Kafka监控架构设计
Posted 朱小厮的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka监控架构设计相关的知识,希望对你有一定的参考价值。
目前的Kafka监控产品有很多,比如Kafka Manager、 Kafka Monitor、KafkaOffsetMonitor、Kafka Web Console、Burrow等,都有各自的优缺点,就个人而言用的最多的还是Kafka Manager,不过这些并不是十分的完美。如果有条件,自定义实现一套符合自身公司业务特色与发展的监控系统尤为重要。本文主要讲述笔者个人对Kafka监控架构的认知与想法。
Kafka监控主要分为数据采集、数据存储以及数据展示3个部分。
数据采集主要从各种数据源采集监控数据并做一些必要的运算然后发送给数据存储模块进行存储。数据源可以是kafka-zk、kafka自身(消费__consumer_offset)、JMX(主要是通过JMX来监控kafka的指标,故kafka启动的时候需要指定JMX_PORT)、zabbix(或者其他类似的工具,主要用来监控集群硬件指标)。
数据存储是指将采集的原始数据经过一定的预处理后进行相应的存储,方便数据清洗(这个步骤可以省略)和数据展示。数据存储可以采用Opentsdb之类的基于时间序列的数据库,方便做一些聚合计算。
数据展示,顾名思义是将经过预处理的、存储的数据展示到监控页面上,提供丰富的UI给用户使用。当然数据展示模块也可以绕过数据存储模块直接向数据采集模块,亦或者是数据源直接拉取数据。至于数据是从存储模块拉取还是更底层的源头拉取,要看是否需要历史时间段的值或者是是否需要最新值。
经过上面的分析整个监控系统可以大致概括为以下的模型:
不过上面的模型架构只是针对单一集群以及单机版的Collector,如果涉及到多个集群,就需要考虑均衡负载以及HA等方面的因素。我们针对这个模型做进一步的改进,主要是针对数据采集模块的改进,如下图所示:
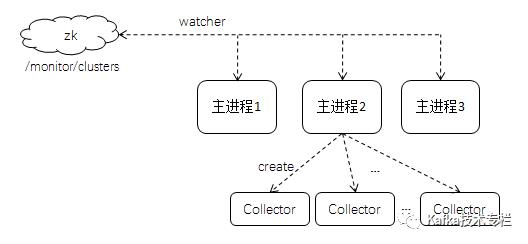
这里有几点需要说明:
1. 各个主进程的“抢占”可以通过zookeeper自身的功能实现,通过在/monitor/pids/路径下创建相应的虚节点,如果创建成功则说明抢占成功,反之则失败。
2. 在/monitor/pids/路径下创建虚节点是在Collector中创建的而不是在主进程中创建的,也就是说主进程监听到新节点的加入首先是创建Collector的实例,然后Collector的实例再创建对应的虚节点,如果创建成功则告知主进程创建成功,如果创建失败则返回失败。
3. Collector之后再初始化一些进行资源采集的资源,比如与kafka-zk、kafka等建立连接。如果初始化成功则可以进行数据采集;如果失败则关闭自身,对应的虚节点的session也随之结束,也就意味着对应虚节点的自动删除。
4. 主进程也要监听/monitor/pids/路径下的节点变化,一旦监听到节点增加则说明某个原本自身要抢占创建的已被其他主进程抢占。在2中所说的Collector创建虚节点成功与否告知主进程,其实这里也可以省去这一步,主进程可以监听/monitor/pids/路径的变化来感知是否创建成功。主进程一旦监听到/monitor/pids/路径下的节点减少,则首先判断这个节点是否在/monitor/clusters/下存在,如果不存在则不做处理,如果存在则启动抢占任务。
5. 主进程和子进程可以通过ProcessBuilder来实现。
6. 主进程自身可以抢占创建/monitor/pids/路径下的虚节点,然后监控Collector进程状态。如果Collector进程假死,而主进程无法直观感知,所以就将创建虚节点并保持session的工作就留给了Collector子进程。
7. 主进程和子进程的关系也可以演变为进程和线程的对应关系,但是这样改变之后对各个集群的日志存盘以及问题的追踪会添加不必要的麻烦。
下面我们再来探讨下数据存储和数据展示这两者之间的关系。正常逻辑下,监控页面通过调取数据存储模块的api来获取数据并展示在页面上。试想下如果一个监控页面需要调取几十个指标,然后还要经过一定的计算之后才展示到页面之上,那么这个页面的渲染速度必然会受到一定的限制。
就拿指标UnderReplicatedPartitions来说,如果只能用一个指标来监控Kafka,那么非它莫属。UnderReplicatedPartitions表示集群中副本处于同步失败或失效状态的分区数,即ISR<AR。这个指标的获取也很简单,通过JMX调取kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions。UnderReplicatedPartitions的值为0则大吉大利,如果大于0则需要很多步骤来检测异常原因,比如:检测是否只发生在一个topic上;检测是否只发生在一个broker上;如果不是前两种,极可能是集群原因,那么集群原因又可能是由于负载不均衡导致的等等(UnderReplicatedPartitions的异常评估可以参考笔者下一篇文章)。UnderReplicatedPartitions背后要伴随着一堆的指标来评估异常的缘由,就以负载不均衡来说,还涉及到复杂的计算:一个Broker的负载涉及其所承载的partitions的个数、leaders的个数、网络读写速度、IO读写速度、CPU使用率等,要评判一个集群中是否有负责不均衡的情况出现,就需要将这些指标进行归一化处理,然后再做均方差,如果超过设定的阈值即可评判集群发生了负载不均衡的现象。如果监控页面从opentsdb中发送多个请求获取原始数据,然后再内部进行复杂的计算之后再程序在页面上,这个过程的耗时可以想象。更令人忧伤的是这么多的过程只是用来展示了一个指标,而一个页面的呈现可能要涉及到很多个指标。
有了问题我们就需要解决它,这里笔者引入了一个新的模块ComputeServer来进行数据预处理,然后将处理后的数据以HTTP RESTful API接口的方式提供给下游。下游的监控页面和存储模块只需要通过这个接口读取数据即可,无需过多的计算,从而提升了效率。新的架构模型如下图所示:
上图还引入了一个kafka的模块,这个主要是用来将多个Collector与ComputeServer解耦,如果多个悬而未定Collector与ComputeServer直接交互必然是一个浩大工程。Kafka模块可以针对每个集群创建对应的topic;亦或者是创建一个单独的topic,然后划分多个partition,每个集群的ID或者名称作为消息的Key来进行区分。后者不必强求每个集群对应到独立的partition中,ComputeServer在消费的时候可以获取Key来辨别集群。而消息的Value就是Collector采集的原始数据,这里的消息的大小有可能超过Kafka Broker的默认单条消息的大小1000012B,不过笔者不建议调高这个值以及对应人max.request.size和max.partition.fetch.bytes参数的大小。可以开启压缩或者在Collector拆包以及在ComputeServer端解包的方式来进一步的解决消息过大的问题。还有一个就是这里的Kafka不建议开启日志压缩的功能,因为Kafka不仅是一个功能稍弱的消息中间件,同时也是一个功能弱化的时间序列数据库,Kafka本身可以根据时间范围来拉取对应的消息。在opentsdb不可靠的时候,完全可以使用kafka替代,只不过kafka出来的数据需要多做有些聚类运算。
在上图中的①和②可以加入数据清洗逻辑亦或者是告警逻辑,将异常数据拦截出来,传入其他的告警系统等来做进一步的处理。
上图中的ComputeServer的HA可以简单的通过LVS+Keepalived实现。
至此,一个包含数据采集+计算+存储+展示的监控架构已经聊完。后面会另有文章来细说下Kafka中的监控指标以及其背后的含义。
以上是关于Kafka监控架构设计的主要内容,如果未能解决你的问题,请参考以下文章