弹性集成Apache Mesos与Apache Kafka框架
Posted 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了弹性集成Apache Mesos与Apache Kafka框架相关的知识,希望对你有一定的参考价值。
Kafka和Mesos是非常知名和成功的Apache项目,它们每个都获得了大型社区的支持,还有Confluent和Mesosphere这样的公司各自围着它们构筑生态系统。最近,两家公司合作使Kafka成为Mesosphere数据中心处理系统(DCOS)的首批认证服务。
流数据无处不在并持续增长——监控公司IT基础设施的应用程序产生的指标数据流、零售行业订单和物流产生的数据流、物流网设备产生的活动数据流、金融公司的股票行情自动收录器产生的数据流等等。这些越来越需要可以大规模实时处理所有这些流数据的基础设施平台并使其可用于公司数据中心里的各种应用程序。
鉴于Kafka独特的实时移动大量数据的能力,使得它特别适合管理流数据,许多组织使用Kafka增强实时数据监测、分析、安全、欺诈检测和流处理能力。Kafka在公司的数据中心集成各种系统时也起着关键作用。Apache Mesos抽象了数据中心资源,从而使其易于部署和管理分布式应用程序和系统。这篇文章介绍了如何在Mesos上运行Kafka集群来简化管理大规模流数据的任务。
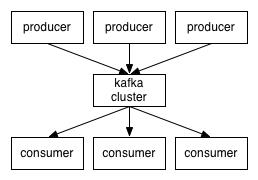
Kafka是一个分布式、高吞吐量、低延迟的发布-订阅类型的消息系统。自从2011年开源以来,Kafka已经在业内得到了广泛采用,比如在LinkedIn、Netflix、Uber这样的互联网公司还有像Cisco和高盛这样的传统行业公司。在这些公司中Kafka被用来构筑关键数据的主干管道,每天实时移动的消息有数千亿条之多。
Apache Mesos是一个集群管理平台,可以对分布式应用程序或者框架提供高效的资源隔离和共享功能,它位于应用程序层和操作系统之间,使得其易于在大规模集群环境中有效部署和管理各种应用。
下图是Mesos架构的快速概述,其由Masters、Slaves和框架组成。
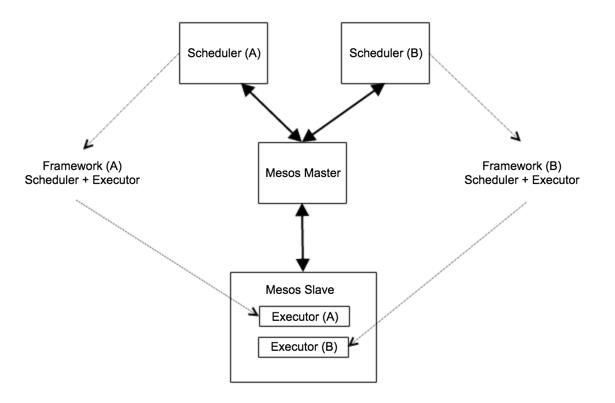
Mesos Master负责处理Slave节点和框架间的资源通讯,在任何情况下都只能有一个Master作为领导在运行,在Master崩溃的情况下通常至少有一个备用机制来处理故障转移(在代理模式下备用机制就是把数据传输到Master上)。Master负责为任务分配资源(在调度器和Slave节点之间),管理状态还有维持高可用等等。
Mesos Slave在其服务运行节点启动本地进程,这些进程是由执行器在Linux容器中启动的,Linux容器是这些进程的父容器,除了容器自身的进程之外。
框架接收来自Master提供的Slave节点的资源(比如CPU和内存),框架由以下两个部分组成:
调度器
调度器提供了如何管理框架内任务做什么的基础功能,其负责管理Slave节点运行成功和失败间的状态、任务失败、内部应用程序配置和故障、对外通讯等等。执行器
执行器在服务器上执行应用程序代码,在容器内部其他的进程也可以同样启动,这取决于应用程序本身的配置。通常情况下,执行器在服务器上运行的业务逻辑代码可以通过“Thin Lay”与Master交互。
读者可以在这儿(http://mesos.apache.org/documentation/latest/mesos-architecture/)阅读到更多的有关Mesos架构方面的信息。
Marathon是一个Mesos框架,便于启动任何可长时间运行的应用程序,从而不需要为特定的应用定制开发框架。Marathon自动提供了很多在集群环境中运行应用需要的特性,比如高可用性、节点约束、应用健康检查、脚本语言API和服务发现、一个易于使用的Web用户界面。
然而Marathon框架的简洁也带来了在伸缩性和定制化方面的损失,应用程序没有规定应该如何按照一定的约束来分配资源,例如数据保护或数据关联性分析。
首先,我们开始在Marathon上运行Kafka,但实际上我们将会遇到了如下一系列问题。
第一,Marathon不是为了管理有状态服务而设计的,在有失败发生或者一个简单的服务重启的场景下,Marathon会随机的在任何符合服务定义约束的资源上重启服务,这样对于有状态服务是不适合的,因为这样的话需要很高的操作代价来将本地状态迁移到新的服务上。Kafka类似于其它各种存储系统一样都需要在本地磁盘上维护它自己的数据。
在Marathon上运行Kafka意味着在Kafka Broker上的一个简单的重启操作将会迁移每个Broker到不同的服务器上,使得Broker需要从剩余的Broker复制所有它自己的数据。因为通常Kafka存储了大量的数据,这可能意味着会产生不必要的TB级数据的复制操作。用户希望如果一个Broker发生了重启,Kafka Broker集群可以等待直至重启操作完成,如果发生了严重的错误,仍然可以移走该Broker。
第二,Marathon不允许用户选择性地对从属于这些进程子集的应用状态进行负载均衡。在Kafka上,可以进行集群扩展,用户可以选择性地从剩余的集群节点迁移一些分区数据到最新重启的Broker上。目前的Kafka集群扩展操作还得通过管理界面手动进行。
在集群中启动新的Broker不会分配任何数据,用户必须选择性地从剩余的集群节点迁移一些分区数据到新启动的Broker上,同时Kafka不支持限额,所以迁移分区数据的操作必须仔细地分阶段完成,避免网络饱和和Kafka集群内部的复制流量。Marathon没有提供钩子来允许应用程序执行特定的业务逻辑来进行故障检测以及处出来流程。
鉴于如上提到的这些缺点,我们决定寻求将Kafka和Mesos集成在一起的框架方法。
下图是Kafka Mesos框架的各种组件工作流程图:
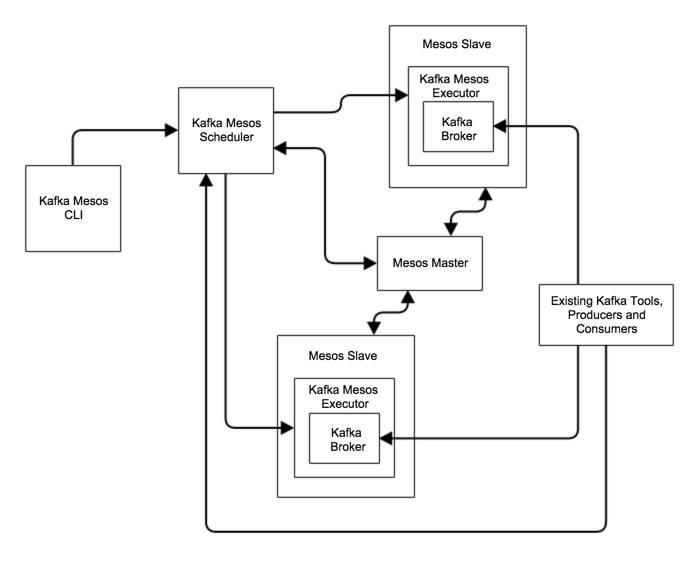
调度器为Kafka集群提供了操作自动化功能,任何版本的Kafka都可以通过调度器运行在Mesos上,由调度器决定任务是否失败、是否需要管理和集群伸缩,调取器的状态由ZooKeeper来维护,同时可以通过Restful API来进行配置和其它任务管理。
调度器在Marathon上运行,这样如果调度器进程被杀死,Marathon可以在另外一个Mesos Slave节点上启动新的调度器。
执行器作为调度器的中间人与Kafka Broker集群交互,执行器寻找Kafka的二进制发行tgz压缩包,然后执行相关的代码,这样就不仅允许用户运行不同版本的Kafka,还可以给Kafka打补丁,然后通过已配置的自动化部署平台运行模拟测试。
如果你想亲自动手,这里是Kafka Mesos框架的快速入门:
打开两个终端窗口,进入从git clone的目录后检查kafka-mesos.proterties文件,确保调度器已经配置在你的集群上。
在第一个终端窗口运行:
git clone https://github.com/mesos/kafka mesosKafka cd mesosKafka ./gradlew jar ./kafka-mesos.sh scheduler
在第二个终端窗口运行:
./kafka-mesos.sh add 1000..1002 --cpus 0.01 --heap 128 --mem 256 ./kafka-mesos.sh start 1000..1002 ./kafka-mesos.sh status
到了这一步你就会有三个Kafka Broker在运行了,更多的命令如下:
./kafka-mesos.sh help You can also get help for each command ./kafka-mesos.sh help <cmd>
除了CLI命令行方式外,Kafka Mesos框架调度器还提供了Restful API来进行管理配置。
为了获知Mesos Kafka调度器运行在哪台机器上,用户需要查询如下的Marathon API接口:
curl -X GET -H "Content-type: application/json" -H "Accept: application/json" http://localhost:8080/v2/tasks
Restful API提供了与CLI命令行方式相同的所有特性,呈现为如下的格式:
/api/brokers/<cli command>/id={broker.id}&<k>=<v>
添加一个Broker:
“http://localhost:7000/api/brokers/add?id=0&cpus=8&mem=43008"
启动Broker:
“http://localhost:7000/api/brokers/start?id=0"
查询Broker的运行状态:
curl "http://localhost:7000/api/brokers/status"
已有的Kafka工具、消息生产者和消费者都可以工作在Kafka Mesos框架上,工作方式跟之前没有运行在Mesos上一样,用户可以通过CLI或者Restful API发现其它Kafka Broker。
Kafka Mesos框架和DCOS前途无量,我们获得了很多关于接下来如何以及继续发展的反馈和想法。这儿有一些目前正在讨论的如何改进集成的特性,不过没有按照一定的顺序罗列,其中的大部分特性我们正在将其添加到Apache Kafka项目中:
继续支持新的Kafka和Mesos特性,修正bug。
将Kafka命令(比如kafka-topic等)集成到框架调度器中,这样可以通过CLI或者Restful API来使用。
支持集群的自动伸缩(包括自动重新分配Kafka分区),这样可以在已知的流量低谷期之外充分利用Broker的资源(CPU、内存等等)。
机架感知分区,改善容错能力。
提供钩子程序这样消息生产者和消费者也可以从调度器启动,并通过集群管理。
按照负载和流量自动重新分区。
在接下来的时间里,很多公司都期待着为它们增长的数据做更多的工作。单一整体集中式部署数据库的时代一去不复返了,现在很多公司正在扩展新的专业分布式系统来处理海量数据,但是它们迫切需要减少部署和管理硬件资源工作的复杂度,从而避免沦为IT基础设施的奴隶的风险。不仅Kafka会成为公司数据管道设施的核心,使得数据可以流向多种多样的系统,而且由于像Kafka这样的大数据技术将会继续迅猛发展,所以像Mesos这样的集群管理系统也会日益重要。
DockOne,新圈子,新思路,新视野。
以上是关于弹性集成Apache Mesos与Apache Kafka框架的主要内容,如果未能解决你的问题,请参考以下文章