kafka系列:Kafka设计与应用
Posted Hadoop技术学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka系列:Kafka设计与应用相关的知识,希望对你有一定的参考价值。
kafka在消息的吞吐上还是有明显的优势;非常适合一些数据集成和交换的场景;社区后续会发一系列kafka的文章,供大家参考学习,希望大家喜欢。
Kafka是LinkedIn在2010年开发的分布式消息系统• 使用于LinkedIn的活动流和运营数据处理的管道
• 使用Scala&Java语言编写
• 并于2011年成为Apache的开源项目
• 具有分布式/高性能/高吞吐/水平扩展等特性• 支持发布/订阅&点对点模式的分布式消息系统
• 0.9之后支持StreamsAPI
• 支持主流编程语言的API调用[C++/Python/Go/Ruby/php/…]
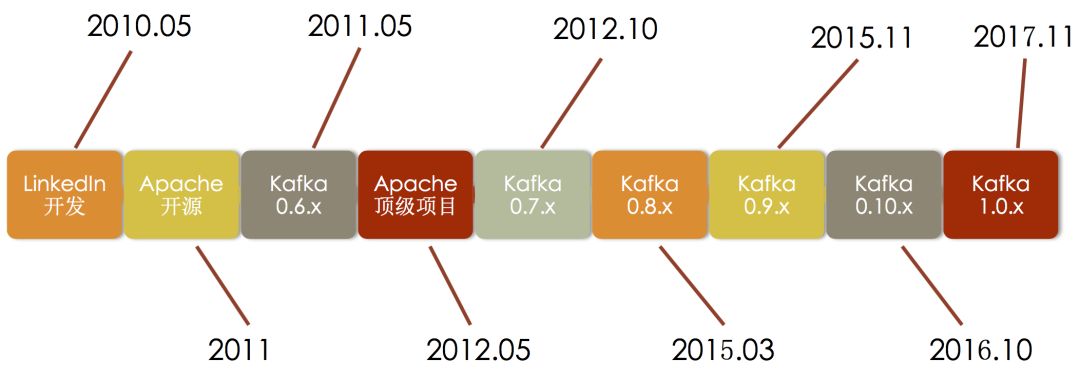
Kafka版本演进(一)
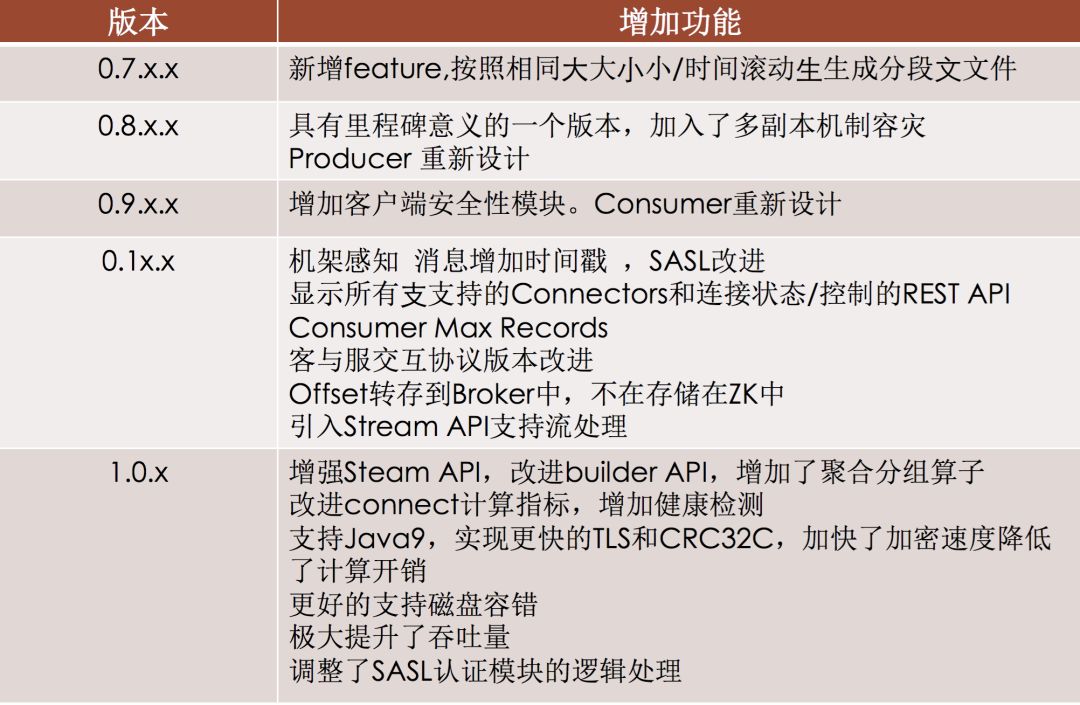
kafka版本演进(二)
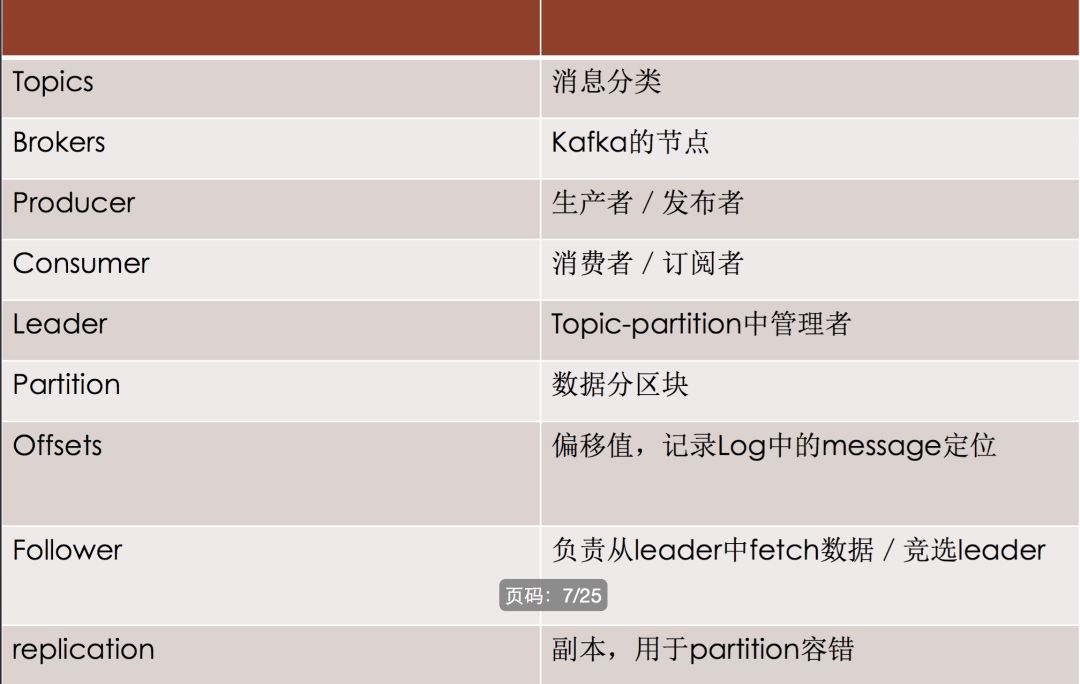
Kafka基础概念

分布式/可分区,具有消息复制和容错系统 [可靠性]
- 可以水平扩展,对不同Topic的不同处理 [扩展性]
- 发送和消息具有高吞吐量,压测最低10w/s主要瓶颈在网络IO[高性能]
- 支持批量消费,批量提交offset,快速落盘 [高可用性]
监控系统
处理可监控的数据,可实时进行消息的处理计算
日志处理
Application 批量,异步发送日志/行为数据
流式处理
可以流式读取数据,支持Storm/Spark/Kafka Steaming
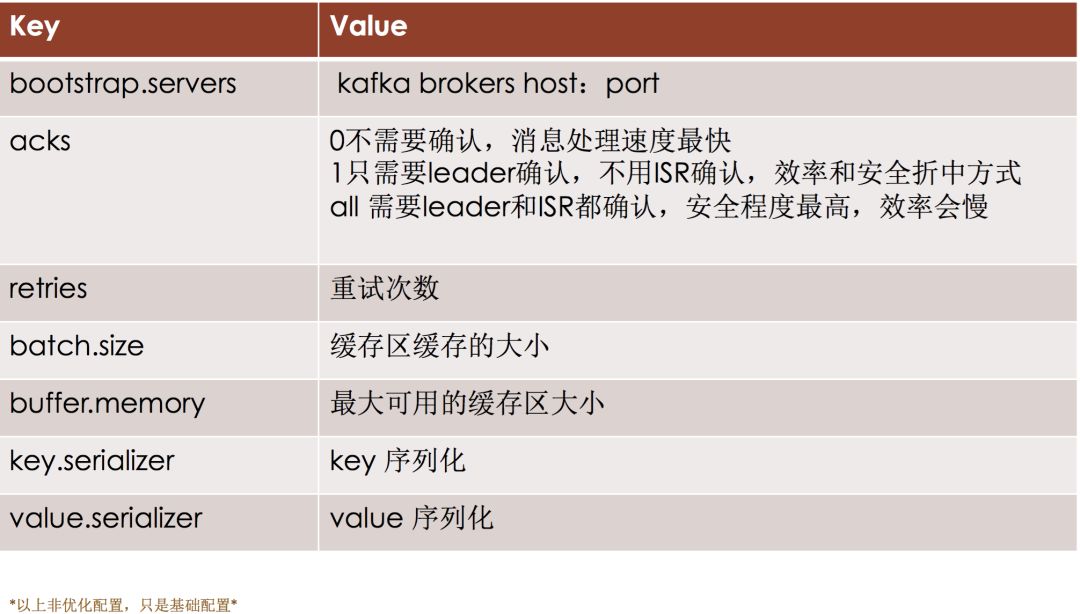
消息得生产实例&原理(一)
生产者-发送/发布消息的一端
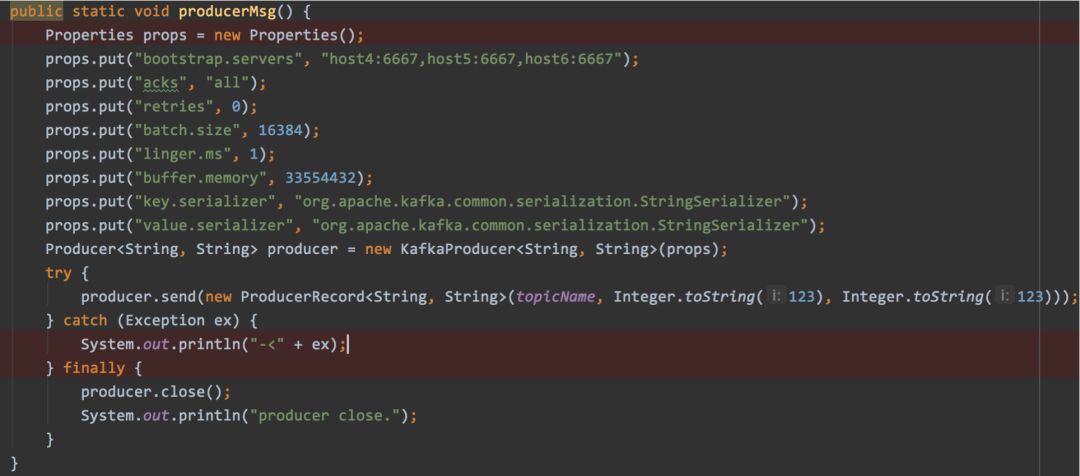
消息的生产&原理(二)
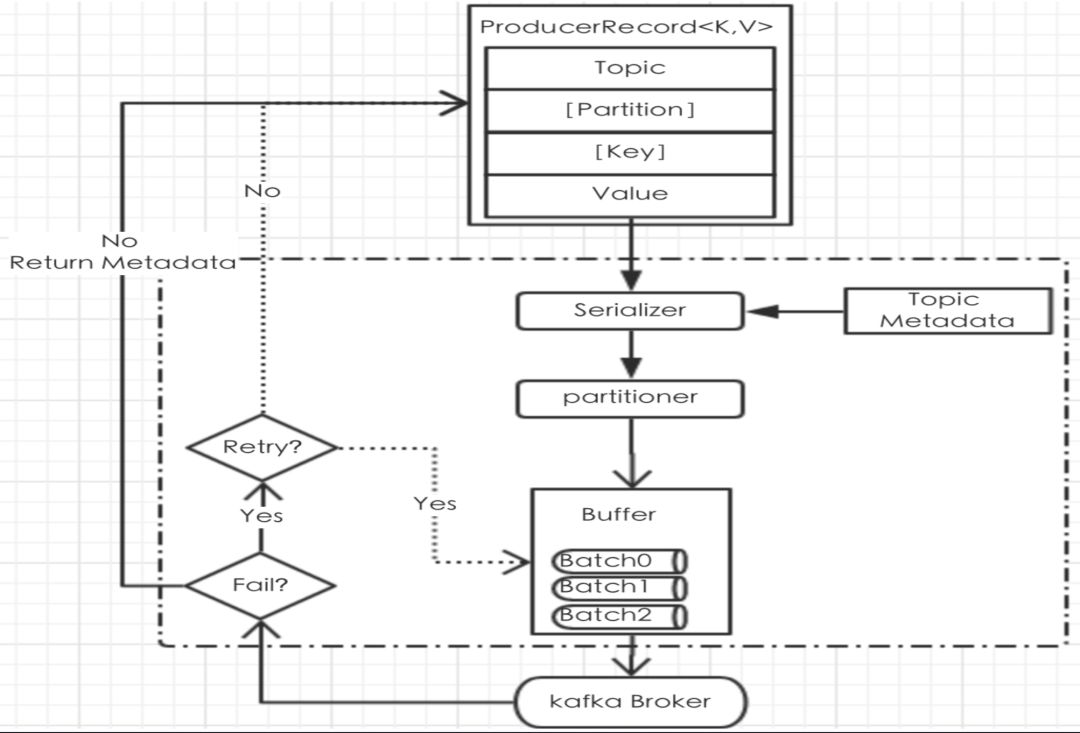
消息的生产&原理(三)
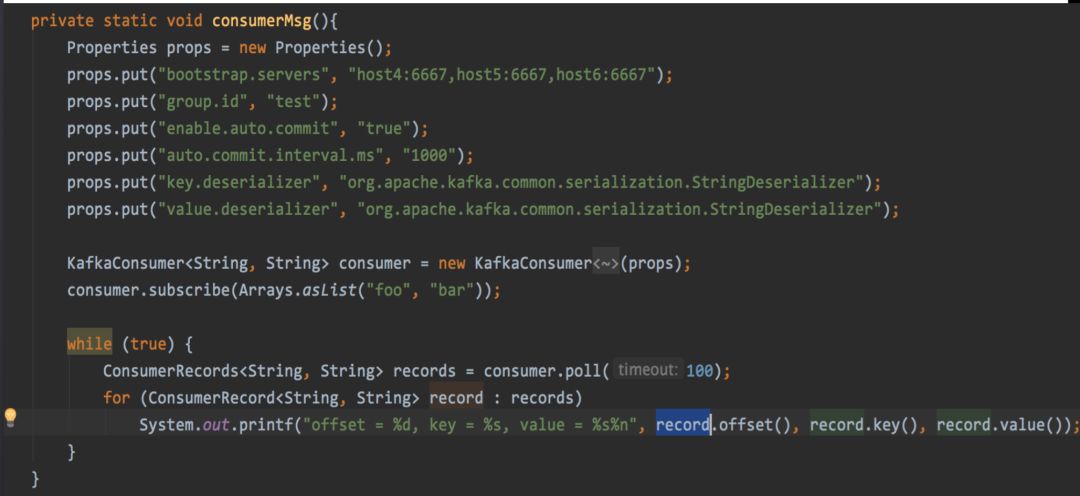
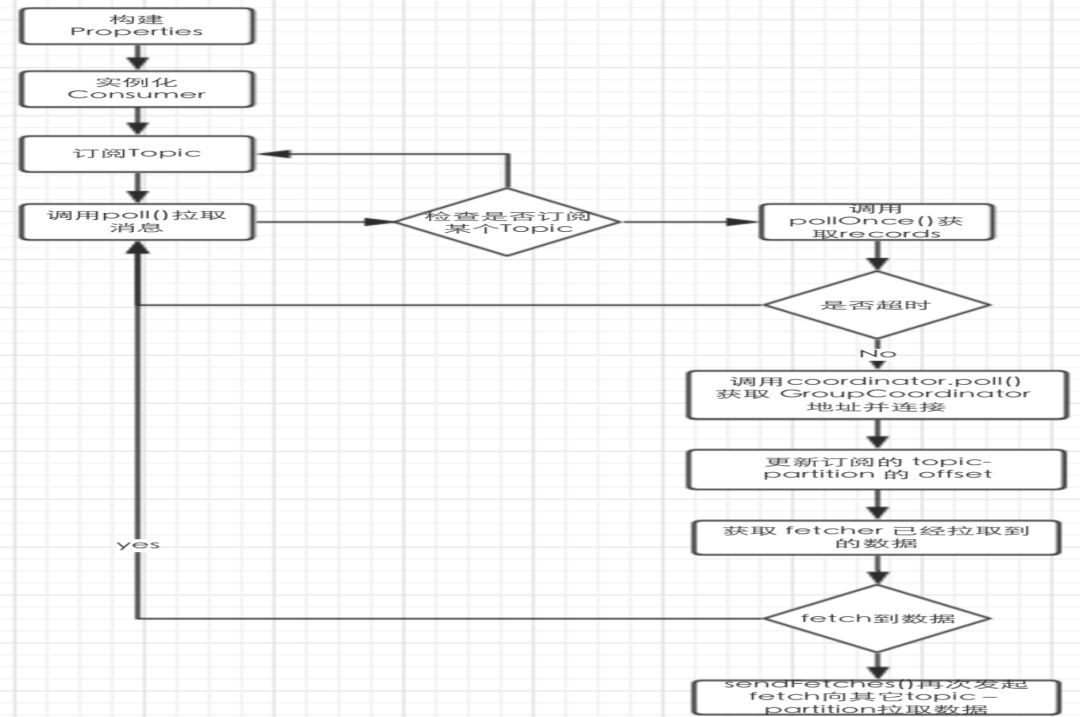
消息的消费实例&原理(一)
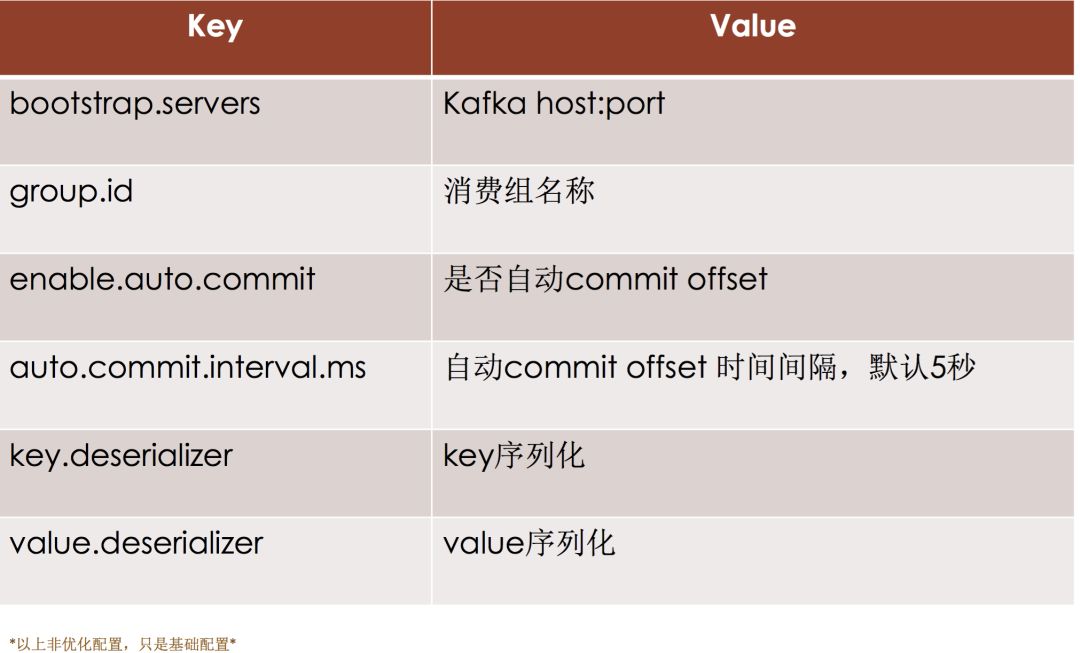
消息的消费实例&原理(二)
消费规则:
一个Partition只能被同一个ConsumerGroup的一个线程消费
线程数小于partition数,可能会消费多个Partition
同一个partition保证是有序消费的
0.9之前consumer依赖zk,0.9之后直接链接kafka的Coordinator
消息的消费&原理(三)
Kafka数据存储单元-Partition
一个Partition对应一个文件夹
Partition中分为多个Segment
Segment的命名为offset.logSegment对应一个ofset.Index文件[记录offset的磁盘位置]

数据存储示意图:
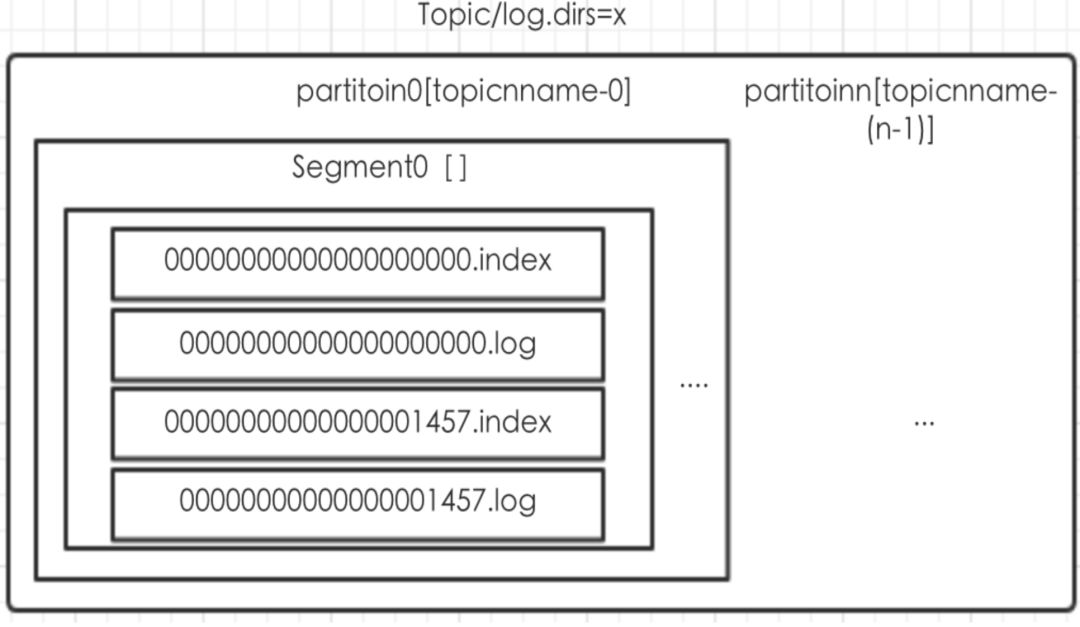
Segment file中index与log文件的对应关系图 [摘自网络]

Message物理结构图

At most once [最多一次]
At least once [至少一次]
Exacty once [正好一次]
Kafka 默认机制是 At least once ,用户可以选择处理一批数据之后批量提交offset来实现“Exacty once”
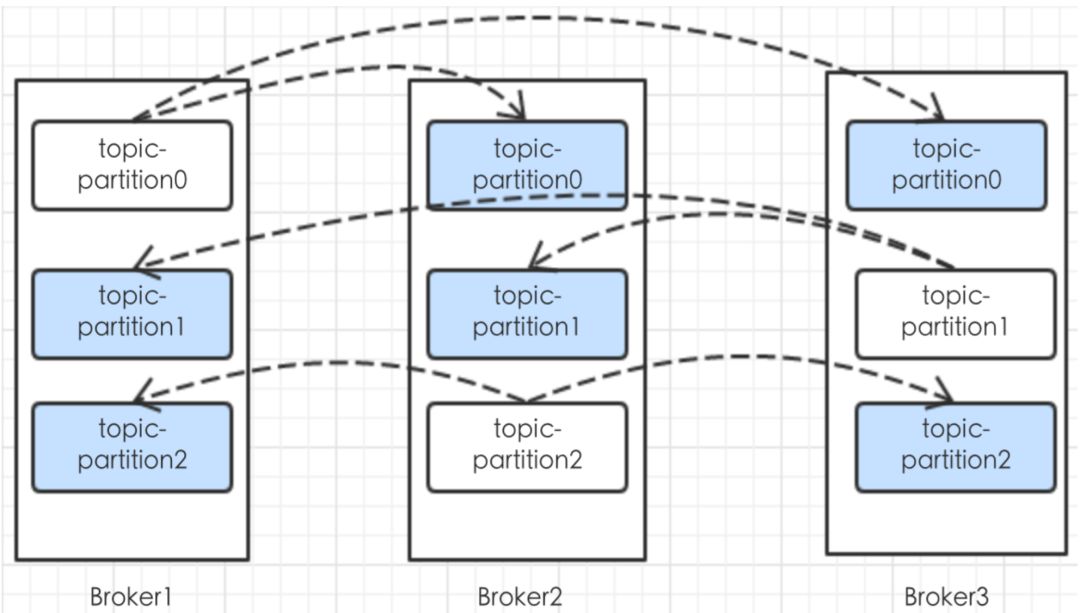
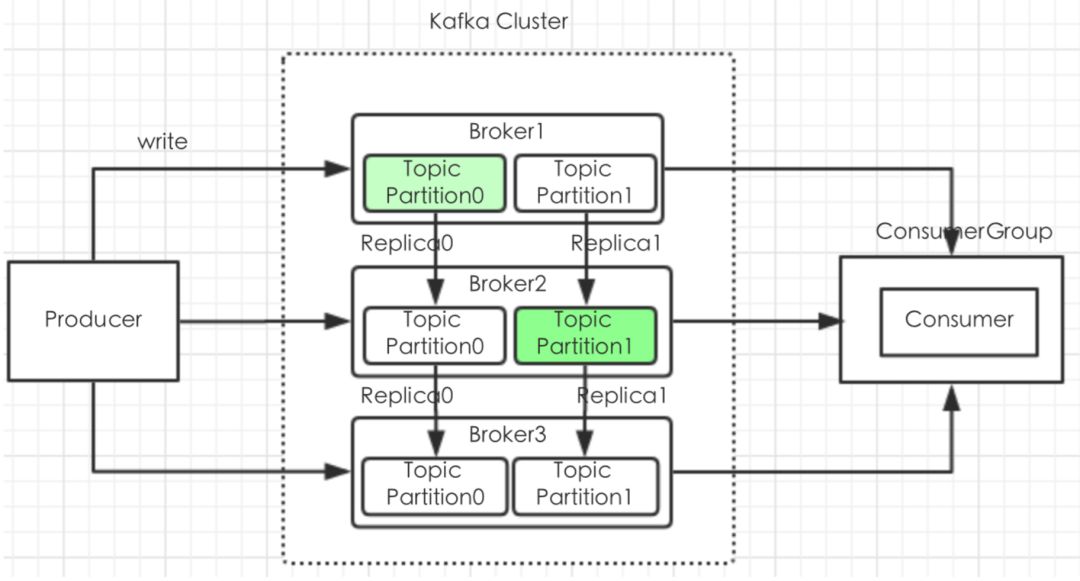
Kafka将每个Partition复制到多个Server上,每一个Partition都有一个leader和多个follower[多机备份]
当一个leader挂掉之后,通过选举选择follower中一个作为leader[去中心化]
ZK中通过ISR维护着所有Follower,Follower通过Tcp与ZK保持心跳
副本因子
猜你喜欢
加入技术讨论群
《大数据和云计算技术》社区群人数已经3000+,欢迎大家加下面助手微信,拉大家进群,自由交流。


欢迎大家通过二维码打赏支持技术社区(英雄请留名,社区感谢您,打赏次数超过88+):
以上是关于kafka系列:Kafka设计与应用的主要内容,如果未能解决你的问题,请参考以下文章