kafka连接器两种部署模式详解
Posted 浪尖聊大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka连接器两种部署模式详解相关的知识,希望对你有一定的参考价值。
一 kafka Connector介绍
Kafka Connect是一个用于在Apache Kafka和其他系统之间进行可扩展和可靠数据流传输的工具。这使得快速定义将大量数据传入和传出Kafka的连接器变得很简单。Kafka Connect可以接收整个数据库或从所有应用程序服务器收集指标到Kafka主题中,使得数据可用于低延迟的流处理。导出作业可以将来自Kafka主题的数据传送到二级存储和查询系统或批处理系统中进行离线分析。
Kafka Connect功能包括:
Kafka连接器的通用框架 - Kafka Connect将其他数据系统与Kafka的集成标准化,简化了连接器的开发,部署和管理
分布式和独立模式 - 扩展到支持整个组织的大型集中管理服务,或者缩减到开发,测试和小型生产部署
REST接口 - 通过易于使用的REST API提交和管理Kafka Connect群集的连接器
自动偏移管理 - 只需要连接器的一些信息,Kafka Connect可以自动管理偏移提交过程,所以连接器开发人员不需要担心连接器开发中容易出错的部分
默认情况下是分布式和可扩展的 - Kafka Connect基于现有的组管理协议。可以添加更多的工作人员来扩展Kafka Connect群集。
流媒体/批量整合 - 利用Kafka现有的功能,Kafka Connect是桥接流媒体和批量数据系统的理想解决方案
Kafka Connect目前支持两种执行模式:独立(单进程)和分布式。在独立模式下,所有的工作都在一个单进程中进行的。这样易于配置,在一些情况下,只有一个在工作是好的(例如,收集日志文件),但它不会从kafka Connection的功能受益,如容错。
分布式的模式会自动平衡。允许你动态的扩展(或缩减),并在执行任务期间和配置、偏移量提交中提供容错保障。
二 kafka Connector实战
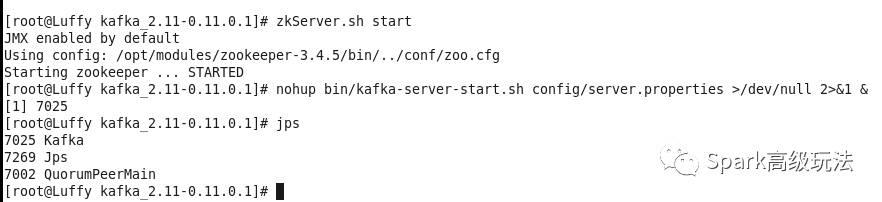
1 启动kafka
zkServer.sh start
nohup bin/kafka-server-start.sh config/server.properties >/dev/null 2>&1 &
2 Standalone模式下测试Connector
准备数据
[root@Luffy kafka_2.11-0.11.0.1]# echo -e "foo bar" > test.txt
启动两个Connector,一个Connector负责往kafka的topic(connect-test)写数据,一个Connector负责从connect-test读数据,写入test.sink.txt文件
bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
注:
这时候数据文件和输出文件(test.txt和test.sink.txt)都在kafka的安装根目录下。
connect-file-source.properties配置文件内容如下:
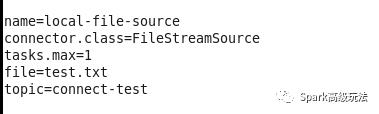
connect-file-sink.properties配置文件内容如下:

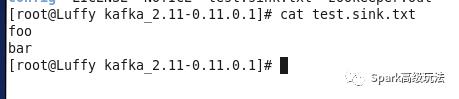
结果展示,在test.sink.txt输出内容
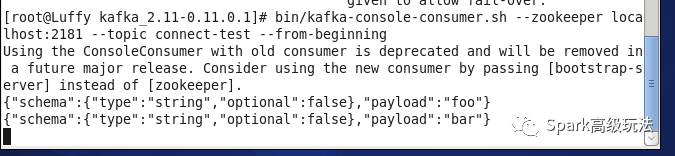
使用消费者命令消费connect-test得到的数据
只启动connect-file-source,好像是启动了一个监控文件并且是kafka sink的flume。
3 Distributed模式
首先是启动
bin/connect-distributed.sh config/connect-distributed.properties
接着是使用curl启动一个Connector,跟上步骤测试一样,从/opt/modules/kafka_2.11-0.11.0.1/test.txt读取数据,发送到connect-test。
实际上,Distributed模式只能是以restful API的形式进行Connector操作。
启动一个Connector:
curl -H "Content-Type: application/json" -X POST -d '{"name":"local-file-source","config":{"connector.class":"FileStreamSource","tasks.max":"1","topic": "connect-test","file":"/opt/modules/kafka_2.11-0.11.0.1/test.txt"}}' http://192.168.1.103:8083/connectors
创建之后,我们可以通过restful API获取正在运行的Connector。

然后,往test.txt文件里追加数据测试

也可以通过下面指令删除Connector
curl -X "DELETE" http://192.168.1.103:8083/connectors/local-file-source
4 支持的rest api
由于Kafka Connect旨在作为服务运行,因此还提供了用于管理连接器的REST API。默认情况下,此服务在端口8083上运行。以下是当前支持的端点
GET /connectors - 返回活动连接器的列表
POST /connectors - 创建一个新的连接器; 请求主体应该是包含字符串name字段和config带有连接器配置参数的对象字段的JSON对象
GET /connectors/{name} - 获取有关特定连接器的信息
GET /connectors/{name}/config - 获取特定连接器的配置参数
PUT /connectors/{name}/config - 更新特定连接器的配置参数
GET /connectors/{name}/status - 获取连接器的当前状态,包括连接器是否正在运行,失败,已暂停等,分配给哪个工作者,失败时的错误信息以及所有任务的状态
GET /connectors/{name}/tasks - 获取当前为连接器运行的任务列表
GET /connectors/{name}/tasks/{taskid}/status - 获取任务的当前状态,包括如果正在运行,失败,暂停等,分配给哪个工作人员,如果失败,则返回错误信息
PUT /connectors/{name}/pause - 暂停连接器及其任务,停止消息处理,直到连接器恢复
PUT /connectors/{name}/resume - 恢复暂停的连接器(或者,如果连接器未暂停,则不执行任何操作)
POST /connectors/{name}/restart - 重新启动连接器(通常是因为失败)
POST /connectors/{name}/tasks/{taskId}/restart - 重启个别任务(通常是因为失败)
DELETE /connectors/{name} - 删除连接器,停止所有任务并删除其配置
Kafka Connect还提供了用于获取有关连接器插件信息的REST API:
GET /connector-plugins - 返回安装在Kafka Connect集群中的连接器插件列表。请注意,API仅检查处理请求的worker的连接器,这意味着您可能会看到不一致的结果,尤其是在滚动升级期间,如果添加新的连接器jar
PUT /connector-plugins/{connector-type}/config/validate - 根据配置定义验证提供的配置值。此API执行每个配置验证,在验证期间返回建议值和错误消息。
三 kafka Connector运行详解
Kafka Connect目前支持两种执行模式:独立(单进程)和分布式。
1 运行模式配置
在独立模式下,所有的工作都在一个进程中完成。这种配置更容易设置和开始使用,在只有一名员工有意义(例如收集日志文件)的情况下可能会很有用,但却不会从Kafka Connect的某些功能(例如容错功能)中受益。您可以使用以下命令启动独立进程:
bin/connect-standalone.sh config/connect-standalone.properties connector1.properties [connector2.properties ...]
第一个参数是worker的配置。这包括诸如Kafka连接参数,序列化格式以及提交偏移的频率等设置。提供的示例应该能够正常运行,并使用默认的配置运行config/server.properties。这将需要调整使用不同的配置或生产部署。所有工作人员(独立和分布式)都需要一些配置:
bootstrap.servers - 用于引导与Kafka连接的Kafka服务器列表
key.converter - 转换器类用于在Kafka Connect格式和写入Kafka的序列化表单之间进行转换。这将控制写入Kafka或从Kafka读取的消息中的密钥格式,因为这与连接器无关,所以它允许任何连接器使用任何序列化格式。常见格式的例子包括JSON和Avro。
value.converter - 转换器类用于在Kafka Connect格式和写入Kafka的序列化表单之间进行转换。这将控制写入Kafka或从Kafka读取的消息中的值的格式,因为这与连接器无关,所以它允许任何连接器使用任何序列化格式。常见格式的例子包括JSON和Avro。
特定于独立模式的重要配置选项是:
offset.storage.file.filename - 文件来存储偏移量数据
此处配置的参数适用于由Kafka Connect使用的生产者和消费者访问配置,偏移和状态topics。对于Kafka source 和Kafka sink的结构中,可以使用相同的参数,但需要与前缀consumer.和producer.分别。从worker配置继承的唯一参数是bootstrap.servers,大多数情况下是足够的,因为同一个群集通完成于所有目的。一个值得注意的例外是安全的集群,它需要额外的参数来允许连接。这些参数需要在工作人员配置中设置三次,一次用于管理访问,一次用于Kafka Sink,一次用于Kafka source。
其余参数是连接器配置文件。你可以包括尽可能多的,但所有将在相同的进程(在不同的线程)执行。
分布式模式处理Work的自动平衡,允许您动态扩展(或缩小),并提供活动任务以及配置和偏移量提交数据的容错能力。执行与独立模式非常相似:
bin/connect-distributed.sh config/connect-distributed.properties
connect-distributed.properties配置文件决定配置的存储位置,如何分配工作以及存储偏移量和任务状态的位置。在分布式模式下,Kafka Connect将偏移量,配置和任务状态存储在Kafka topic中。建议手动创建偏移量,配置和状态的主题,以实现所需的分区数量和复制因子。如果在启动Kafka Connect时尚未创建topic,则将使用缺省的分区数量和复制因子自动创建主题,这可能不是最适合其使用的主题。
特别是,除了上面提到的常用设置之外,下列配置参数在启动集群之前对设置至关重要:
group.id(默认connect-cluster) - 群集的唯一名称,用于形成Connect集群组; 请注意,这不能与消费者组ID 相冲突
config.storage.topic(默认connect-configs) - 用于存储连接器和任务配置的topic; 请注意,这应该是单个分区,多副本, compacted topic。需要手动创建。
offset.storage.topic(默认connect-offsets) - 用于存储偏移量的主题; 这个主题应该有多分区,多副本,并被配置为压缩
status.storage.topic(默认connect-status) - 用于存储状态的主题; 这个主题可以有多个分区,多副本和配置压缩
请注意,在分布式模式下,连接器配置不能在命令行上传递。而是使用REST API来创建,修改和销毁连接器。
2 配置连接器
连接器配置是简单的key-value map。对于独立模式,这些在属性文件中定义,并在命令行上传递给Connect进程。在分布式模式下,它们将被包含在创建(或修改)连接器的请求的JSON字符中。
大多数配置都依赖于连接器,所以在这里不能概述。但是,有几个常见的选择:
name - 连接器的唯一名称。试图用相同的名称再次注册将失败。
connector.class - 连接器的Java类
tasks.max - 应为此连接器创建的最大任务数。如果连接器无法达到此级别的并行性,则连接器可能会创建较少的任务。
key.converter - (可选)覆盖由worker设置的默认密钥转换器。
value.converter - (可选)覆盖由worker设置的默认值转换器。
该connector.class配置支持多种格式:该连接器的类的全名或别名。如果连接器是org.apache.kafka.connect.file.FileStreamSinkConnector,则可以指定该全名,也可以使用FileStreamSink或FileStreamSinkConnector来缩短配置。
sink连接器还有一个额外的选项来控制其输入:
topics - 用作此连接器输入的主题列表
对于任何其他选项,您应该查阅连接器的文档。
常见的Connector使用,莫过于:
1,kafka->hdfs
2,msyql->kafka
3,logfile->kafka
推荐阅读:
1,
2,
3,
4,
以上是关于kafka连接器两种部署模式详解的主要内容,如果未能解决你的问题,请参考以下文章