Kafka分布式消息系统剖析
Posted 大数据架构之旅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka分布式消息系统剖析相关的知识,希望对你有一定的参考价值。
作为优秀的分布式消息中间件系统,主要构成为生产者,消费者和服务端,一般系统会有消费者,生产者,代理层,服务端,kafka进行了概念和架构上的精简,消费者和生产者同为客户端,服务端没有代理层进行代理收发消息
每个服务器充当一个代理,客户端进行生产和消费数据活动,消息以主题的形式存在,每个主题在服务端存储为多个分片,不同的分片在集群中的各自服务器上服务器的元数据保存在ZK中,并通过zk实现服务器的集群管理和扩展。
下面对kafka系统中的核心模块和功能进行详细的阐述
1,生产者
客户端生产数据需要指定数据对应的Topic,Partition和Key。主题和分区可以确定消息发送到哪一台台服务器的哪个分区,如果没有指定分区则根据Key进行语义解析保证同一个Key会被存储在同一个服务器的同一个分区上,对于客户端产生的数据Key并非必须要指定,如果没有指定客户端则根据Topic找到该主题下所有的分区服务器列表进行随机存储,代价会相对大些。
生产者的客户端核心类为KafkaProducer该类对应的发送数据方法为sender,该功能并不是直接发送到服务端的方法,只会把数据放入到客户端队列中,该队列的实现为RecordAccumulator,客户端线程会对该队列进行监听,根据指定时间和指定大小进行数据的发送,该队列根据不同的分区维护不同的队列,每次发送一批数据,而不是每生产一个消息就去触发一次网络请求,这样能提高网络的吞吐量,数据交互的类为NetworkClient,该类底层使用的通信方式为JAVA NIO,客户端维护一个线程同多个服务端相连接,节省资源的同时提高了连接效率,这里简单阐述下JAVA NIO概念:Channel为消息管道,可以对它进行读写操作,Selector为选择器,SelectionKey为键对象,通过键对象Selector可以注册到感兴趣的事件到Channel中进而实现对管道的操作和管理
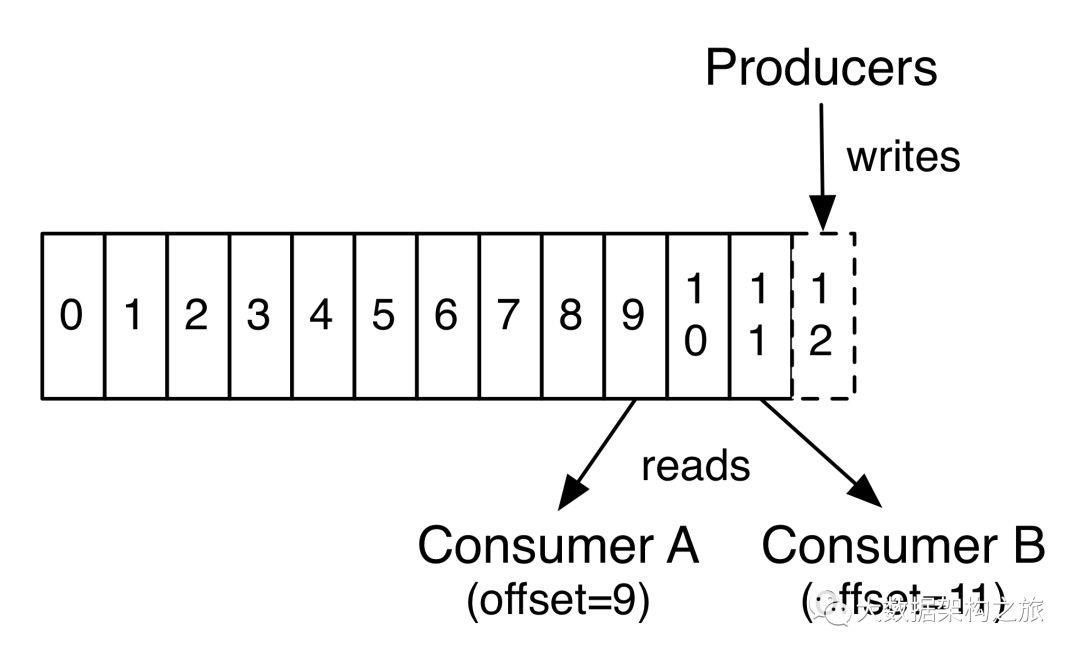
2,消费者
消息队列存在两种消费方式,一是点对点模式,一种是订阅模式
Kafka使用了比较巧妙的消费组的概念实现两种模式的轻量级切换,消息消费以消费群的方式进行数据拉取,一个消费群可以有多个消费者,但是一个主题对应的分区同时只能有一个消费者。如果有几个消费者,每个都有自己的消费组名称,则消息会被所有的消费者共同消费即所谓的一对多订阅模式,即可以重复消费。如果每个消费者的消费组都相等则同一条消息只能被其中一个消费者消费,不可以重复消费。
消费消息有常见的两种方式
一是推送方式:存在一个消息代理机制,在数据到达后把消息推到对应的消费者面前,存在一个问题即无法跟踪消息的消费情况。
另一种方式为消息的拉取方式,也是kafka采用的方式,客户端自己读取队列并维护读取偏移量,并可以再次读取,再次读取场景使用的比较少,一般在数据恢复时候使用
3,数据持久化
消息的存储和系统的架构设计息息相关,一个Topic会被分割成一系列的Log,叫做Partition分区,数据就是以Log的形式持久化在硬盘上,同一个Partition的数据以追加的方式存储,保证了生产和消费的顺序,集群环境下副本机器也同步进行了数据的保存。
这种设计最大程度的保证了数据的安全性,同时在性能上做了如下的优化:
一是数据的持久化进行了数据的集中存储,即多个数据写入变成合并后一次写入,这个更多的依赖底层系统的处理性能。
二是数据的读取方面,正常的消费者数据读需要硬盘数据读入到核心缓冲区再从核心缓冲区读入数据到用户缓冲区,然后用户缓冲区读入数据到Socket缓冲区,Socket缓冲区传送到网卡接口送给消费者,一个数据读取历经太多的Copy流程,在大数据高并发消费场景下性能尚有优化空间:Kafka采用零拷贝方式读取数据,即硬盘数据从内核缓冲区直接到网卡接口,省去了用户内存和Socket缓冲区的Copy步骤
4,协调者
Kafka服务的大量元数据信息保存在ZK目录中,如Controller的注册信息,分区,主题以及之前Consumer的注册协调信息,使用了ZK的选取机制以及注册了很多的Watch监听事件,如分区改变,主题改变,代理节点改变监听等
消费组老的API(0.9之后引入新消费者API)使用的ZK作为协调者管理消费组,新版放弃了ZK,选择一个Broker节点作为协调者,负责管理消费组的状态。
以上是关于Kafka分布式消息系统剖析的主要内容,如果未能解决你的问题,请参考以下文章