“实用白”。AWS、Azure、GCE 都主推在虚拟机上跑容器,按虚拟机收费,这非常明智的解决了问题:老的纯 VM 基础设施不用动,计费照旧,单物理机可以被安全的多租户共用,资源隔离有保证(起码比共享内核强多了),把容器管理软件如“kubernetes”给用户,既满足用户的容器需求,又不担心容器的多租户问题。
所以我认为:以 VM 为基础,以容器为辅助点,要买就买 VM,自己管理容器,别买 CAAS 直接提供的容器,别看不到底下物理机或者虚拟机。用 VM 还是用容器,冷静考察自己的应用上容器是否有好处。最后,残念,VM 开源管理软件能搞个比 OpenStack 简单的东西吗?
原文链接:http://blog.163.com/guaiguai_family/blog/static/2007841452016229115555875?from=timeline&isappinstalled=0
相关阅读:
以上是关于容器将完全颠覆虚拟化的主要内容,如果未能解决你的问题,请参考以下文章