Kafka消息存储机制探索
Posted 京东成都研究院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka消息存储机制探索相关的知识,希望对你有一定的参考价值。
Apache Kafka是由Apache软件基金会开发的一个开源消息中间件项目,由Scala写成。Kafka最初是由LinkedIn开发,并于2011年初开源。该项目是为处理实时数据提供一个统一、高吞吐、低延迟的平台。
整体架构
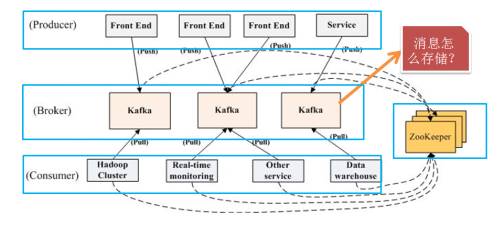
其中:Producer:生产者;Broker:kafka的服务器;Consumer:消费者;Zookeeper:对整个Producer、Broker、Consumer进行协调。
Kafka主要应用于大数据量实时传输场景、日志系统。但是,它和jmq的使用场景有所不同,jmq擅长业务系统,主要包含业务系统解耦和数据同步。
优势
• 高吞吐、高性能
• 分布式设计、可扩展性好
• 高容量
• 读写负载均衡
劣势
• 业务重要流程
总结
• 消息队列(MQ)
• 分布式日志系统(Log)
• 数据通道(Messaging)

Consumer Group( 消费组 ):在kafka中,所有的消费者都属于一个消费组
Topic(消息类型):Topic就是对消息进行逻辑上的分类
Partition(分区):消息的分区,kafka中对消息进行分区管理
Replica(副本):Partition的副本,主要是从服务的容灾上进行备份
Replica Leader(副本-主):Partition分区的leader
Replica Follower(副本-从):Partition分区的Follower
Segment(段文件):Topic消息的文件组成
Offset(偏移量):消息存储的偏移量,在kafka中生产者和消费者主要就是依靠Offset进行控制消息的发送和消费
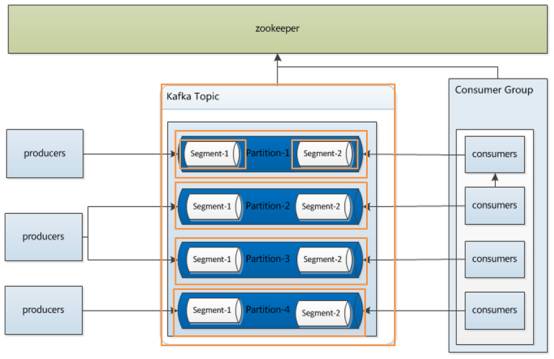 先从整体流程了解一下kafka消息的结构,从大到小:
先从整体流程了解一下kafka消息的结构,从大到小:
Topic>>partition>>segment>>index/log
整个的消息结构关系,如图所示:
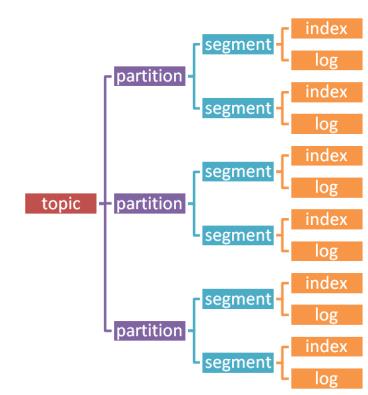
一个topic可以被拆分为多个partition进行存储,每个partition还有自己的副本,作为容灾准备;每个partition是由segment文件进行组成;每个segment文件又两类文件组成,一类是index索引文件,主要是存储数据和位置的关系;一类是log文件,主要存储的是数据文件。
At-most-once: 最多一次,这个和JMS中”非持久化”消息类似,发送一次,无论成败,将不会重发。
At-least-once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。
Exactly-once: 消息只会发送一次。
Kafka采取的传送机制为At-least-once,即至少发送一次,来保证数据的完整性。
在kafka中,topic只是一个逻辑概念,是producer与consumer之间交换的桥梁,与消息本身的存储broker没有关系。同时,在kafka中,对各个topic消息采取的独立分区分布式存储的方式,能够利用分布式,极大地增强传输效率。
Partition的引入能够有效解决水平扩展问题。其命名规则为topic名称+有序序号,第一个partition序号从0开始,序号最大值为partitions数量减1,运用时参数配置。
num.partitions:主要用于配置消息的分区参数。
default.replication.factor:主要用于配置副本数量。
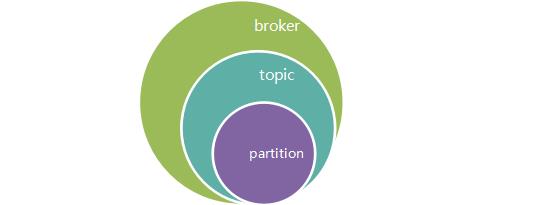
在broker中,topic与partition关系如图所示:
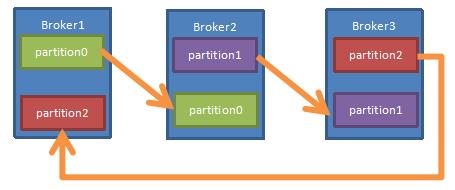
 下面以一个Kafka集群中3个Broker举例,创建1个topic包含3个Partition分区,3个Replication副本;数据Producer流动如图所示:
下面以一个Kafka集群中3个Broker举例,创建1个topic包含3个Partition分区,3个Replication副本;数据Producer流动如图所示:
当集群中新增到5节点时,分区和副本重排,分布情况如下:
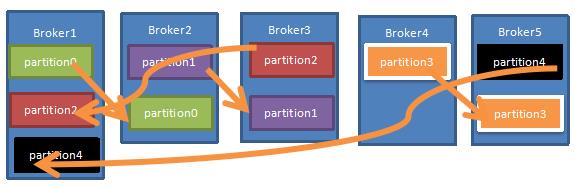
实现上述分区,副本重排的具体算法如下:
1. 将所有N个Broker和待分配的i个Partition排序。
2. 将第i个Partition分配到第(i mod n)个Broker上。
3. 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上。
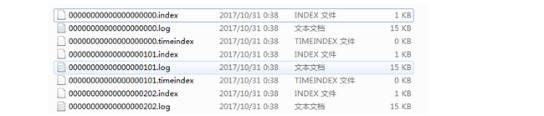
每个Partition由多个Segment段文件组成,每个Segment文件通过log.segment.bytes配置其大小限制。每个段文件由2部分组成,分别是index索引文件和log数据文件。如图是段文件在系统中的存储形式:
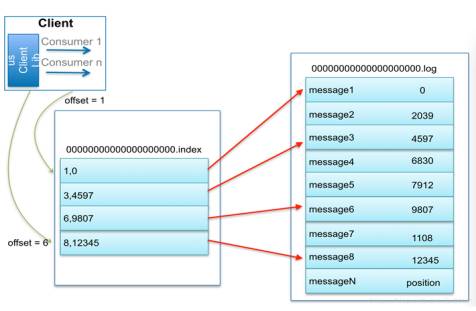
Kafka定位具体message是通过index索引文件和log数据文件共同决定的。例如:当查找绝对offset为7的Message时
1. 通过二分查找确定它是在哪个LogSegment中。此时为第一个Segment中。
2. 打开这个Segment的index文件,再通过用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset,此时基于offset为7,定位到offset为6的索引,通过索引文件得到offset为6的Message在log数据文件中的位置为9807。
3. 打开数据文件,从位置为9807开始顺序扫描直到找到offset为7的那条Message,即定位成功。
这套机制是建立在offset是有序的前提下,索引文件被映射到内存中,故极大地提升了查询速度。
Kafka中消息物理结构如图所示:

Kafka目前存在的消费策略有“rang”、“round-robin”两种分配方式。
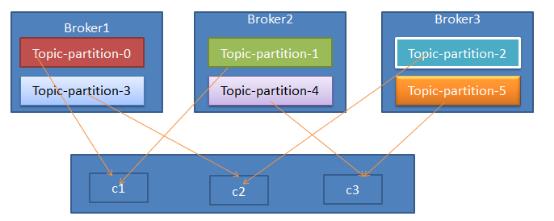
Range分配器是基于topic的。对于每个topic,以数字顺序列出所有partitions,以词典序列列出所有consumer线程,将partitions数除consumer线程数,来决定分给每个consumer多少partition。分配不均匀,前几个consumers会多分1个partition,如图所示:
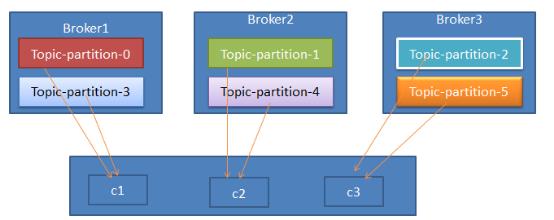
Partition分配器列出所有可用partitions和所有可用consumer线程。Round-robin的方式将partition分配给consumer线程。如果所有consumer的订阅是相同的,那么patitions会被均匀分配,所有consumer线程占有的partition数量相差不会超过1,如图所示:
然而,在使用kafka时,需要评估具体场景是否适合使用。目前kafka缺少良好可控的后台管理,可以进行消费监控、管理,异常处理等功能,由雅虎开源的“kafka-manager”能实现部分功能。
以上是关于Kafka消息存储机制探索的主要内容,如果未能解决你的问题,请参考以下文章