实战Apache Kafka:下一代分布式消息系统
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战Apache Kafka:下一代分布式消息系统相关的知识,希望对你有一定的参考价值。
Apache Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
Apache Kafka与传统消息系统相比,有以下不同:
它被设计为一个分布式系统,易于向外扩展;
它同时为发布和订阅提供高吞吐量;
它支持多订阅者,当失败时能自动平衡消费者;
它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
本文将重点介绍Apache Kafka的架构、特性和特点,帮助我们理解Kafka为何比传统消息服务更好。
我将比较Kafak和传统消息服务RabbitMQ、Apache ActiveMQ的特点,讨论一些Kafka优于传统消息服务的场景。在最后一节,我们将探讨一个进行中的示例应用,展示Kafka作为消息服务器的用途。这个示例应用的完整源代码在GitHub。关于它的详细讨论在本文的最后一节。
架构
首先,介绍一下Kafka的基本概念。它的架构包括以下组件:
话题(Topic)是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名。
生产者(Producer)是能够发布消息到话题的任何对象。
已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群。
消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
图1:Kafka生产者、消费者和代理环境
生产者可以选择自己喜欢的序列化方法对消息内容编码。为了提高效率,生产者可以在一个发布请求中发送一组消息。下面的代码演示了如何创建生产者并发送消息。
生产者示例代码:
producer = new Producer(…);
message = new Message(“test message str”.getBytes());
set = new MessageSet(message);
producer.send(“topic1”, set);
为了订阅话题,消费者首先为话题创建一个或多个消息流。发布到该话题的消息将被均衡地分发到这些流。每个消息流为不断产生的消息提供了迭代接口。然后消费者迭代流中的每一条消息,处理消息的有效负载。与传统迭代器不同,消息流迭代器永不停止。如果当前没有消息,迭代器将阻塞,直到有新的消息发布到该话题。Kafka同时支持点到点分发模型(Point-to-point delivery model),即多个消费者共同消费队列中某个消息的单个副本,以及发布-订阅模型(Publish-subscribe model),即多个消费者接收自己的消息副本。下面的代码演示了消费者如何使用消息。
消费者示例代码:
streams[] = Consumer.createMessageStreams(“topic1”, 1)
for (message : streams[0]) {
bytes = message.payload();
// do something with the bytes
}
Kafka的整体架构如图2所示。因为Kafka内在就是分布式的,一个Kafka集群通常包括多个代理。为了均衡负载,将话题分成多个分区,每个代理存储一或多个分区。多个生产者和消费者能够同时生产和获取消息。
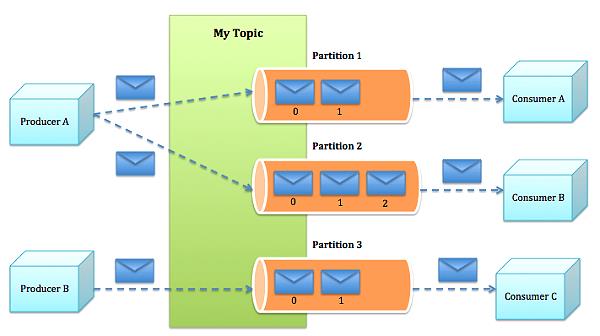
图2:Kafka架构
Kafka存储
Kafka的存储布局非常简单。话题的每个分区对应一个逻辑日志。物理上,一个日志为相同大小的一组分段文件。每次生产者发布消息到一个分区,代理就将消息追加到最后一个段文件中。当发布的消息数量达到设定值或者经过一定的时间后,段文件真正写入磁盘中。写入完成后,消息公开给消费者。
与传统的消息系统不同,Kafka系统中存储的消息没有明确的消息Id。
消费者始终从特定分区顺序地获取消息,如果消费者知道特定消息的偏移量,也就说明消费者已经消费了之前的所有消息。消费者向代理发出异步拉请求,准备字节缓冲区用于消费。每个异步拉请求都包含要消费的消息偏移量。Kafka利用sendfile API高效地从代理的日志段文件中分发字节给消费者。
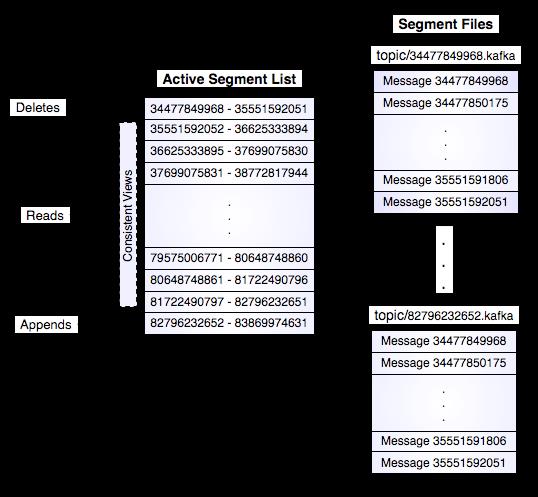
图3:Kafka存储架构
Kafka代理
与其它消息系统不同,Kafka代理是无状态的。这意味着消费者必须维护已消费的状态信息。这些信息由消费者自己维护,代理完全不管。这种设计非常微妙,它本身包含了创新。
从代理删除消息变得很棘手,因为代理并不知道消费者是否已经使用了该消息。Kafka创新性地解决了这个问题,它将一个简单的基于时间的SLA应用于保留策略。当消息在代理中超过一定时间后,将会被自动删除。
这种创新设计有很大的好处,消费者可以故意倒回到老的偏移量再次消费数据。这违反了队列的常见约定,但被证明是许多消费者的基本特征。
ZooKeeper与Kafka
考虑一下有多个服务器的分布式系统,每台服务器都负责保存数据,在数据上执行操作。这样的潜在例子包括分布式搜索引擎、分布式构建系统或者已知的系统如Apache Hadoop。所有这些分布式系统的一个常见问题是,你如何在任一时间点确定哪些服务器活着并且在工作中。最重要的是,当面对这些分布式计算的难题,例如网络失败、带宽限制、可变延迟连接、安全问题以及任何网络环境,甚至跨多个数据中心时可能发生的错误时,你如何可靠地做这些事。这些正是Apache ZooKeeper所关注的问题,它是一个快速、高可用、容错、分布式的协调服务。你可以使用ZooKeeper构建可靠的、分布式的数据结构,用于群组成员、领导人选举、协同工作流和配置服务,以及广义的分布式数据结构如锁、队列、屏障(Barrier)和锁存器(Latch)。许多知名且成功的项目依赖于ZooKeeper,其中包括HBase、Hadoop 2.0、Solr Cloud、Neo4J、Apache Blur(Incubating)和Accumulo。
ZooKeeper是一个分布式的、分层级的文件系统,能促进客户端间的松耦合,并提供最终一致的,类似于传统文件系统中文件和目录的Znode视图。它提供了基本的操作,例如创建、删除和检查Znode是否存在。它提供了事件驱动模型,客户端能观察特定Znode的变化,例如现有Znode增加了一个新的子节点。ZooKeeper运行多个ZooKeeper服务器,称为Ensemble,以获得高可用性。每个服务器都持有分布式文件系统的内存复本,为客户端的读取请求提供服务。
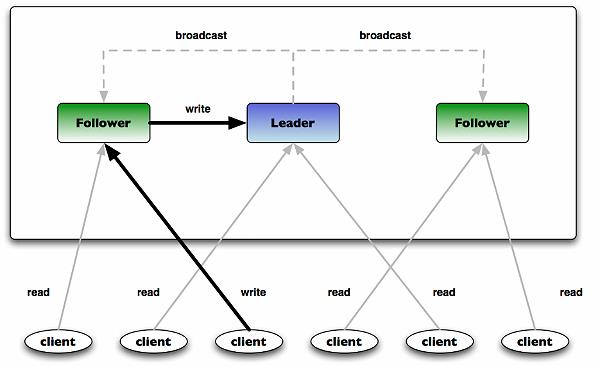
图4:ZooKeeper Ensemble架构
上图4展示了典型的ZooKeeper ensemble,一台服务器作为Leader,其它作为Follower。当Ensemble启动时,先选出Leader,然后所有Follower复制Leader的状态。所有写请求都通过Leader路由,变更会广播给所有Follower。变更广播被称为原子广播。
Kafka中ZooKeeper的用途:正如ZooKeeper用于分布式系统的协调和促进,Kafka使用ZooKeeper也是基于相同的原因。ZooKeeper用于管理、协调Kafka代理。每个Kafka代理都通过ZooKeeper协调其它Kafka代理。当Kafka系统中新增了代理或者某个代理故障失效时,ZooKeeper服务将通知生产者和消费者。生产者和消费者据此开始与其它代理协调工作。Kafka整体系统架构如图5所示。
图5:Kafka分布式系统的总体架构
随后本文又将Apache Kafka和其它消息服务进行了对比,并给出了一个示例应用。更多精彩内容,请点击“阅读原文”。
以上是关于实战Apache Kafka:下一代分布式消息系统的主要内容,如果未能解决你的问题,请参考以下文章