KubeVirt上的虚拟化GPU工作负载
Posted CNCF
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KubeVirt上的虚拟化GPU工作负载相关的知识,希望对你有一定的参考价值。
在这段2019年北美KubeCon视频中,Red Hat的David Vossel和NVIDIA的Vishesh Tanksale探索了KubeVirt背后的架构,以及NVIDIA如何利用该架构为Kubernetes上的GPU工作负载提供动力。以NVIDIA的GPU工作负载为例进行研究,它们提供了一个重点视图,以了解主机设备透传是如何通过KubeVirt完成的,并提供了一些性能指标,将KubeVirt与独立KVM进行比较。
https://www.youtube.com/watch?v=Qejlyny0G58
https://v.qq.com/x/page/s3031occ4r7.html
KubeVirt介绍
David介绍了KubeVirt是什么和不是什么:
KubeVirt不参与管理AWS或GCP实例
KubeVirt不是Firecracker或Kata容器的竞争对手
KubeVirt不是一个容器运行时替换
他喜欢把KubeVirt定义为:
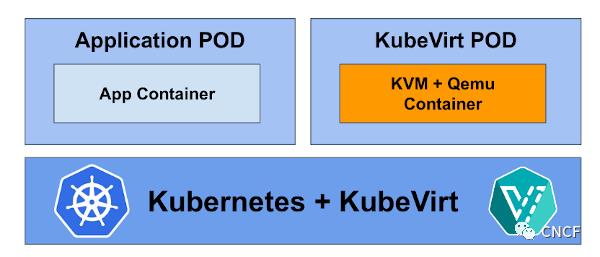
KubeVirt是Kubernetes的一个扩展,它允许与容器工作负载一起原生运行传统的VM工作负载。
但是为什么需要KubeVirt呢?
已经有了像OpenStack、oVirt这样的本地解决方案
然后是公共云,AWS、GCP、Azure
为什么我们又要做VM管理的事情呢?
答案是,最初的动机是基础设施的融合:
迈向云模型的转型包括多个栈、容器和VM、旧代码和新代码。KubeVirt简化了这一切,只需要一个栈来管理容器和VM来运行旧代码和新代码。

工作流的融合意味着:
将VM管理合并到容器管理工作流中
对容器和虚拟机使用相同的工具(kubectl)
保持用于VM管理的声明性API(就像pod、deployment等…)
YAML中VM实例的一个例子可以像下面这样简单:
$ cat <<EOF | kubectl create -f -apiVersion: kubevirt.io/v1alpha1kind: VirtualMachineInstance...spec:domain:cpu:cores: 2devices:disk: fedora29
架构
事实是,KubeVirt VM是在pod中运行的KVM+qemu进程。就是这么简单。
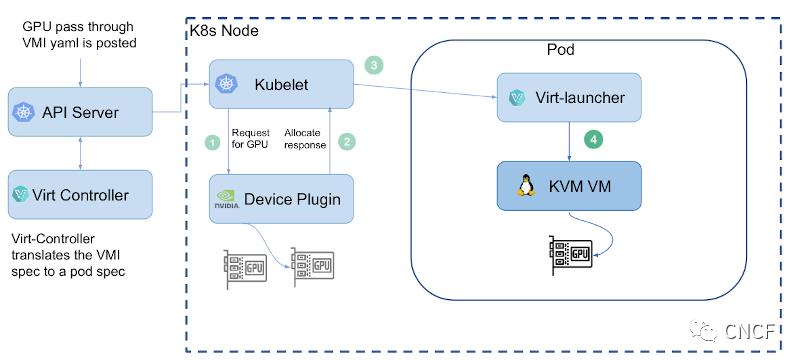
VM启动流程如下图所示。用户向集群发布VM清单,直到Kubelet启动VM pod。最后,virt-handler指示virt-launcher如何启动qemu。

KubeVirt中的存储以与pod相同的方式使用,如果需要在VM中有持久存储,则需要创建PVC(持久卷声明)。

例如,如果您的电脑中有一个VM,您可以使用容器数据导入器(containerized-data-importer,CDI)将该镜像上载到PVC,然后您可以将该PVC附加到VM pod以使其运行。
关于网络服务的使用,流量以与容器工作负载相同的方式路由到KubeVirt VM。Multus还可以为每个VM提供不同的网络接口。
For using the Host Resources:
VM Guest CPU and NUMA Affinity
CPU Manager (pinning)
Topology Manager (NUMA nodes)
VM Guest CPU/MEM requirements
POD resource request/limits
VM Guest use of Host Devices
Device Plugins for access to (/dev/kvm, SR-IOV, GPU passthrough)
POD resource request/limits for device allocation
在Kubevirt虚拟机的GPU/vGPU
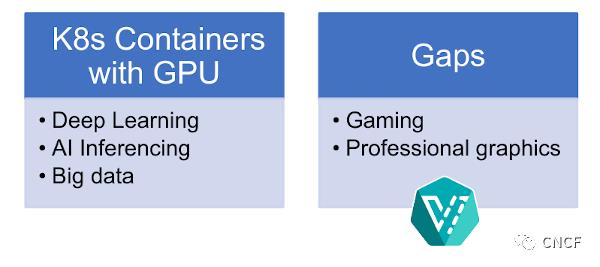
在David的介绍之后,Vishesh接手并深入讨论了VM中GPU的原因和方法。许多新的机器和深度学习应用程序正在利用GPU处理工作负载。如今,大数据是GPU的主要消费者之一,但仍有一些差距,游戏和专业图形部门仍然需要运行VM和具有原生GPU功能,这就是为什么NVIDIA决定与KubeVirt合作。
NVIDIA已经开发了KubeVirt GPU设备插件,它可以在GitHub上获得,它是开源的,任何人都可以查看并下载它。
使用设备插件框架是向GPU提供对Kubevirt虚拟机访问的自然选择,下图显示了涉及到GPU透传架构的不同层:

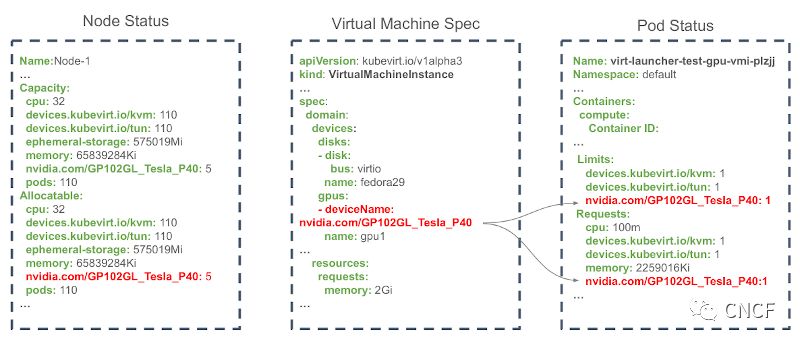
Vishesh还说明YAML代码的一个例子,可以看到包含NVIDIA的节点状态卡信息(节点有5个GPU),包含deviceName的虚拟机规范指向NVIDIA卡和Pod状态,用户可以设置资源的限制和要求。
The main Device Plugin Functions are:
GPU and vGPU device Discovery
GPUs with VFIO-PCI driver on the host are identified
vGPUs configured using Nvidia vGPU manager are identified
GPU and vGPU device Advertising
Discovered devices are advertised to kubelet as allocatable resources
GPU and vGPU device Allocation
Returns the PCI address of allocated GPU device
GPU and vGPU Health Check
Performs health check on the discovered GPU and vGPU devices
为了理解GPU是如何通过生命周期工作的,Vishesh用下图展示了不同阶段的过程:
在下面的图表中,有一些NVIDIA使用KubeVirt的关键功能:

如果您对生命周期如何工作的细节感兴趣,或者对NVIDIA为什么高度使用上面列出的KubeVirt特性感兴趣,您可能会对下面的视频感兴趣。
视频
https://static.sched.com/hosted_files/kccncna19/31/KubeCon%202019%20-%20Virtualized%20GPU%20Workloads%20on%20KubeVirt.pdf
演讲者
David Vossel是红帽公司的首席软件工程师。他目前正致力于OpenShift的容器原生虚拟化(Container Native Virtualization,CNV),并且是开源KubeVirt项目的核心贡献者。
Vishesh Tanksale目前是NVIDIA的高级软件工程师。他专注于在Kubernetes集群上启用VM工作负载管理的不同方面。他对VM上的GPU工作负载特别感兴趣。他是CNCF Sanbox项目Kubevirt的积极贡献者。
点击文末<<阅读原文>>进入网页了解更多。
 :关于中国KubeCon + CloudNativeCon + 开源峰会
:关于中国KubeCon + CloudNativeCon + 开源峰会
:
扫描二维码联系我们,加入中国最终用户支持者计划!
CNCF (Cloud Native Computing Foundation)成立于2015年12月,隶属于Linux Foundation,是非营利性组织。
CNCF(云原生计算基金会)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式民主化,让这些创新为大众所用。请长按以下二维码进行关注。
以上是关于KubeVirt上的虚拟化GPU工作负载的主要内容,如果未能解决你的问题,请参考以下文章
KubeVirt with YRCloudFile 擦出创新的火花